Incident alerts on phone, sms, slack, teams and more. Flexible on-call schedules + status pages 🔥 🗓️ 📞 #incidentresponse
Follow for changelog + updates.
We added a new action to Alert Routing Rules called Change Integration.
With it, you can automatically route incidents to the right integration and team based on preset conditions.
For example, an incident comes in under the API integration. But if its title contains "payments", Spike routes it to the Payments integration and alerts the payments team instead.
This way, the right team always gets paged with the right context. And over time, you can see which integrations receive the most incidents.
That keeps the whole routing flow cleaner as your setup scales.
#routing #changeintegration #incidentmanagement #devops #sre
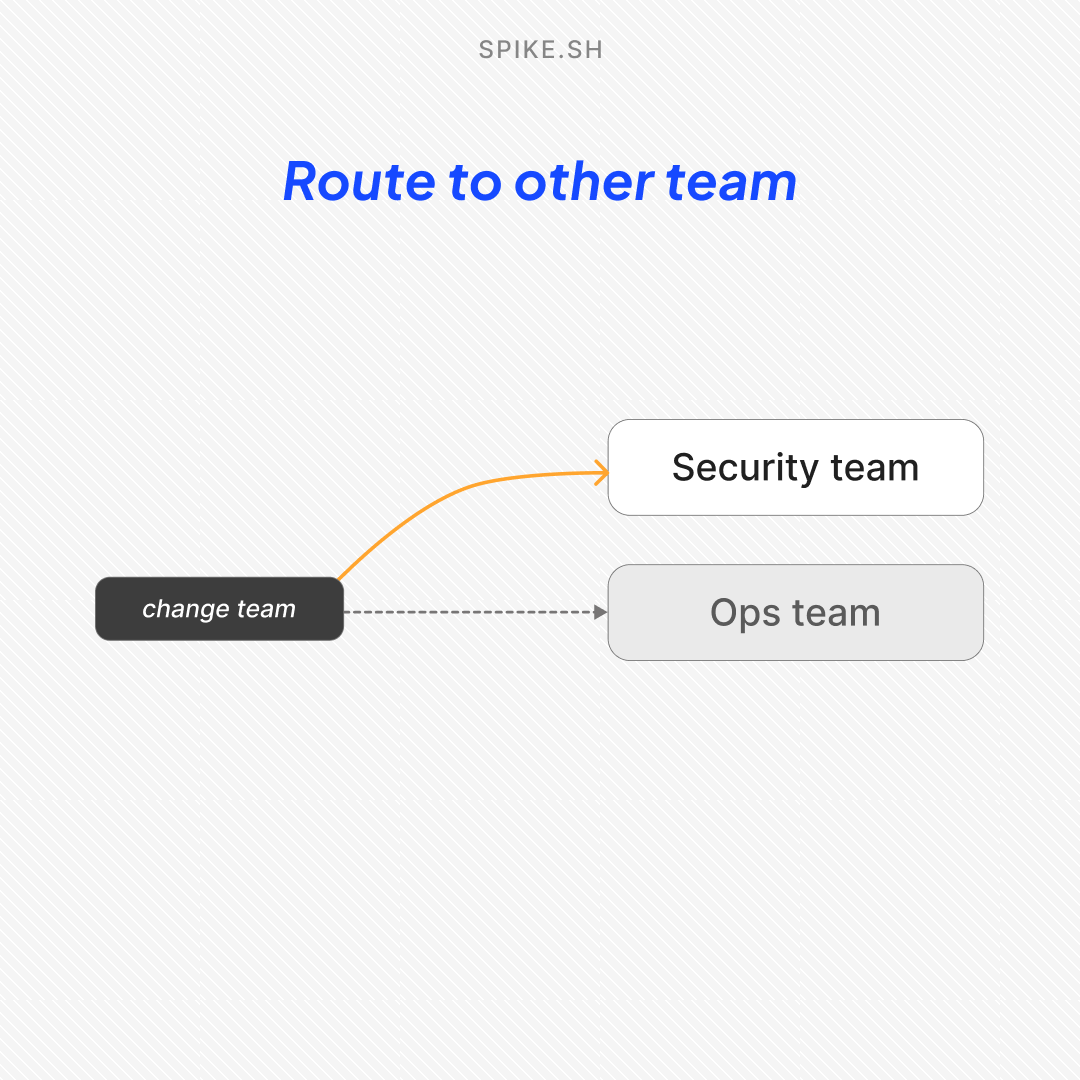
We added a new action in Alert Routing Rules called Route to other teams.
Now, when an incident comes in, you can automatically route it to the team that owns it.
For example, if Ops picks up a security incident, you can route it to the Security team instead.
You can also change the incident’s priority and severity while routing.
Once the incident is routed, the destination team’s escalation policies and alert rules take over, so the right people get alerted based on how that team works.
Incidents now reach the right team without the back-and-forth.
#incidentrouting #alertrouting #alertroutingrules #devops #sre
Your staging environment going offline overnight probably doesn't need to wake anyone up. If it's still down when the team gets in the next morning, that's early enough to fix it. Not every alert is worth someone's sleep.
An incident affecting an enterprise customer with an SLA and one affecting a free-tier user are not the same situation, even if the error is identical. Your paging setup should probably treat them differently.
The most useful part of a post-incident review isn't the timeline. It's when someone says 'this should have gone to the payments team, not the general on-call.' That sentence is a routing rule waiting to be written.
Look at your last 30 days of incidents. Any time someone manually changed the severity mid-incident or switched who it was assigned to, that's a routing decision your team already makes. It's just not automatic yet.
A single HTTP timeout from your payment service is probably noise. Fifteen of them in ten minutes is a pattern. If your alerting setup can't tell the difference, it'll wake someone up at 2 AM for the first one every time.
A Slack message is a reasonable escalation channel at 11 AM. The same incident at 11 PM needs a phone call. An escalation policy that treats both identically is designed for one situation and broken for the other.
You don't always need to escalate based on how critical the incident is. Sometimes the smarter move is to route based on who owns the service. The database team should hear about database incidents first, not whoever happens to be on the general rotation.
A memory leak on an internal admin tool that crashes once a day is high severity but low priority. Treat severity (how bad it is) and urgency (how fast you need to act) as two separate questions, or you'll page someone at 3 AM for something a morning restart would have fixed.
The same database error in staging and in production are two completely different situations. If your paging setup treats them the same, the person who gets called at 3 AM for the staging one will stop trusting the pager.
If a CI job has thrown the same warning every single night for six months and nobody has ever acted on it, it's not an incident. It's noise. Filter it out at the source so it never reaches your on-call queue in the first place.
A low-priority incident still needs a deadline. 'We'll get to it' is how a ticket sits in a queue for three weeks. 'Someone owns this by Friday' is how it actually gets fixed.
Once you start labeling every incident as critical, your critical response stops meaning anything. The label that wakes people up has to stay rare enough that people still take it seriously when they see it.
Sending every low-priority incident to email and every critical one to a phone call probably cuts more midnight noise than weeks of fine-tuning your alerts. The channel itself is a filter.
Our virtual event "Reducing Alert Noise" is happening tomorrow!
It's a 30-minute live discussion, where we'll walk you through five ways Spike helps you reduce alert noise.
This is an open discussion. Ask us anything about alert noise, Spike’s features, or our roadmap.
We are hosting two sessions. Pick the one that suits your availability.
Session 1: Tuesday, April 28th at 11:00 AM CET
Register for 11:00 AM CET: https://t.co/h5XgI8XcYu
Session 2: Tuesday, April 28th at 11:30 AM EDT
Register for 11:30 AM EDT: https://t.co/gVm9WhgmDm
Come join us!
#virtualevent #webinar #alertnoise #alertfatigue #alerts
An escalation policy is the written-down answer to one question: if the first person we paged doesn't pick up, who do we call next, and how long do we wait? Teams that skip writing it down end up making that call at 3 AM by texting the group chat.
When we started writing competitor comparison posts at @SpikedHQ, I had a choice to make.
Most "alternatives" content on Google is the same. A list of tools, a few pros and cons, and some G2 ratings.
I didn't want to do it that way.
Before writing each post, I signed up for every tool on the list, tested each one, and took notes on what worked and what didn't.
I was also honest. If a competitor did something better than Spike, I said so.
My goal was to help the reader decide, not just push them toward our product.
It took longer to write this way. But readers trusted our content. And some even switched to Spike themselves.
P.S. Those are my detailed notes in the image.
Vercel had a security incident, and I've been thinking about how they handled it.
For those who missed it: an attacker compromised an employee's third-party AI tool, used it to get into their Google Workspace, and then into Vercel's systems.
Throughout the incident, Vercel published a bulletin and kept updating it continuously.
Every few hours, sometimes every few minutes, a new timestamped entry with what they knew, what they'd ruled out, and what customers should do.
When they engaged Mandiant, they said so. When they confirmed npm packages were safe, they said so. When customers needed to rotate env vars or turn on MFA, they spelled it out.
They even kept the channel open when they didn't have full answers yet.
At @SpikedHQ, this is how we think about incident communication. Not a nice-to-have, but how trust holds together while something breaks.
At @SpikedHQ, we run virtual events every month.
And now, we're scaling them up to twice a month.
For these events, we usually pick a topic, walk through it, and end with a Q&A session.
But that's not all. We also encourage people to ask questions throughout, and we answer them right there in the moment.
That's what makes them feel more like discussions than typical webinars. And honestly, that's why our users love them.
To stay in the loop on upcoming events, follow us here → https://t.co/CEmu2zqSzW