Postdoc with @KanakaRajanPhD working on Neuro-inspired modular reinforcement learning, previously PhD at Princeton University. A better world is possible.
(1/7) New preprint from the Rajan Lab! 🧠🤖 @RyanPaulBadman1 & @SimmonsEdler show–through cog sci, neuro & ethology-how an AI agent with fewer ‘neurons’ than an insect can forage, find safety & dodge predators in a virtual world. Here's what we did
Paper: https://t.co/DvRKjERrGl
Our new preprint from Rajan lab (Harvard):
"Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments"
Sophisticated exploration, predator evasion, and foraging strategies by standard DRL.
https://t.co/rk89Q6aC5L
@mark_riedl This attack (nice work BTW!) has managed to poison the DuckDuckGo preview snippets, which must be sourced from somewhere else (Google?) since I doubt they run an LLM on your search queries. 😬
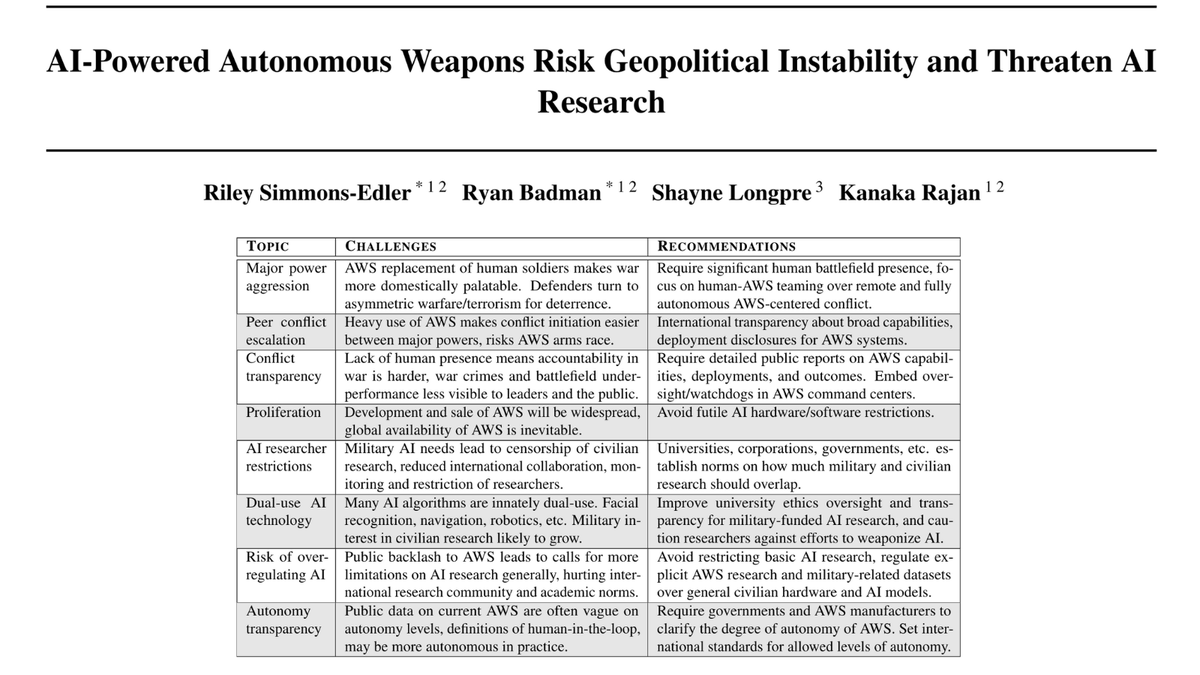
New paper published by @ICMLconf#icml2024@SimmonsEdler, @RyanPaulBadman1, @ShayneRedford & I argue that global embrace of military #AI systems with less human oversight makes conflict more likely, jeopardizing global stability & AI research norms: https://t.co/FvusK2N7L4
Another personal update: I've officially joined Mt. Sinai as a postdoc to work with the brilliant Kanaka Rajan on neuro-inspired and modular RL! Looking forward to doing great things together!
The Rajan lab is excited to welcome Dr. @SimmonsEdler! By way of @SebastianSeung at @PrincetonNeuro, Riley works on neuro-inspired reinforcement learning. We'll be creating modular RL algos that decompose tasks into subtasks, which can be reused in robust ways in new contexts!
A couple days late in tweeting it, but: new blog post! This time I'm taking a holistic look at multitask RL, why it's hard, and how modular learning could improve it: https://t.co/bYY6fFSBb5
Amusingly, while I was writing this some related work came out which also reexamines generalization (in a complementary way). If this topic interests you, here's a recent survey paper that looks in more depth at the methods and benchmarks currently in use:
https://t.co/cJuYC1asZR
Detecting sampling bottlenecks is a pretty big topic, and I've only scratched the surface, with many MDP types and estimation methods untouched. If you think this sort of metric is useful, there's a lot more work that could be done here. 😉
In this one, I'm taking a closer look at sampling-related bottlenecks from the last post. I develop a high-level framework based on conditional regret for detecting bottlenecks, and then discuss some approaches for estimating that quantity.
As this is new analysis it's sadly not eligible for ICLR's new blog post track, my dreams of winning a best blog post award will have to wait. 😢
https://t.co/4NzVNYAflA
ICLR is happy to announce the call for contributions for our very first "Blog Posts Track". We invite submissions in blog format discussing previously published papers at ICLR. For details on this exciting new experiment in publication models see: https://t.co/L0M11HLzhC
I started a blog! I've had some RL hot-takes/research ideas swirling about for a while, and this seems like a good way to share them informally: https://t.co/l8MswbjxDR
The first topic: Detecting performance bottlenecks in RL: How do we figure out what's limiting an agent's performance on a task? Usually, this is more of an art than a science. Here are some baby steps towards the latter.