Ringkasan:
1. Clear cache app (10GB+)
2. Bersihin folder WhatsApp media (3-6GB)
3. Kosongin Gallery Trash (1-3GB)
4. Hapus ghost files app yang udah di-uninstall (1-5GB)
5. Hapus folder .thumbnails (1-5GB)
6. Samsung SysDump *#9900# (500MB-2GB)
Total potensi: 15-30GB. Tanpa hapus satu foto, satu chat, atau satu app yang lo pake.
Share ke yang tiap minggu dapet notifikasi "Storage almost full" tapi gak tau harus ngapain.
Storage HP Android lo penuh.
Lo hapus foto, hapus video, hapus app. Masih penuh.
Karena yang makan storage lo bukan file yang keliatan. Yang kebanyakan makan storage itu sampah TERSEMBUNYI yang Android gak pernah kasih tau ke lo.
Gue bersihin punya gue kemarin dapet 23GB balik tanpa hapus satu foto pun.
Gini caranya:
HOBI YANG DIAM-DIAM
BIKIN KAMU NAIK LEVEL
1. hobi bikin sehat
- jogging
- gym
- padel
- badminton
2. hobi bikin pintar
- dengerin podcast
- baca buku
- belajar skill baru
- ikut kelas online / bootcamp
3. hobi bikin kreatif
- bikin konten
- menulis
- foto / video
4. hobi bikin kaya
- freelance
- personal branding
- bangun bisnis
- investasi
5. hobi bikin tenang
- meditasi
- journaling
- ngumpul bareng keluarga
6. hobi bikin mual
- dengarin wowo pidato
- dengarin mulyono ngoceh
- lihat gambar fufufafa
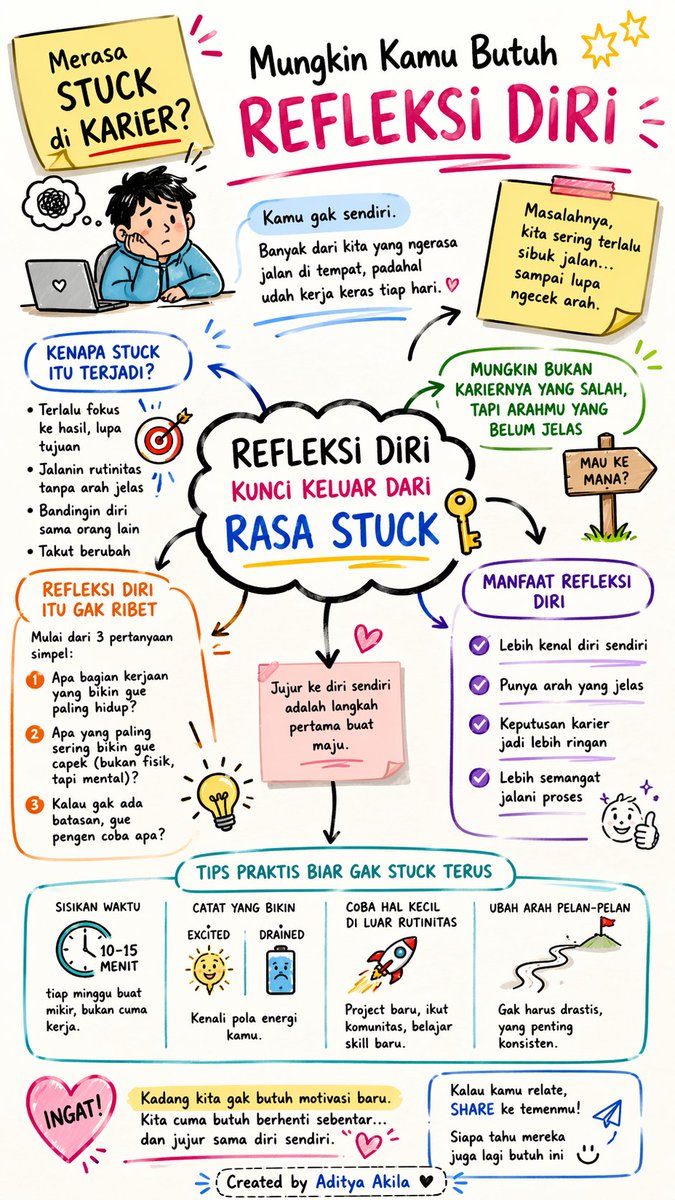
MERASA STUCK DI KARIER?MUNGKIN KAMU BUTUH REFLEKSI DIRI
Pernah gak sih, kamu lagi kerja… tapi rasanya kayak autopilot? Datang, ngerjain task, pulang. Repeat. Tapi di dalam hati ada suara kecil: “Ini beneran yang gue mau?”
Kalau iya, kamu gak sendirian.
Kenapa Perasaan “Stuck” Makin Sering Muncul?
Di fase tertentu (apalagi umur 20 akhir–30an), standar hidup kita berubah. Dulu mungkin ngejar “naik jabatan” atau “gaji naik”. Sekarang… mulai mikir: “Kerjaan ini bikin gue berkembang gak ya?”
Masalahnya, kita sering terlalu sibuk jalan… sampai lupa ngecek arah.
Akhirnya stuck bukan karena gak mampu. Tapi karena gak pernah berhenti buat refleksi.
Mungkin Bukan Kariernya yang Salah, Tapi Arahmu yang Belum Jelas
Coba bayangin ini:
Kamu lagi naik ojek online. Motornya kenceng, drivernya jago. Tapi kamu gak pernah kasih tahu tujuan.
Mau sekencang apa pun… tetap gak akan sampai.
Begitu juga karier.
Banyak orang kerja keras, tapi gak pernah tanya:
“Gue sebenarnya pengen jadi apa?”
“Skill apa yang mau gue kuasai?”
“Gue kerja ini karena mau, atau cuma kebawa arus?”
Refleksi Diri Itu Bukan Ribet, Tapi Jujur
Gak perlu journaling panjang atau retreat ke gunung.
Mulai aja dari 3 pertanyaan simpel:
1. Apa bagian kerjaan yang bikin gue paling hidup?
2. Apa yang paling sering bikin gue capek (bukan fisik, tapi mental)?
3. Kalau gak ada batasan, gue pengen coba apa?
Dari situ, kamu mulai lihat pola.
Tips Praktis Biar Gak Stuck Terus
* Sisihkan 10–15 menit tiap minggu buat mikir, bukan cuma kerja
* Catat hal yang bikin kamu excited vs drained
* Coba hal kecil di luar rutinitas (project baru, belajar skill baru)
* Jangan takut mengubah arah pelan-pelan, gak harus drastis
Kadang kita gak butuh motivasi baru. Kita cuma butuh berhenti sebentar… dan jujur sama diri sendiri.
Karena bisa jadi, kamu bukan stuck.
Kamu cuma belum sempat dengerin diri sendiri.
Kalau kamu lagi di fase ini, share ke orang yang mungkin ngerasain hal sama. Siapa tahu… mereka juga lagi butuh “pause” hari ini.
CPU vs GPU vs TPU vs NPU vs LPU, explained visually:
5 hardware architectures power AI today.
Each one makes a fundamentally different tradeoff between flexibility, parallelism, and memory access.
> CPU
It is built for general-purpose computing. A few powerful cores handle complex logic, branching, and system-level tasks.
It has deep cache hierarchies and off-chip main memory (DRAM). It's great for operating systems, databases, and decision-heavy code, but not that great for repetitive math like matrix multiplications.
> GPU
Instead of a few powerful cores, GPUs spread work across thousands of smaller cores that all execute the same instruction on different data.
This is why GPUs dominate AI training. The parallelism maps directly to the kind of math neural networks need.
> TPU
They go one step further with specialization.
The core compute unit is a grid of multiply-accumulate (MAC) units where data flows through in a wave pattern.
Weights enter from one side, activations from the other, and partial results propagate without going back to memory each time.
The entire execution is compiler-controlled, not hardware-scheduled. Google designed TPUs specifically for neural network workloads.
> NPU
This is an edge-optimized variant.
The architecture is built around a Neural Compute Engine packed with MAC arrays and on-chip SRAM, but instead of high-bandwidth memory (HBM), NPUs use low-power system memory.
The design goal is to run inference at single-digit watt power budgets, like smartphones, wearables, and IoT devices.
Apple Neural Engine and Intel's NPU follow this pattern.
> LPU (Language Processing Unit)
This is the newest entrant, by Groq.
The architecture removes off-chip memory from the critical path entirely. All weight storage lives in on-chip SRAM.
Execution is fully deterministic and compiler-scheduled, which means zero cache misses and zero runtime scheduling overhead.
The tradeoff is that it provides limited memory per chip, which means you need hundreds of chips linked together to serve a single large model. But the latency advantage is real.
AI compute has evolved from general-purpose flexibility (CPU) to extreme specialization (LPU). Each step trades some level of generality for efficiency.
The visual below maps the internal architecture of all five side by side.
👉 Over to you: Which of these 5 have you actually worked with or deployed on?