Level-up your Earnings with $SLC
In coordination with the @FoundationSLC, we are unlocking enhanced $SLC utility starting today.
SLC holders can now earn up to 100% more through Silencio Voice AI.
Live and available to all Silencio Voice AI users as of now.
What is it?
🔹Hold more $SLC → Move up levels
🔹Higher level → Higher % boost on your rewards
🔹Up to 100% boost at the highest level
Why this matters:
🔹Direct earning power tied to $SLC holdings
🔹Stronger flywheel between enterprise revenue, token burns, and contributor rewards
🔹A clear economic reason to hold $SLC on your wallet
Much more is coming to continue driving $SLC utility and placing the token at the absolute core of the Silencio ecosystem.
Every new dataset, every enterprise contract, every incentive layer will increasingly reinforce SLC as the coordination engine of the network.
We are building the world’s ears for AI and robotics.
Visit Voice AI today and start earning: https://t.co/SIJ8PYZ4XU
Silencio Voice AI is at Lisbon AI Summit 2026 tomorrow, Lisbon Congress Centre.
We're meeting AI builders across the day. Voice AI training data, multilingual coverage, where production voice products still miss whole languages.
If you're there, come find us. Send us a message to schedule.
The Silencio voice network, right now:
2,000,000+ contributors
180+ countries
150+ distinct languages
5,000+ hours of new audio added every day
What this scale buys, technically: enough variation in voices, accents, devices, and environments that a model trained on it generalises to the real world, not to a studio. Models trained on 50 voices fail outside the lab. Models trained on a million voices don't.
Every recording adds one more degree of "the model has heard someone like this before."
Long before voice AI existed, linguists spent years in the field with tape recorders, capturing how a language is actually spoken before the last fluent speakers passed away. Some of the most important archives of human language (Maori, Welsh, Sami, Cherokee, hundreds of others) exist because someone did exactly that, often at the last possible moment.
Silencio, in 2026, is operating something close to that on global scale. Every recording in a low-resource language is also a permanent, dated, metadata-labelled record of how that language sounded at this point in time. The commercial use trains a model. The documentation use is a side-effect, and a side-effect that will outlast any single product.
If you record in a language that is rarely captured at scale, the second outcome is not theoretical. It's already happening.
#LanguagePreservation
Join us tomorrow at 16:00 CET as we give Silencians a community update and answer your questions.
Looking forward to seeing you there!
https://t.co/ggQuHltcQP
The final 4 words are in.
(Same Procedure as every month)
Each vote count is turned into a number and combined into one string and hashed with SHA-256 to generate a provably random seed. That seed selects the winners.
Vote now ⬇️
Payouts are live and continuing as clients keep purchasing your voice data.
Have you checked out the Payouts section in Voice AI yet?
It’s the easiest way to track your earnings in real time and stay fully in the loop.👉
https://t.co/YyGpZTB8OB
Contributions are powering the next generation of AI
Marketing Communication
🤫 The Alpha Burn Program continues.
In May, 25,548,045 SLC were permanently removed from circulation through the Alpha Burn mechanism.
All burns are executed transparently and are verifiable on-chain:
https://t.co/fTxNSLa2Ik
Imagine a future where you cannot communicate…
and you are always misunderstood.
AI that hears your voice but gets your accent wrong.
Voice assistants that fail in your dialect.
Robots that can’t navigate the sounds of your world.
7,000 languages reduced to just a handful.
That’s a world without Silencio.
GIF: iykyk
Us when we close another deal with an AI lab 🔥
Your contributions matter. You are helping AI models understand and speak languages around the world. This data didn't exist previously, and we feel pretty excited about where Silencio is heading.
We are working full throttle to unlock massive value in the coming weeks.
Always be building & shipping. Easy.
Stay tuned.
Last week @OpenAI released a major Voice AI update. The new GPT-Realtime-Translates: 70 input languages → 13 output languages.
The world speaks ~7,000.
The models are racing ahead. The data layer underneath them isn't.
This is exactly the gap @Silencio_Network is built to close, field-recorded, multilingual voice data from 2.5M contributors across 185+ countries.
You can't synthesize your way to authentic speech in Yoruba, Quechua, or Tagalog. You have to go collect it.
GPT-5-class reasoning is here. Now the question is what it gets to listen to.
Your timeline says AI is a bubble.
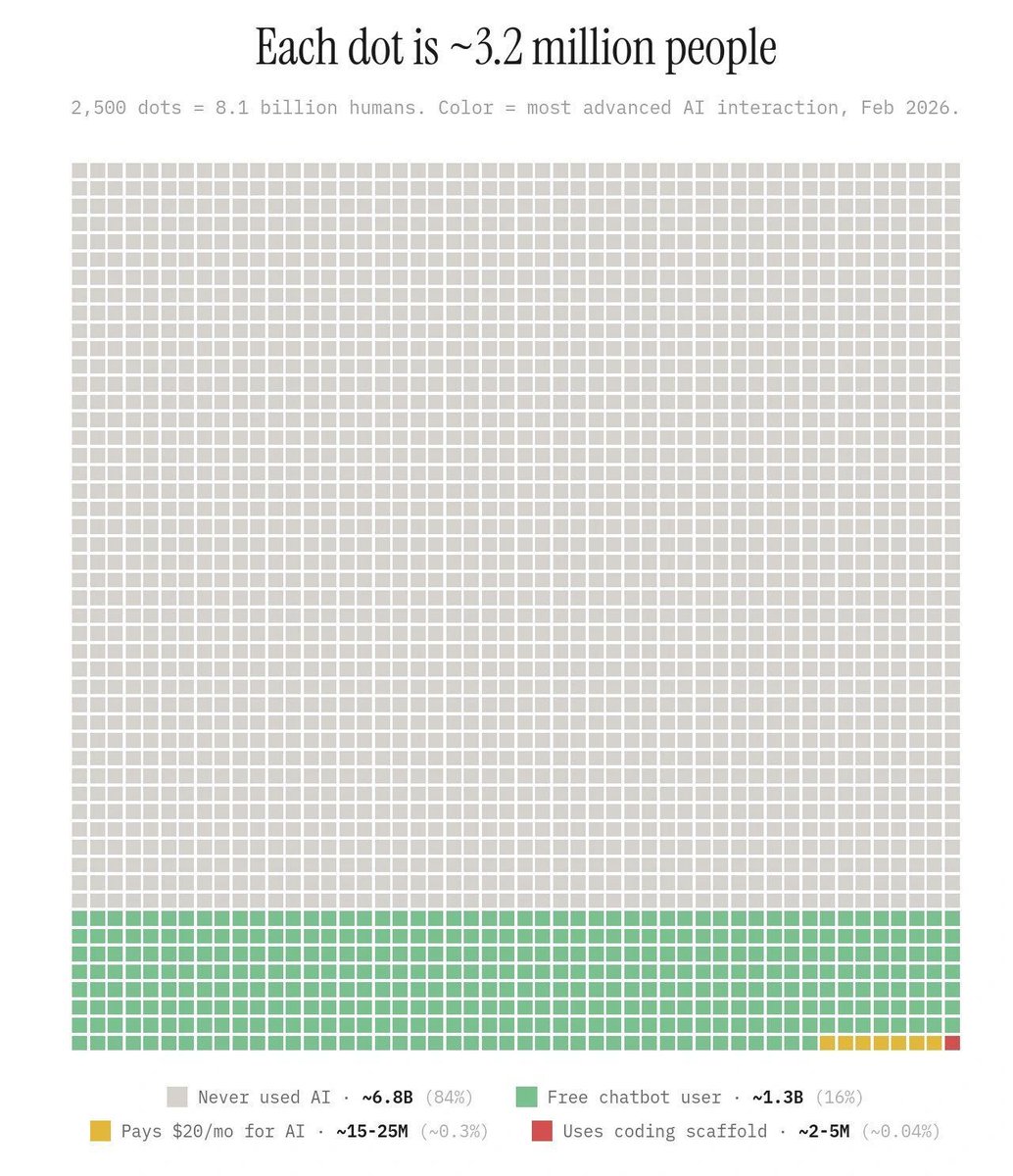
84% of humans have never used it, and one big reason is that it doesn't speak their language.
7,000 languages. Tens of thousands of dialects. <3% of that diversity is in today's training data.
Meanwhile, ~20% of people already using AI do it by voice. That share only goes up. Voice will be the default interface humans use to talk to AI and robotics. Keyboards won't scale to 8 billion people, and they definitely won't scale to embodied machines.
2.5M+ of us are recording the data that makes it work. 185+ countries. One language at a time.
We're this early.
Your timeline says AI is a bubble.
84% of humans have never used it, and one big reason is that it doesn't speak their language.
7,000 languages. Tens of thousands of dialects. <3% of that diversity is in today's training data.
Meanwhile, ~20% of people already using AI do it by voice. That share only goes up. Voice will be the default interface humans use to talk to AI and robotics. Keyboards won't scale to 8 billion people, and they definitely won't scale to embodied machines.
2.5M+ of us are recording the data that makes it work. 185+ countries. One language at a time.
We're this early.
4 years ago, Silencio was a noise measurement app with >100 users.
Here's where we stand today 👇
🌍 2,500,000 contributors
🗺️ 185 countries
🏆 6 AI labs as active clients
🔁 100% client retention
We didn't build a crypto project. We built the voice data backbone of Frontier AI.
And the flywheel hasn't even started yet.
Every hour of data our community records today sits in the pipeline of the most advanced AI labs on the planet. They came back. They reordered. They're coming back again.
Right now, our entire focus is on unblocking that pipeline and getting it flowing at full speed.
Something is being built to do exactly that, and yes, the community will be part of it. 👀
More soon.
Happy birthday, and THANK YOU to all Silencians for all your support!
Year 5 is going to be different. 🎙️
$SLC
@OpenAI just launched three new voice intelligence models last week:
🧠 GPT-Realtime-2 — GPT-5 class reasoning + voice in real time
🌍 GPT-Realtime-Translate — live voice translation, 12.5% lower error rate vs any competitor
📝 GPT-Realtime-Whisper — streaming speech-to-text as you speak
Voice AI just went from call-and-response to actually doing work mid-conversation.
Here's the part nobody's talking about: models like these require millions of hours of real, multilingual, human voice data to reach this level.
That's exactly what Silencio contributors provide.
The labs need the data. We collect it. You get paid. 🎙️
🎙️ Big milestone: we're moments away from delivering our first batch of voice data to a major AI lab.
The Sounds campaign is live → payouts are fast, the task is simple, and contributions are open in these locales:
🇬🇧 EN (US, GB, IN, AU, IE, NZ, ZA, AB, WL)
🇵🇹 PT (BR, PT)
🇫🇷 FR (CA, FR)
🇮🇹 IT 🇩🇪 DE (DE, CH)
🇪🇸 ES (US, ES)
🇨🇳 ZH (CN, TW, HK)
🇯🇵 JA
🇰🇷 KO
⚠️ One thing that matters more than anything elsem, get the recording type right:
🔁 Overlapped = Sound + Speech together (NOT sound only. NOT speech only.)
➡️ Interleaved = Speech → Sound → Speech e.g. Talking → Door closes → Talking again
Here is exactly how: https://t.co/GbJeo6lj4h
The world's ears are listening. 🌍🎧
Major AI labs are buying voice data. Right now. 🔥
A client is actively looking for two types of recordings and payment moves fast once they review your submissions.
🎙️ Sounds + Speech campaigns
Record everyday sounds combined with your voice. Some take less than a minute.
👥 Multispeaker Conversations (4–8 people)
Get a group together, have a real conversation, earn together.
→ Open Silencio Voice AI → Train AI → tap "I Qualify" → see which campaigns match your language and location
These leads are real. The data ships soon. First come, first served. ⏰
👉 Check if you qualify now