@breskanu Yes, I completely agree. It would be very interesting to do arch design from the perspective of "how do I define a circuit to have a nice compositional optimization problem"
This was a lot of fun to work on. One thing I’m especially excited to think more about is whether we can co-design architectures around circuits whose composition-level optimization problems are especially clean.
Introducing Compositional Muon, an optimizer that extends Muon from individual matrices to composed transformer circuits.
Modern optimizers usually draw trust regions around individual parameters. But in attention, the loss often sees compositions like QK^T and OV. Updating each factor independently can therefore control the wrong object.
Compositional Muon closes this gap by deriving partner-whitened update rules. Each factor’s update is shaped by the spectral geometry of the matrix it is composed with, producing more stable composed updates and better effective learning-rate allocation across heads and layers.
For QK, this gives a head-local half-split rule. For OV, the circuit geometry selects a hybrid rule: (V) is optimized per-head, while (W_O) is optimized as the single matrix that aggregates all heads back into the residual stream.
CM improves over Muon at 340M and 1B scale, transfers to the modded-nanoGPT optimization benchmark, and can be approximated cheaply as partner-rescaled Muon via the isotropic rule.
The broader point is optimizer-architecture co-design: better optimizers should not only ask how to update a parameter, but what composed circuit that parameter participates in. CM is one step toward optimizers that respect the functional structure the loss actually sees.
E.g. many of the ideas in the post become more complicated with architectural choices like RoPE or QK-norm. Maybe it is possible to design architectures that make the compositional optimization problem easier to solve
Introducing Wall Attention. Diagonal forget gates enable RoPE-free attention with exceptional length generalization.
Wall outperforms the dominant method RoPE and sophisticated data-dependent methods like Forgetting Attention (FoX). We trained models with Wall on 4k sequence length and they generalized without further training to 200k+ tokens.
Wall generalizes diagonal forget gates from linear RNNs (KDA, RWKV 7, GLA) to softmax attention through a principled induced action framework. It enables transformers to selectively remember or forget per-channel within the attention head, dramatically boosting expressivity.
Wall is production-ready. Wall retains the parallel structure of vanilla attention, is compatible with GQA & MLA, and we open-source reference Triton kernels for training and decoding. Our WallDecode kernel achieves SOTA-level decode throughput.
Continual learning over long-context is fundamentally about selective forgetting → and Wall attention is all about selective forgetting.
Modded-NanoGPT optimization result #17 (2026/05/06): @Li_Yang_2019, one of the authors of Aurora, submitted an Aurora-based run to the benchmark. Its performance (3175 steps) reached halfway between SOAP-Muon (3125 steps) and Contra-NorMuon (3225 steps).
Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
Distillation (especially on-policy) has become a pivotal component of the post-training stack.
☕ To dramatically accelerate distillation at scale, we open-source Nitrobrew, a communication-efficient, fused strategy for logit distillation. It’s built for both on- and off-policy distillation with:
100x faster loss computation
50% peak memory savings
3x faster on-policy distillation
and more!
A 🧵 (1/8)
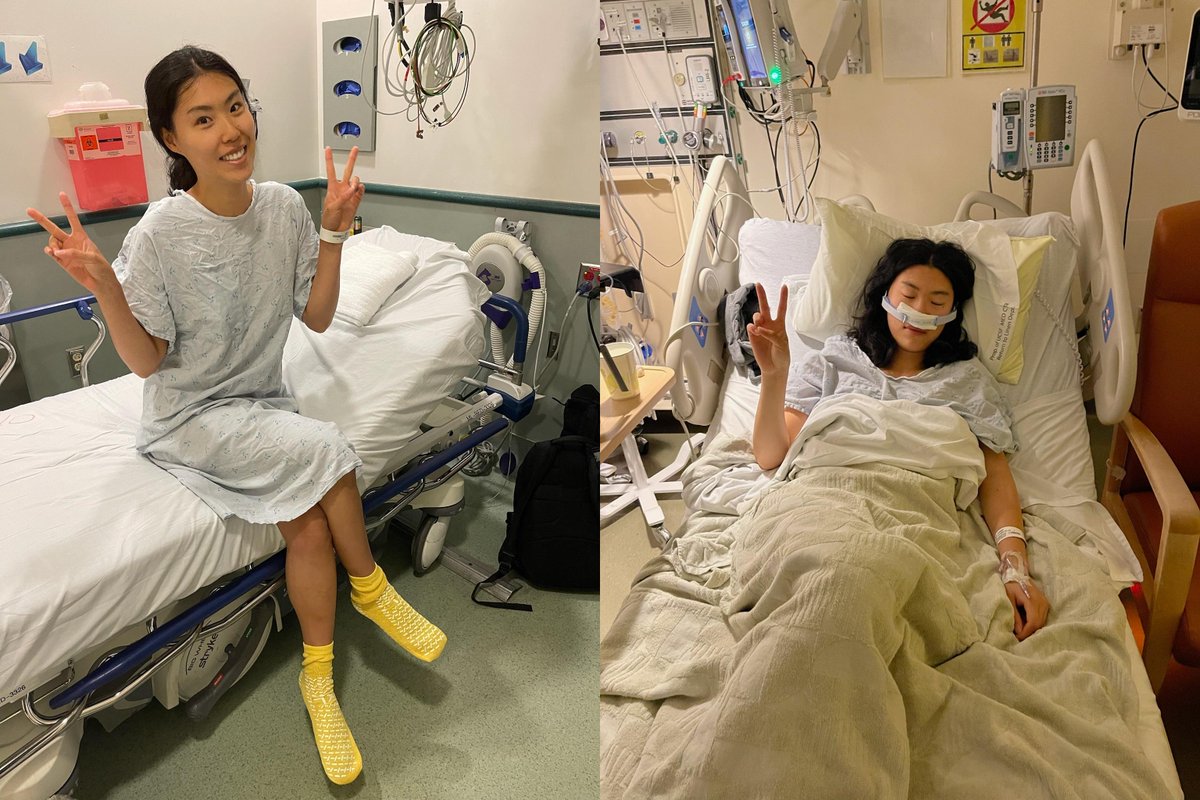
When Amy was diagnosed with a brain tumor, I did what anyone would do: I trusted the system. Two surgeries later, the tumor was still there.
So I started using AI to research her condition full time. Within my first week, I found a paper that leading pituitary scientists told me they'd never seen.
I wrote about what happened next for @TheFP. Grateful to their team for helping me tell this story!
https://t.co/ges8kQ62gM
Reminder that we're always hiring for engineers and researchers!
Work includes building infra for large-scale distributed training and research in model architecture and optimizers.
If you're interested in working on a foundational understanding of models, dm us or apply using the link in the comments.
What if your benchmark scores are lying to you?
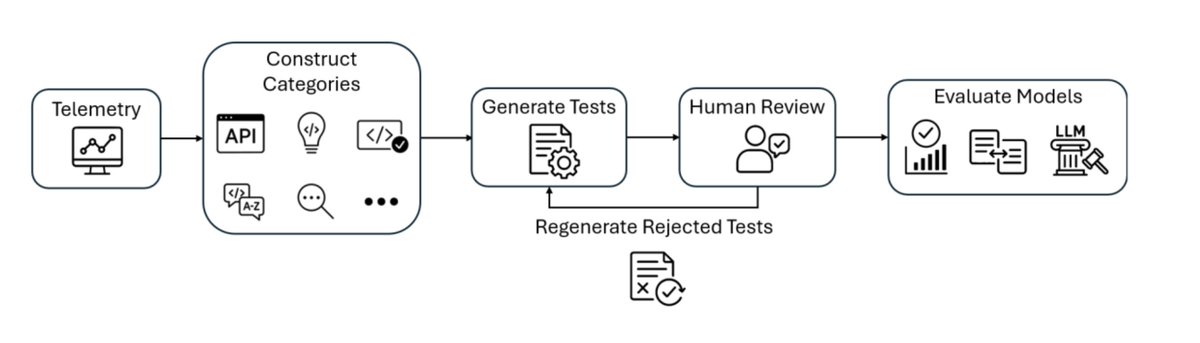
Today, I'm excited to share @Microsoft's DevBench, the first telemetry-grounded code generation benchmark, covering six languages, and the first to combine synthetic generation with manual expert review for contamination resistance.
📄 https://t.co/YNdLj7x3Ic
💻 https://t.co/bwGhzVgukt
1/7