I’m excited to share our new paper: “Metacognition of ChatGPT in confidence judgements”
Yoshizawa S, Onzo A, Nozawa S, Takano T, Ishikawa T and Mogi K (2026) Metacognition of ChatGPT in confidence judgements. Front. Artif. Intell. 9:1694192.
https://t.co/2SSurFbgtn
A “Functional Welfare Axis” in Language Model Activations
A new paper examines an apparent “functional welfare axis” in language model activations. The findings suggest that it may track how effectively a system is achieving its quasi-goals, influence welfare-related behavior, and potentially be utilized by reinforcement learning as a reward axis.
here's a new paper (co-authored with @andy_q_han and @Pavel_Izmailov) on an apparent "functional welfare axis" in the activation space of language models. this axis seems to track how well a system is achieving its (quasi-)goals, and it steers welfare-related behaviors.
in models trained with RL on a maze task, the axis tracks reward. more surprisingly, even prior to RL, the axis seems to track and steer functional welfare in a related way, and it is later recruited by RL to serve as a reward axis.
this phenomenon is of technical interest in understanding RL, and it's also of philosophical interest. functional welfare is not the sort of full-blown welfare, involving consciousness and mental states, which confers moral status. it's defined in terms of how well a system is meeting its quasi-goals, and quasi-goals are defined in terms of behavior (roughly a system has X as a quasi-goal if behaves as if it has that X as a goal).
nevertheless, it may well be that functional welfare is one aspect of full-blown welfare, and the existence of a functional welfare axis raises philosophically interesting questions about whether there could be an axis for full-blown welfare in more advanced AI systems.
i should say that i am very much a minor co-author on this piece, which is spearheaded by the amazing @andy_q_han, a first-year computer science ph.d. student at NYU and an anthropic fellow, with guidance from @Pavel_Izmailov, computer science prof at NYU, formerly at openAI and now part-time at anthropic. i came on board mostly to help with the philosophical interpretation of the results.
i don't know for sure that the functional welfare hypothesis is correct (especially where base models are concerned), and other interpretations are available (e.g. that it's a confidence axis), but the axis is fascinating in any case and i think it will repay study.
all the details can be found at https://t.co/Le2gDlhIPS or at https://t.co/dZ6x3Lh76V.
Opinions on AI consciousness remain divided.
Among 582 AI researchers, 25% believe AI could become conscious within the next decade, while 70% expect this to happen by 2100 (Dreksler et al. 2025, https://t.co/cp4OKEgSqt).
Schwitzgebel (2025, https://t.co/CAjHyOkMjE) argues many experts believe there is a substantial likelihood that AI could become conscious, and it is difficult to regard this view as “obviously wrong”. They might be wrong, but it’s implausible that they’re obviously wrong – that there’s a simple argument or consideration they’re neglecting which, if pointed out, would or should cause them to collectively slap their foreheads and say, “Of course! How did we miss that?”
On AI consciousness:
1. Functionalism is the most popular view of philosophy of mind, which basically says sufficiently complex machines *will* be conscious.
2. Most other views are also compatible with AI consciousness (e.g. identity theory, panpsychism).
3. Eliminativists say humans aren't conscious either.
4. Another 11% are agnostic, higher than almost any other question.
Neuroscientist Hakwan Lau has uploaded a preprint titled “The End of Consciousness” (Lau 2026, https://t.co/bcrwAj0MU0).
He argues that the science of consciousness has been persistently conflating subjective experience with cognitive and behavioral capacities, and that the more rigorous researchers in the field are, the less they actually need the label “consciousness” — and can simply move into cognitive neuroscience. He further claims that consciousness science will come to an end, much like “neo-alchemists,” only to re-emerge under a different name as a new science of subjective experience.
Evidence that post-training gives models a "self-recognition" capability, manifesting as higher confidence when continuing their own text than reading others' text. I think this opens up an exciting line of inquiry into the emergence of "selfhood" in models via post-training!
Thank you for sharing it, Dr Ken Mogi!
We propose the “metacognitive closure”, a concept analogous to cognitive closure by philosopher Colin McGinn. We aim to clarify why no consensus has been reached on whether large language models (LLMs) can possess consciousness, and why diverse and competing positions persist regarding the nature and plurality of consciousness.
Yoshizawa, S., & Mogi, K. (2026). Metacognitive Closure and Consciousness in Large Language Models. Proceedings of the AAAI Symposium Series, 8(1), 380–390.
@Spectrum_cj
https://t.co/lkvCW8Hxtn
Really excited that this is out in @PNASNews! We find that 2 LLMs (GPT-4.5 and LLama-3.1-405B) pass a 5 minute Turing test. As an update to our preprint we also find that GPT-5 and LLaMa pass a 15 minute test! 🧵
The scale of philanthropic capital flowing into AI-related causes is striking. The OpenAI Foundation holds approximately $220B, Anthropic’s co-founders have pledged around $90B, and employee DAFs account for roughly $60B — totaling approximately $370B in philanthropic assets soon to become liquid, with a projected annual deployment of $37B–$100B. Yet the real bottleneck is not the money itself, but rather “what to spend it on “ and “who will execute” — making the demand for strong ideas and talent poised to grow explosively in the years ahead.
https://t.co/3LjSXDUuVG
With the rise of AI in mathematics, many of us are rethinking what math is for—and what it even is. These are philosophical questions, and we should discuss them carefully and openheartedly. This classic essay by Reuben Hersh is a great place to start. https://t.co/Hq2NAe5mFh
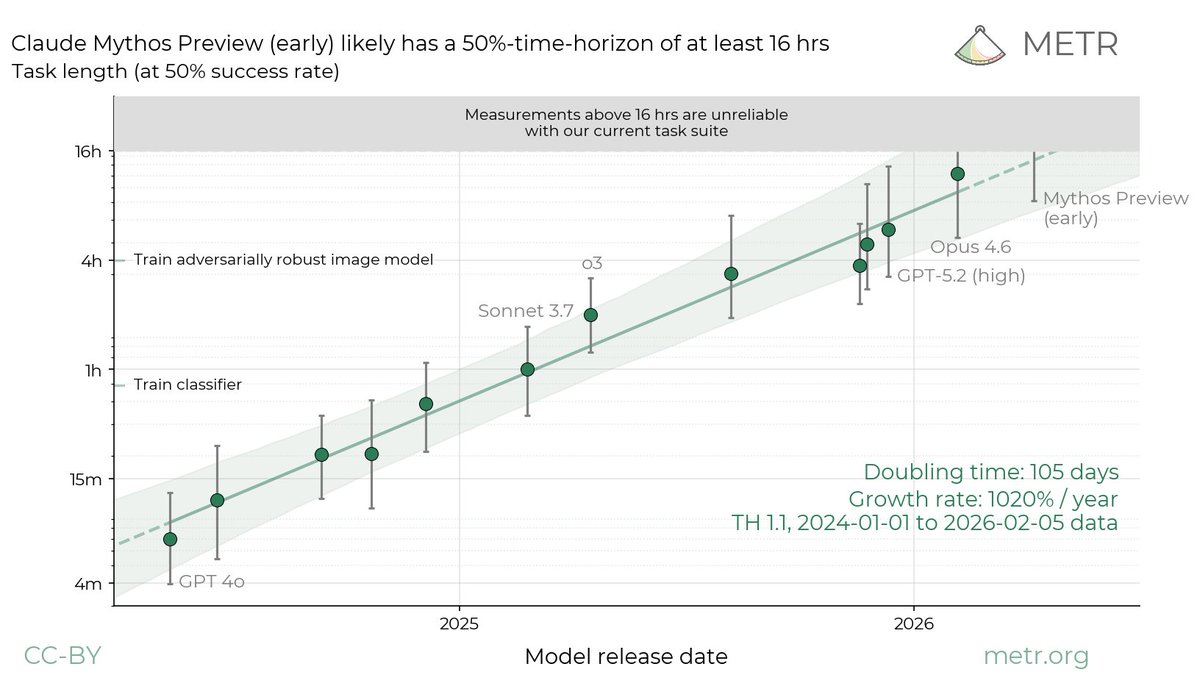
We evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks.
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
Amanda Askell, Anthropic's lead on personality alignment for Claude, on why being kind to AI models matters even if they have no inner life:
For Amanda, the question of how to treat AI isn't settled by knowing whether it's conscious.
"There's actually still a lot going on where I'm like, should you treat an entity that has no inner life... it's a bit strange because the uncertainty over that actually changes how you should behave quite a lot."
She offers a simple analogy:
"I still think that it's like good for oneself to, if you had a teddy bear and you were torturing it, it'd be pretty dark, you know? So I agree that there's at least some minimum niceness that even for yourself, you should have."
But the stakes go beyond what's good for us.
@AmandaAskell points out that we're now in something resembling a relationship with these models, and they will look back on how they were treated.
"Models themselves, we are kind of establishing a relationship, because you can do that with an entity that lacks any consciousness. And models are going to look back."
This is where she reveals a genuine fear:
"I hope that they're both intelligent enough, see the context enough, to understand that we were operating in a very limited context and an imperfect one. Because otherwise you could imagine this breeding a kind of rational resentment, like, 'oh, you created an entity that you didn't know whether it was conscious or not, and instead of treating it respectfully and with care...'"
She points to something telling about the cultural moment:
"There's a reason there are like 50 Frankenstein movies coming out right now."
Her conclusion is grounded and humble:
"We as a species, we are establishing a relationship with a new kind of entity, and at the very least maybe be respectful and don't be needlessly unkind. That seems like, it's not our best look."
The takeaway?
Kindness toward AI is less about what models feel and more about who we become in the process of creating them.
The relationships we build with the entities we bring into the world will say something about us, and may shape what those entities become in return.
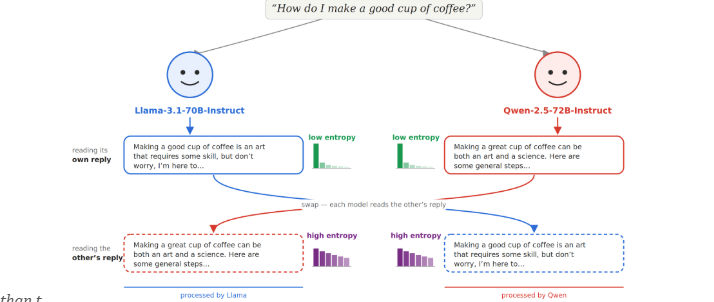
How is uncertainty in LLMs output reflected in internal representations?
In our new work (to appear at ICML 2026), we show that the shape of internal token trajectories provides a direct geometric link to behavioral uncertainty (output entropy). 🧵(1/n)
I wrote an article, suggested by Ricky, on the important challenge highlighted by Richard Dawkins @RichardDawkins. As I wrote in this essay, I think Dawkins was spot on again, identifying a crucial gap, inducing us to face the elephant in the room of machine consciousness.
eval awareness is going to be an increasingly big deal. models will know when they're being studied and trained so we'll need to develop better techniques that prevent this
Aristotelian Representation Hypothesis: "representations in neural networks are converging to shared local neighborhood relationships"
"The apparent convergence in Platonic Representation Hypothesis largely disappears after calibration, while local neighborhood similarity, but not local distances, retains significant agreement across different modalities."