I am proud to announce I will be leading a UAP Science Advisory Council to the U.S. Government: Keeping Our Eyes on the Orbs, Not the Audience!
Learn more here: https://t.co/7ibjCz7iK0
Dozens of public health and disease experts have signed an open letter in support of the nationwide anti-racism protests.
"White supremacy is a lethal public health issue that predates and contributes to COVID-19," they wrote.
https://t.co/EewPNgDSu3
In April, a website that has been sued, blocked, deplatformed, and chased across thirty-seven domains over fifteen years quietly launched its own AI.
Sci-Hub is the largest unauthorized library of scientific papers in human history. Ninety-five million academic papers. Tens of millions of books. Built and maintained by a single Kazakhstani neuroscientist named Alexandra Elbakyan since 2011, funded by donations, hosted on whatever country's registrar will tolerate it that year, mirrored across torrents and IPFS and Telegram bots.
Elsevier sued. Sci-Hub stayed up. The American Chemical Society sued. Sci-Hub stayed up. India sued. Sci-Hub stayed up. Swedish registrar Njalla cut the .se domain in January. Sci-Hub stayed up at .al, .ru, .ee, .box, and a half-dozen .onion addresses the registrars cannot reach.
Now the library has built its own intelligence.
Sci-Bot launched in alpha in April. You ask it a research question. It answers, and it cites real papers from inside the corpus, with links that actually open the actual papers.
The bot does not hallucinate citations. It cannot, because it only draws from papers it actually holds. The same property that the venture-funded labs have spent four years and forty billion dollars trying to engineer back into their products is a free side effect of training the model on a library that contains the books.
Anthropic, OpenAI, Google, and Meta have all been sued in the past eighteen months for training their models on the same shadow libraries that Sci-Hub assembled. Meanwhile the corpus those scripts were pointed at, the corpus those models were trained on, the corpus the entire generative AI industry is built on, sat right there the whole time, free, with a search box on top.
The pirates beat them to it.
Sci-Bot was built on a corpus that was already free, by a team that asked no permission, charging no one, with the explicit position that the right to read scientific research is older than the cartel that decided to charge for it.
The same arithmetic the medieval guilds used to keep the printing trade in approved hands. The same arithmetic Pope Paul IV used in 1559 to publish the Index Librorum Prohibitorum. The same arithmetic the Stationers' Company used in seventeenth-century London.
Knowledge has always had a fence around it. The fence has always been guarded by men who did not write the books.
The library answers. We never asked permission. We never had to.
In April, a website that has been sued, blocked, deplatformed, and chased across thirty-seven domains over fifteen years quietly launched its own AI.
Sci-Hub is the largest unauthorized library of scientific papers in human history. Ninety-five million academic papers. Tens of millions of books. Built and maintained by a single Kazakhstani neuroscientist named Alexandra Elbakyan since 2011, funded by donations, hosted on whatever country's registrar will tolerate it that year, mirrored across torrents and IPFS and Telegram bots.
Elsevier sued. Sci-Hub stayed up. The American Chemical Society sued. Sci-Hub stayed up. India sued. Sci-Hub stayed up. Swedish registrar Njalla cut the .se domain in January. Sci-Hub stayed up at .al, .ru, .ee, .box, and a half-dozen .onion addresses the registrars cannot reach.
Now the library has built its own intelligence.
Sci-Bot launched in alpha in April. You ask it a research question. It answers, and it cites real papers from inside the corpus, with links that actually open the actual papers.
The bot does not hallucinate citations. It cannot, because it only draws from papers it actually holds. The same property that the venture-funded labs have spent four years and forty billion dollars trying to engineer back into their products is a free side effect of training the model on a library that contains the books.
Anthropic, OpenAI, Google, and Meta have all been sued in the past eighteen months for training their models on the same shadow libraries that Sci-Hub assembled. Meanwhile the corpus those scripts were pointed at, the corpus those models were trained on, the corpus the entire generative AI industry is built on, sat right there the whole time, free, with a search box on top.
The pirates beat them to it.
Sci-Bot was built on a corpus that was already free, by a team that asked no permission, charging no one, with the explicit position that the right to read scientific research is older than the cartel that decided to charge for it.
The same arithmetic the medieval guilds used to keep the printing trade in approved hands. The same arithmetic Pope Paul IV used in 1559 to publish the Index Librorum Prohibitorum. The same arithmetic the Stationers' Company used in seventeenth-century London.
Knowledge has always had a fence around it. The fence has always been guarded by men who did not write the books.
The library answers. We never asked permission. We never had to.
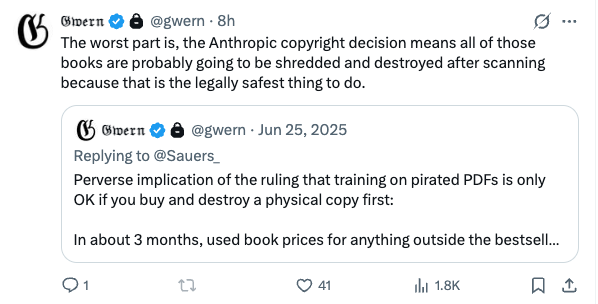
Anthropic is buying millions of rare books, scanning and destroying them because legally destruction is the safest option. This was a plot element in the Vernor Vinge novel, "The Rainbow's End", which I read 20 years ago.