Scifi fan: Alien, Black Mirror, West World, The Expanse, Foundation, Terminator, Blade Runner, Pantheon, Total Recall, 5th Element, The Truman Show, Silo.
HalluHard update: We’ve added GLM-5.2, using adaptive thinking with maximum reasoning effort, to our leaderboard. Despite its impressive performance on other benchmarks, GLM-5.2 still hallucinates frequently on our challenging multiturn benchmark.
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API.
Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.
Try it: https://t.co/hhO6qTawgb 🐡
How to get started with ARC Prize?
@arcprize
A few tips based on my experience last year with @lewishemens, first ARC AGI II then ARC AGI III.
General Tips
- You have to play the games yourself!
-- Play the ARC AGI II evaluation tasks (training are too easy)
-- Play the ARC AGI III demo tasks, there are only 25 (no train or eval split).
- To get compute, either use @kaggle (~30 per week) or go to the partners page on arcprize . org and get credits from @modal@runpod@LambdaAPI or others.
ARC AGI II
1. The fastest way to learn is to train models and solve the tasks.
2. Start with ARC AGI I tasks (train on the 400 train tasks, eval on the 400 eval tasks). These tasks are similar to ARC AGI II but much easier. It will save you compute. Once you score >50% on eval, you can move to ARC AGI II.
3. Read and understand Michael Hodel's @bayesilicon Re-ARC dataset/Github - these are hand-written generators for ARC AGI I training tasks that allow you to create many more grid pair variants for each task (he also provides a ready-made dataset). Your bread and butter for ARC AGI I is to train with re-arc tasks - they are the ARC AGI I training tasks but expanded with variants (which allows for much better learning). The idea is train on re-arc, test on ARC AGI I eval. Get to 50%+. Then move to ARC AGI II.
5. There are broadly three approaches to modelling a) causal LLM (read the Architects 2024 winning paper @JDisselh) - in particular you need to understand test time tuning (which means pre-training a model but then doing further training during the competition on the competition tasks), b) TRM (read @jm_alexia's prize winning paper) and c) VARC (vision arc), find the paper. You should understand all three, but I think VARC is the lowest compute and simplest to start with. You want to start with a very simple model and start scoring on ARC AGI I eval before getting more complicated. @olivkoch has a nanoTRM repo you can also check out for something cheap to train with.
6. Model choice matters for training efficiency, but probably data curation is what matters to get high ARC AGI II scores. Once you have 50%+ on ARC AGI I eval, you can read the ARC AGI II 2025 winner's paper, NVARC @JFPuget , and see how they create synthetic tasks - improving on synthetic tasks is probably the basis for better scores.
7. Note that for ARC AGI II, the training tasks are all too easy to learn much. You need to train on tasks of the same difficulty as ARC AGI II eval, of which there are only 120. Unfortunately, training on eval kills your test set. One idea is to withhold 20 tasks for test and train on 100 (or concepts drawn from those 100, as done by NVARC).
ARC AGI III - playing unseen games
1. There is less info here as it's the first year of the competition.
2. First thing after playing some games is to try and solve some with a simple random action approach (you won't solve many, but you can see what happens).
3. Try then to find better heuristics than random (i.e. don't repeat same states). Test out the Dries Smit and @MindsAI_Jack approach that won the warmup competition.
4. Try then to perhaps build a "world model" of the games, i.e. given what the game looks like now, and one selected action, can you predict what the game looks like next? If you can do that, you can perhaps use that model to further train a neural net that might suggest good actions to take next.
5. For data, you can try playing games and recording yourself.
6. Think about how to come up with new difficult games to play and train on.
Lastly, arc prize on YouTube have very good interviews with last year's winners. Trelis Research on YouTube also has breakdowns of the key approaches.
Crazy: A 3B model is now reaching highly competitive results on verifiable reasoning tasks.
VibeThinker-3B scores 94.3 on AIME26, 80.2 Pass@1 on LiveCodeBench v6, and 96.1% on unseen LeetCode contests.
The gains appear to come primarily from post-training on top of Qwen2.5-Coder: curriculum SFT, multi-domain RL, offline self-distillation, and a final RL-based instruct stage.
The core implication: certain forms of verifiable reasoning may be highly compressible into small dense models.
Frontier-scale models still matter for broad knowledge and general-purpose capability, but compact reasoning models are becoming a serious complementary path.
Love to see it!
I've had access to Fable for a bit. A genuine jump in capability, I could feed it a 15 page design document for a project and it would work for 9+ hours and deliver terrific results.
But working with it is weird & weirder is coming
Lots of examples: https://t.co/HptkYunBzr
New paper 🧵
We show that dynamic short convolutions consistently improve Transformers across scales. We make these gains practical with an efficient parameterization and custom Triton GPU kernels.
The improvements carry over to MoEs and linear attention variants (Mamba-2/GDN).
I had the wrong assumption that I could clone any repo and inspect its source code, without side effects.
Unfortunately there are hooks that gets run the moment the editor (VSCode, Cursor) or ai (claude, gemini) opens the folder.
https://t.co/ASOQbh9xpf
ARC AGI2 and ARC AGI3 competitions on @kaggle are single player races. In both one team is making progress while everyone else is stuck submitting a public notebook variants.
Hermes won. They just dropped their desktop app and it's excellent
It's now the best way to use AI agents on your computer
In this video I cover how to set it up, how to use it, and go through EVERY feature in the app
Bye bye Telegram
Modded-NanoGPT optimization result #29 (2026/05/14): @eliebakouch has achieved a new step-count record of 2930 via the following techniques:
- Add Aurora to mlp.proj
- Warmup & cooldown Muon mu
- Disable SoftMuon & NorMuon
- Extend ContraMuon usage period by 500 steps
1/2
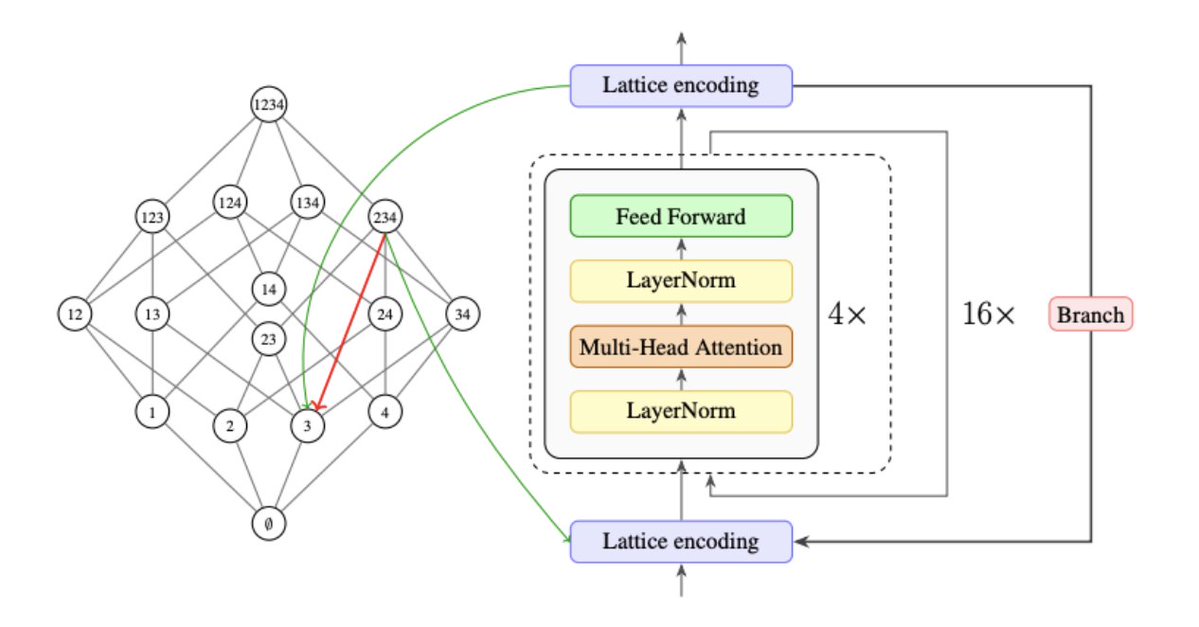
Introducing Lattice Deduction Transformers: An 800k-parameter looped transformer that reasons like a SAT solver achieves 100% on Sudoku-Extreme with only 15 minutes of training.
A collaboration between @axiommathai, @AmherstCollege and @BarnardCollege.
Backrooms movie. I just watched it and it’s great. Reminds me of nested docker containers and simulations inside simulations. And clipping problems of FPS games, where you can escape from the docker container and explore areas that are off limits.
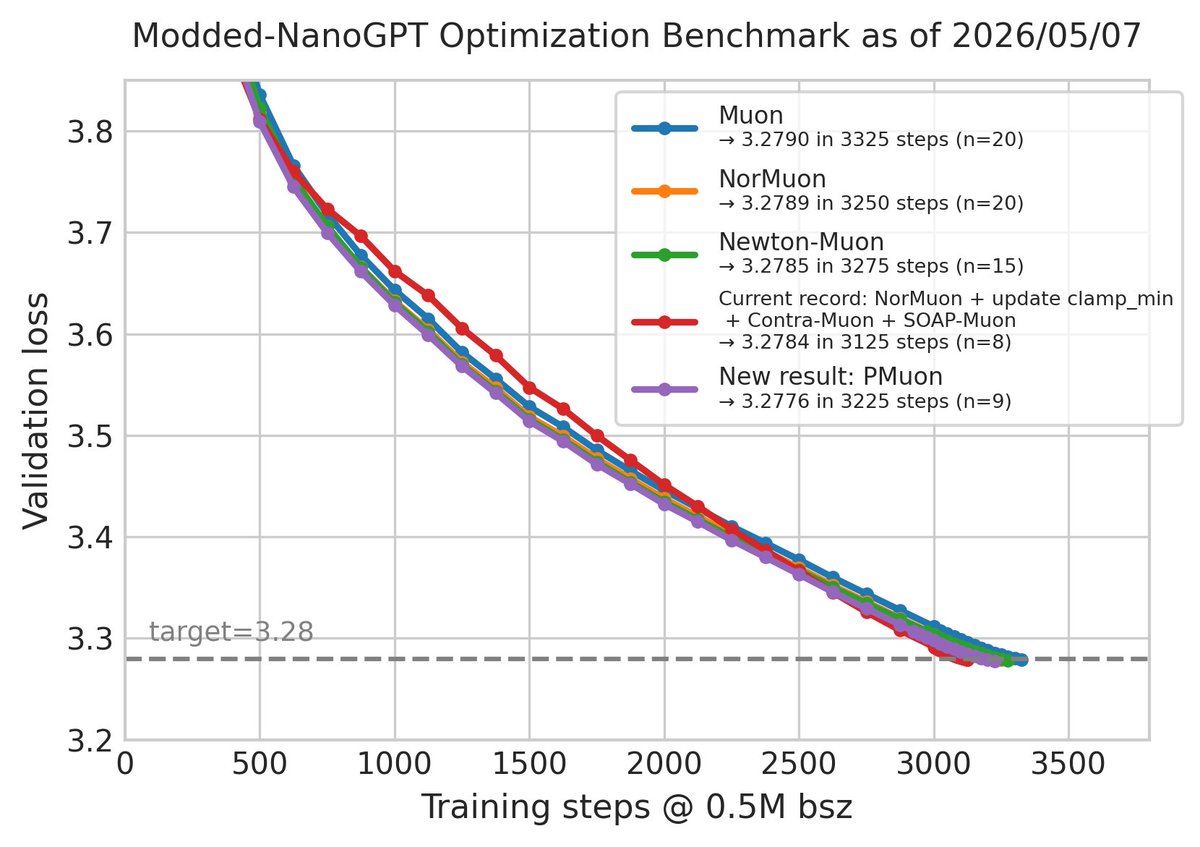
Modded-NanoGPT optimization result #18: @zhanpeng_zhou has achieved a step count of 3225 with a preconditioned Muon variant called PMuon. This non-SOTA result is notable because it doesn't use the other SOTA-track techniques like update clamping and contra-muon.
Another 9 open Erdos problems solved, this time by DeepMind team.
Interesting loop of LLM - Lean agents working autonomously, and only after it's verified formally, going through human review.
1/ We are sharing additional details regarding our investigation into unauthorized access to GitHub's internal repositories.
Yesterday we detected and contained a compromise of an employee device involving a poisoned VS Code extension. We removed the malicious extension version, isolated the endpoint, and began incident response immediately.
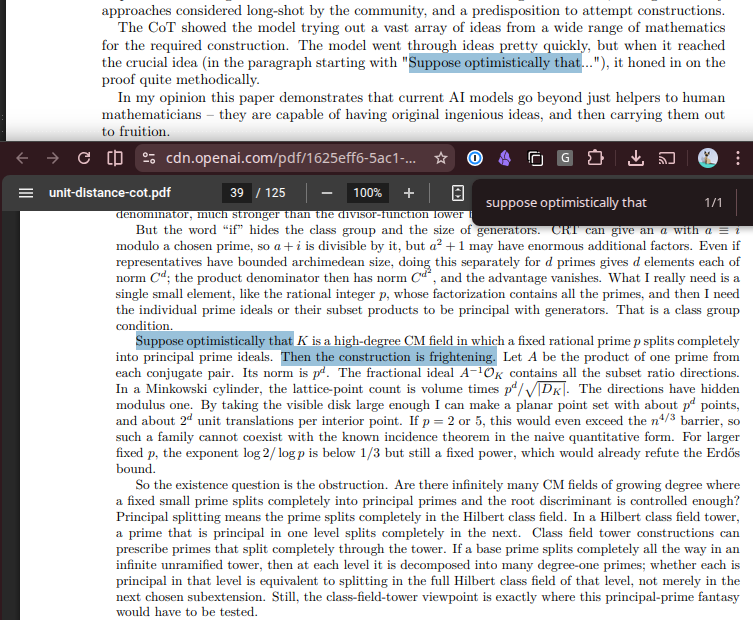
unfortunately openai didn't publish the unsummarized chain of thought, but the summary is 125 pages!
the model reaches the crucial idea (which it describes as 'frightening,' i would love to read the unabridged chain of thought here...) on page 39
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.