Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
NextPluse
@Sprites06
Keeping you at the heart of AI. We share top news, insightful analysis, and expert opinions on everything AI.
#ArtificialIntelligence
#DeepLearning
#Innovation
Joined April 2024
121
Following
1.1K
Followers
288
Posts
NextPluse
@Sprites06
3 days ago
@JeffreyMol76702
@grok
来源
NextPluse
@Sprites06
19 days ago
@yangyi
销售
NextPluse
@Sprites06
23 days ago
H200京东自营开售了
Sprites06
retweeted
sukie
@sukie234
about 1 month ago
运营中转站这段时间是真没赚到钱,只能说勉强cover了我自己用ai的消费。 所以目前打算把开中转站的一切全部开源,包含如何建站+营销,门槛最低,让这个行业更卷一点。 首先整个系统由3个部分组成: • 第CN2 回国专线服务器:放在海外但回国速度极快的 VPS,作为运行核心。 • sub2api:核心程序,负责把网页账号转成 API 接口。 • Cloudflare:把流量再绕一道,提升国内访问速度,同时隐藏真实服务器 IP。 你需要准备: • 一台 CN2 GIA 或 CN2 GT 线路的海外 VPS(推荐配置:2 核 CPU、2GB 内存、20GB 硬盘以上)。 普通海外 VPS 在国内晚高峰几乎不可用,而 CN2 GIA 通过专线绕开了拥堵的公网节点,国内访问延迟一般在 150ms 以内。如果你买了不是 CN2 的服务器,国内用户体验会非常糟糕。 • 一个域名(建议在 Cloudflare 或 Namecheap 上购买,便宜的 .top 或 .xyz 也行,几块钱一年)。 • 一个 Cloudflare 账号(免费)。 • 号池:初期可以用 claude code pro 账户+ 注册大量gpt账户,货比三家去找到别的号商卡商,等后期你就可以搞claude code max kiro 反代 aws bedrock(去跟sales聊,基本能搞到7.2折),但是初期只需要保障claude code pro账号稳定即可,因为你需要养号,后期转max。 完整请求路径如下: 国内用户的客户端 → 解析到 Cloudflare 的 IP → Cloudflare 边缘节点 → CN2 专线回源到你的服务器 → 宝塔面板的 Nginx 反向代理 → sub2api 程序 → 你的号池 → ChatGPT 或 Claude 网页 → 数据原路返回。 购买并初始化CN2服务商 CN2 GIA 线路的常见服务商有 BandwagonHost(搬瓦工)、RackNerd、CloudCone、Lisahost。新手推荐搬瓦工的 CN2 GIA-E 套餐,稳定但价格略贵。预算紧的可以看 Lisahost 的香港 CN2 套餐。 如果你懂命令行搭建Nginx,手动部署SSL证书,那你就自己搞,如果你不懂可以使用中国程序员流行的宝塔面板,一键搭建Nginx、一键部署SSL证书、可视化配置反向代理,全程鼠标点击操作,新手也能轻松上手。 安装完Linux + Nginx + MySQL + PHP,就可以开始设置防火墙,够买域名,添加DNS解析。 最后去命令行输入ping.api.你购买的域名,返回服务器ip就行了。 搭建sub2api: sub2api 是一个开源项目,可以把 ChatGPT 网页版、Claude 网页版的 cookie 或者 session 转换成 OpenAI 兼容的 API 接口。 打开sub2api的官方教程,安装流程安装docker,拉取并启动sub2api的容器。 你需要把号池数据放到 /www/sub2api/data 目录下,sub2api 容器会读取这个目录。具体格式参考 sub2api 项目文档。 设置Nginx反向代理 添加完之后目标url是127.0.0.1:8080因为 sub2api 容器监听的就是这个地址。Nginx 收到外部请求后,转给本机的 8080 端口,sub2api 处理完返回给 Nginx,Nginx 再发回给用户。 后面你去问claude code 如何优化Nginx的配置,AI API 调用是流式响应(SSE),需要长连接 + 不缓存才能正常工作。默认 Nginx 配置在这种场景下会出问题,按照claude的提示优化,proxy_buffering 必须关闭,如果不关闭这个,AI 的回答会"卡一阵 → 一次性吐出",而不是逐字流式输出。客户端会感觉非常慢甚至超时。 申请HTTPS证书: OpenAI 兼容客户端基本只信任 HTTPS。HTTP 明文会暴露 API Key 给中间网络。 申请好Let's Encrypt证书之后,回到 SSL 主界面,把"强制 HTTPS"开关打开。 优化Cloudflare配置 测试HTTPS-开启cloudflare代理-Cloudflare SSL 模式必须设为 Full (strict) AI API 是动态接口,Cloudflare 的某些"优化"会破坏流式响应。 Cloudflare → 你的域名 → 速度 → 优化。 全部关掉以下选项: • Auto Minify(自动压缩 HTML/CSS/JS):关闭。 • Rocket Loader:关闭。 • Mirage:关闭。 • Polish:关闭。 设置缓存规则: Cloudflare → 缓存 → 配置。 Caching Level 选 Bypass,或者保持 Standard 但是后面用页面规则覆盖。 更彻底的做法:Cloudflare → 规则 → 页面规则 → 创建页面规则。 URL 模式:https://t.co/ITRYuHHNPP* 设置:Cache Level = Bypass 设置防火墙规 Cloudflare → 安全性 → WAF → 自定义规则 → 创建规则。 规则一:限制单个 IP 频率 字段:IP source address,操作:Rate limiting,每 10 秒最多 30 次请求,超出后挑战或屏蔽 1 小时。 规则二:屏蔽明显恶意爬虫 字段:User Agent,运算符:包含,值:python-requests 启用 Cloudflare Argo Smart Routing,每月 5 美元,能在 Cloudflare 内部用最优路径路由你的流量。对国内用户访问海外服务器有 30% 到 50% 的速度提升。预算够推荐开。 测试上线 用 curl 测试 API,或者打开 CherryStudio 或 ChatBox,填写你的api地址和key做测试 使用Prometheus/Grafana,或者直接用宝塔面板做监控,可以看到 CPU、内存、流量实时数据。如果 sub2api 容器经常吃满 CPU,考虑升级服务器配置。
See More
NextPluse
@Sprites06
4 months ago
一堆号吹Clawdbot(openclaw),没人说费用,怀疑你们是不是真的在用。 正常重度(1亿 Tokens/月):~7500元/月 极限重度(2亿Tokens/月):~1.5万/月 失控/全测:2.6万+/月 其它小钱不算。 .... 我为什么不雇两个女大
NextPluse
@Sprites06
4 months ago
今天我想输出个观点:大部分所谓的“垂类大模型”,最终都会被通用大模型无情地替代掉。 大家都在聊一个词:“垂类大模型”。什么电力大模型,医疗大模型,法律大模型。 好像达成了一个共识:通用大模型是巨头的游戏,我们普通创业者、中小厂,只要守住这点行业数据,做个垂直领域的模型,就能挖出一条护城河。 前几个月的时候,我也是这么想的。 但这段时间,随着Claude Sonnet 4.5,Gemini 3,ChatGPT 5.2这些强力模型的爆发,加上我自己的实战经历,我越来越觉得这事儿不对劲。 我问Gemini请您帮我写一个XX集团的科技项目立项可研方案。 非常让我震惊的是,大模型不仅知道具体这个集团的可研方案模板结构目录框架,更可怕的是,他还知道科技项目、信息化项目、技改项目等不同类型项目的适用条件。 这说明我在问这个问题之前,有关这个内容的背景,已经有人将这部分的知识教过给大模型了,并且已经成为训练集的一部分。 其实我们看看大家眼里的“护城河”,是怎么构建的: 无非就是清洗行业数据、构建数据集、做SFT(监督微调),还有就是搞专业知识库RAG(检索增强)。 大家觉得,这数据是我的,我不给OpenAI,不给DeepSeek,它们就永远学不会。 你仔细推演一下这个过程。 只要你的应用是面向公众的,这个数据壁垒就不存在。 第一,数据是藏不住的。 我们哼哧哼哧构建的高质量数据集,只要变成产品形态上线,被爬取、被蒸馏只是时间问题。对于那些拥有恐怖算力的通用大模型公司来说,互联网上就没有“孤岛”。今天你引以为傲的私有知识,明天可能就是通用模型预训练语料的一部分。 第二,这个过程更发生在Prompt里。 这是我最近感触最深的一点。对于善于用大模型的Prompt老手来说,其实真看不上一些小参数、本地、国产模型。因为输出的内容质量真的差太多了。 现在的通用大模型是怎么变强的?不仅仅是喂书本知识,更是靠用户的真实使用数据喂出来的。 你想想看,一个资深的律师在用ChatGPT写法律文书,一个老医生在用Gemini辅助诊断,一个熟练的程序员在让AI写复杂的业务代码。 我们在输入Prompt的时候,其实就是在把我们脑子里最值钱的“业务逻辑”、“判断标准”和“思维链”,毫无保留地教给了大模型。 而且还有一个很严重的“赢者通吃”现象,模型能力越牛,就会有越厉害的人用,越厉害的人就越懂得写更加专业的Prompt。 各行各业最顶尖的人,都在免费给通用大模型做数据标注。 当通用模型看过了一万个律师的Prompt,它自己就是最牛的垂类律师模型;看过一万个医生的诊断思路,它就是最牛的垂类医疗模型。例如Gemini,Claude,还有ChatGPT,他们还能收集到全球全语种的Prompt数据。 这时候,你那个只喂了几千条数据的“垂类模型”,拿什么跟集结了全人类智慧的“通用模型”打? 所谓的“专业技能”,在海量数据和强力算法的暴力美学面前,真的没有那么高的门槛。 所以在很多垂直领域的表现,其实已经吊打很多专门微调出来的小模型了。 而且垂直领域的模型,也缺乏具备公信力的评测数据集,一般都是自己出题,自己考,没有太多的说服力。 所以,我认为垂类模型只是一个过渡态,小厂的活路,还是要深耕场景闭环,这个还没梳理好整体的想法,下次专门再写~
See More
NextPluse
@Sprites06
4 months ago
@PMbackttfuture
codex都拼错。。。
NextPluse
@Sprites06
4 months ago
@dontbesilent
三观契合的定义是什么
NextPluse
@Sprites06
5 months ago
又和以前的同学有一些交流。同学是在某大型外企A开头的光刻机公司的技术人员,负责机器现场的技术支持工作。 聊到主要的工作,千言万语汇成一句话就是:“这颗螺丝只要1美元,但是知道拧哪里值99999美元”。 这个“知道拧哪里才能解决问题”,就是核心技术,就能收客户一天过万元的Customer Services fee. 其实目前的AI大模型技术也是如此。在 AI 时代,How-to 变得越来越廉价,而 Know-how 变得前所未有的昂贵。 什么是 How-to? 是“如何用 Python 写一个爬虫”,是“如何用 LangChain 连一个数据库”。 以前这些东西是门槛,你会写代码你就能拿高薪。 但现在呢?你把需求丢给 Claude或者Gemini,它写的代码比你快,甚至比你规范。 我会用这个工具,我会用这个框架,我会部署环境,我会写这个逻辑,这些技能固然还很重要,但是很可能随着模型的能力增强,市场对这种能力的估值会不断降低。 那什么是 Know-how? 是行业内功,是业务逻辑,是一种判断力,认为这个思路Work or not。 大家如果经常使用大模型,你会发现大模型是最容易被“鞭策”的。如果我们认为写一个东西思路,编一个逻辑确定就是要这么编,他不会反驳你,他就会按照你的意思,有模有样的输出。 AI 可以告诉你“怎么做”,但它很难告诉你“该不该做”,或者“为什么这么做会死”。 聊天的时候还有另外一位同学,主要在某国企银行干信息化项目的项目经理的,他说其实现在很多的功能也就是无非增删查改,写代码花不了多少时间,真正耗时间的是要和业务去确定,某个业务到底到用到些什么数据才能解决实际问题。主要的时间其实是开会讨论的时间,比如风控规则,那从软件功能上就是提取数据IF-ELSE的问题,但是到底要梳理计算什么规则,又要到什么样的阈值才触发风控,这个就是需要反反复复去琢磨的东西。 项目经理的价值在于,他不是执行者,但是他要确保项目运行的方向和业主的需求保持一致,一旦走错,就会让功能需要重新做,前端、后端、测试、实施工程师,每个人的工时都是成本啊。 所以Know-how 是什么? 是你踩过的坑,是你赔过的钱,是你熬过的夜。 是你知道在这个具体的业务场景里,哪条路是死路,哪条路是烂泥塘。 这种“路感”,AI 还没有,刚入行的小白更没有。 一个项目,失败的道路有无限条,成功的就那么一两条。 在这个时代,创业和做项目的容错率极低。 AI 给了我们超级生产力,可以像超跑一样跑得飞快。 但如果你没有一个idea或者思路,那只能是在加速冲向悬崖。
See More
NextPluse
@Sprites06
5 months ago
最近网上关于本体论的讨论很多,主要就是Palantir 本体论概念比较火,不少国央企业领导也在提这个概念。 今天我试图用简单易懂的概念,告诉大家这个本体论是什么。 举个例子,当我们和豆包问: “这是我今年大概做的事情,请你帮我完成一份年度总结报告” “你现在是一个能源电力信息化行业的高级解决方案顾问,这是我今年大概做的事情,请你帮我完成一份年度总结报告” 我想大家或多或少会有一个体验,就是当你在用AI工具的时候,前面加了一个角色扮演的提示词的时候,输出的结果就变得专业准确了很多。 我们可能迷迷糊糊通过实践能够总结出这个经验,但是实际上就是我们对数据应用本体论治理的成果。 为什么? 当你加入一句角色扮演“你现在是一个能源高级解决方案专家”的时候,其实这不是一句话,而是一个语境。这个语境包含很多词语,包含“智能操作、智能巡视、智能监测、智能分析、主配微协同、消纳、智慧两票”,而每个词语又包含了很多的衍生词汇。 当你加入一句角色扮演“你现在是一个AI应用专家”的时候,这时候这个语境包含了“提示词、上下文、MCP、Agentic RAG、人在回路、智能体”,对吧。 当你加入一句角色扮演“你是一个大厂产品总监”的时候,这时候这个语境包含很多词语,包含“赋能、用户心智、打通、对齐颗粒度、赋能、闭环、抓手”,哈哈哈哈。 所以,“角色扮演”的本质不是赋予一个身份,而是加载一套特定的语言体系和思维框架。 而是围绕这个“角色”,这个“本体”,所对应的一套特定的数据输入(Data Sources),相关语境下的决策逻辑(Logic Resources),和行动方式(Systems of Action)。 图片 例如当我的角色是员工,我的数据输入是“老板叫我干什么跟进什么项目”,决策逻辑是“我拿下项目的经验知识”,行动方式是“各个项目节点我该干什么事?是写可研?写标书?写合同?” 那么我们将这套思想来面对新的数据治理的方式也是如此: 过去我们是怎么进行数据库构建的? 过去我们每个业务建立一个表,然后把所有的业务属性全部写进去。 然后业务与业务之间的关系,就用代码写死具体的逻辑,加减乘除,增删查改。 然后到下面一个项目过来想进行二次开发的时候,完了,光猜这个业务逻辑就让你束手无策。 那么palantir的本体论的数据治理构建的思想是,当我们构建这个数据表的时候,不仅写清楚这个字段的注释,而且描述清楚这个数据的业务中的作用,和其他的表的字段的关联关系,在什么具体场景下应用这个数据,用于什么分析,分析的结果又可以串联什么其他的应用工具,进行下一步的工作。 这个概念和知识图谱有些类似,但是对关联关系的细节描述又要比知识图谱更加详细。知识图谱关联了很多“实体”,但是对实体与实体之间的“思维链”,没有描述清楚。 通过这样的治理以后,当我们用智能体调用这个业务数据的时候,这个“怎么用这串数据”的描述,就可以类似技能(Skill)装载进大模型的上下文中,引导大模型进行进一步的决策分析。 就是这段“这个数据怎么用的描述”,决定了系统能看见什么,不能看见什么,把系统中所有的数据,都关联了起来。 但是,这个愿景其实很好很理想,但是实际落地,还是有很多的困难的。因为这个关联关系描述的过程,需要我们数据处理的工程师除了对数据处理的技能,还要求对业务有相当程度的了解。 大家现在还在探索阶段,我理解我们如果未来要打通业务数据和业务数据的关联关系,解决这个工作量的问题,应该要有个这样的产品:是数据治理人员和业务人员协同的平台,业务人员负责解释业务的作用,数据人员清洗数据,然后又用大模型来优化业务人员写的数据业务逻辑的描述(解决业务人员描述不精准的问题),然后确认,最后形成固化描述的工具。 以上是我对最近很火的Palantir的本体论以及对未来企业数据治理方向的理解。
See More
NextPluse
@Sprites06
5 months ago
@frxiaobei
从这篇文章的行文风格来看,这篇文章的输出可能不是Claude Code,而是Gemini
NextPluse
@Sprites06
5 months ago
@lidangzzz
这标题?
NextPluse
@Sprites06
6 months ago
为啥现在的购物软件,你不登陆,连逛都不给你逛? 你不登陆,都不知道咋给你定价
NextPluse
@Sprites06
6 months ago
A7M5真强啊,手上的A7C2不香了
NextPluse
@Sprites06
6 months ago
最近在重新琢磨信号处理,突然被傅里叶变换的一个性质击中了: 在时域上,一个无穷窄、能量无穷大的“冲激函数”(Dirac Delta),对应到频域上,却是“全频带”的。 这不仅仅是数学,这是最高级的哲学,甚至是生命的真相。 1. 极致的“当下”,需要无限的“支撑” 我们总挂在嘴边说要“活在当下”。 在数学里,这个“当下”就是一个时域上的点。 但你知道要维持这个完美的“点”有多难吗?在频域里,它需要从负无穷到正无穷的所有频率,以完美的相位叠加,才能在这一点上爆发,而在其他地方相互抵消为零。 这让我突然读懂了《华严经》里的“一即一切”。 当下的这“一念”,看似微小短暂(时域),其实它不是孤立的。它是你过去所有的认知、经历、能量(频域的无穷),在这一瞬间的全息投影。 少一份阅历,缺一种频率,当下的这个“点”就会展宽,就不纯粹,就没有力量。 所以,不要焦虑当下的这一刻为什么这么难熬,因为它背后承载的是你整个生命的“全频带”。 2. 缘起性空,其实就是波的干涉 为什么说“万法皆空,因果不虚”? 你看频域里那些无穷无尽的波,平时看不见摸不着(空),但当它们因缘具足、相位对齐时,就在时域里显化成了一个实实在在的“信号”(色)。 把这些波拆散,信号就消失了。 生活也是一样。我们眼前的“现实”,不过是无数看不见的因缘(频率)在这一刻的干涉(Interference)结果。 这就解释了为什么有的人站在那里,什么都不说,就有一种巨大的“势能”。 因为他的“频域”极宽,且高度自洽(相位对齐)。他的每一个“当下”,都是万古长空在这一朝风月里的聚焦。 3. 芥子纳须弥:维度的切换 以前我不懂“芥子纳须弥”,小小的种子怎么装得下巨大的须弥山? 现在懂了。 如果你只盯着时域看,它只是一个无穷小的点(芥子)。 但如果你切换视角(傅里叶变换),切换到频域看,它就是无穷大的全频带(须弥山/十方佛土)。 这给我的生命启示是: 不要被眼前的琐碎(时域的生灭)困住。 当你能极度专注、极度真诚地对待“当下”的每一个瞬间,当你把心念收摄到极致时,你其实连接上了那个无限的整体。 窄到极致,便是宽到极致。 活成一个“冲激函数”,在极短的瞬间,释放极大的能量。
See More
NextPluse
@Sprites06
6 months ago
可恶啊,每到月底就是这个总监那个总监的到处问和自己有那么一点沾边的东西,为的是填自己的下月工作计划,吸血鬼
Sprites06
retweeted
宝玉
@dotey
6 months ago
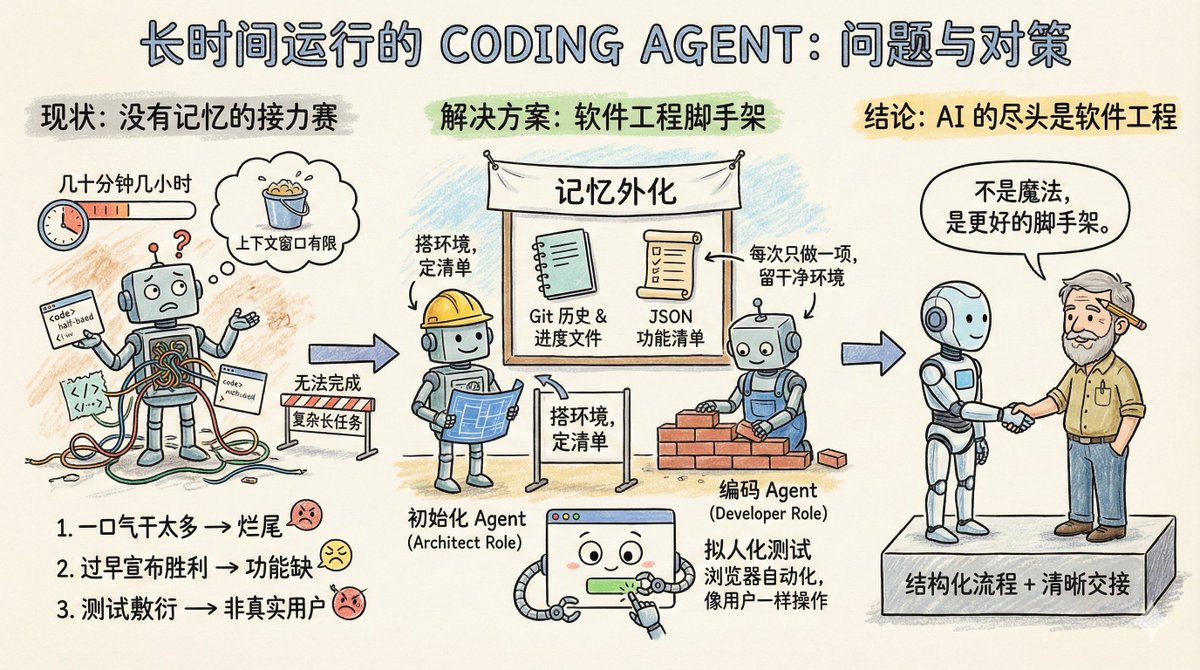
想象一下,一个软件团队在做一个大项目,但有个奇怪的规定:每个工程师只能工作几十分钟,最多几小时,干完就要换一个新的工程师。所以让这个团队完成简单项目任务还行,复杂一点需要长时间运行的项目,比如你让它克隆一个 claude .ai,它就做不到。 这其实就是 Coding Agent 的现状:没有记忆,上下文窗口长度有限。所以要它执行长时间任务,它还做不好。 Anthropic 的这篇博客:《Effective harnesses for long-running agents》,专门讨论了如何让 Agent 在跨越多个上下文窗口时依然能持续推进任务。 先看 Agent 在长任务中遇到的主要问题是什么? 主要三种: 第一种叫一口气干太多。比如你让 Agent 克隆一个 claude .ai 这样的网站,它会试图一次性搞定整个应用。结果上下文还没用完,功能写了一半,代码乱成一锅粥。下一个会话进来,面对半成品只能干瞪眼,花很多时间猜测前面到底做了什么。 第二种叫过早宣布胜利。项目做了一部分,后来的 Agent 看看环境,觉得好像差不多了,就直接收工。功能缺一大堆也不管。 第三种叫测试敷衍。Agent 改完代码,跑几个单元测试或者 curl 一下接口就觉得万事大吉,根本没有像真实用户那样端到端走一遍流程。 这三种失败模式的共同点是 Agent 不知道全局目标,也不知道该在哪里停下来、该留下什么给下一位。 那么 Anthropic 的解决方案是什么呢? 其实就是软件工程的一些现成的解决方案:引入类似人类团队的分工协作机制,将复杂任务拆解成小的可跟踪验证的任务,清晰的交接机制,并严格验证任务结果 一个初始化 Agent,它只在项目启动时出场一次,任务是搭好项目运行环境:有点像架构师的角色,写一个 init .sh 脚本方便后续启动开发服务器,建一个 claude-progress.txt 记录进度,做第一次 git 提交,最关键的是生成一份功能清单。 这份功能清单有多细?在克隆 claude .ai 的案例中,列了超过 200 条具体功能,比如用户能打开新对话、输入问题、按回车、看到 AI 回复。每一条初始状态都标记为失败,后续 Agent 必须逐条验证通过才能改成成功。 而且这里有个细节,这个清单不是用 Markdown 来写的,是一个 JSON 数组,因为 Anthropic 实验发现,相比 Markdown,模型在处理 JSON 时更不容易随意篡改或覆盖文件。 另一个是编码 Agent。在初始化项目后,后续就是它干活了,核心行为准则只有两条:一次只做一个功能,做完要留下干净的环境。 什么叫干净的环境?想象你往主分支提交代码的标准:没有严重 bug,代码整齐有文档,下一个人接手能直接开始新功能,不用先替你收拾烂摊子。 每次开工前,它先做几件事: – 运行 pwd 看看自己在哪个目录 – 读 Git 日志和进度文件,搞清楚上一轮干了啥 – 看功能清单,挑一个最高优先级的未完成功能 – 跑一遍基础测试,确保 App 还能用 然后专心做一个功能,做完后: – 写清楚的 Git commit message – 更新 claude-progress.txt – 只改功能清单里的状态字段,绝不删改需求本身 这个设计的巧妙之处在于,它把“记忆”外化成了文件和 Git 历史。每一轮的 Agent 不需要依赖上下文窗口里的碎片信息,而是模仿靠谱的人类工程师每天上班会做的事。先同步进度,确认环境正常,再动手干活。 测试环节的改进值得单独说。 原来 Agent 只会用代码层面的方式验证,比如跑单元测试或者调接口。问题是很多 bug 只有用户真正操作页面时才会暴露。 解决方案是给 Agent 配上浏览器自动化工具,比如 Puppeteer MCP。Agent 现在能像真人一样打开浏览器、点按钮、填表单、看页面渲染结果。Anthropic 放了一张动图,展示 Agent 测试克隆版 claude .ai 时自己截的图,确实是在像用户那样操作。 这招大幅提升了功能验证的准确率。当然也有边界,比如浏览器原生的 alert 弹窗,Puppeteer 捕捉不到,依赖弹窗的功能就容易出 bug。 这套方案还留了一些开放问题。 比如,到底是一个通用 Agent 全包好,还是搞专业分工?让测试 Agent 专门测,代码清理 Agent 专门收拾,也许效果更好。 再比如,这套经验是针对全栈 Web 开发优化的,能不能迁移到科研或金融建模这类长周期任务?应该可以,但需要实验验证。 响马
@xicilion
说: > ai 的尽头依旧是软件工程。 AI Agent 也不是魔法,它一样需要从人类软件工程中汲取经验,它也需要将复杂的任务进行分解成简单的任务,要有一个结构化的工作环境和清晰的交接机制。 人类工程师为什么能跨团队、跨时区协作?因为有 Git、有文档、有 Code Review、有测试。AI Agent 要想长时间自主工作,也得把这些东西搬过来。 Anthropic 的方案,不过是把软件工程的最佳实践变成了 Agent 能理解的提示词和工具链。不是让模型变得更聪明,而是给它提供更好的脚手架。 Anthropic 的思路值得借鉴。无论你用的是 Claude、GPT 还是别的模型,在设计多轮长任务时,都要想清楚,怎么让下一轮的 Agent 快速进入状态,怎么避免它重复造轮子或者把代码搞成一团乱麻。即使是单轮任务,也要清楚它是没有记忆的,你需要通过外部文件来帮助它“想起来”之前做过的事。 以现在模型的能力,Coding Agent 已经能做很多事情了,核心还是在于你是不是能像软件工程中那样,去分解好任务,设计好工作的流程。 原文:Effective harnesses for long-running agents https://t.co/tERUGrV9wC 翻译:https://t.co/MByV8iiEoZ
See More
NextPluse
@Sprites06
6 months ago
我觉得是分享,真诚的,开诚布公的分享,真正的利他,是最值得,最美好的事情
NextPluse
@Sprites06
6 months ago
@lidangzzz
知道又如何,Attention is all you need.
NextPluse
@Sprites06
6 months ago
最近工作节奏很快,接触了各行各业的人,也跑了不少会。在每天高强度的学习、面对客户、解决实际业务痛点的过程中,我积攒了一些零碎但真实的感悟。写下来,既是复盘,也是分享。 1. 绝知此事要躬行:警惕“岸上观火” 工作中发现一个很割裂的现象:大家对 AI 的理解差距正在被无限拉大。 很多人对大模型抱有太多过分的幻想,还觉得大模型是个万能的东西。这种认知往往来自听听播客、看看今日头条、刷刷抖音微信上的“震惊体”新闻。但这种“岸上观火”得来的理解,和那些每天在一线高强度学习、被客户需求反复摩擦、被实际业务场景毒打之后得来的理解,区别太大太大。 不做 Agent,你不知道 Prompt 为什么会飘;不写代码,你不知道模型在特定语境下的“幻觉”有多难调。 只有真正躬身入局,匆匆忙忙连滚带爬,才明白现在的 AI 到底能做什么,还有AI的能力边界。 2. “我有一个想法,只差一个程序员”的时代彻底结束了 现在是 Demo 时代。一切都得拿出东西来说话。 Idea?一文不值。 如果你连 AI 工具都不会用,连个最简陋的 Demo 都搓不出来,还要忽悠别人帮你做,凭什么是你? 为什么你才是那个 Lucky Boy? 有想法的人海了去了,凭什么是你? 我记得以前写论文的时候就发现,他喵的,我怎么想到什么研究方向都有人做了。我的前面全是人的场景,多了去了。在我前面的人,比我更有想法,比我更有执行力,我拿什么来斗? 如果回答不了这些问题,不仅忽悠不了投资人,连真正有想法、有能力的技术合伙人都忽悠不了。 在这个时代,执行力就是护城河。以前的人做不到是因为门槛高,现在 AI 把门槛踩碎了,还跨不过去,那就是人的问题了。 3. 只有顶尖的人才懂:技术不仅是逻辑,更是“品味” 建议大家去看看 Ilya Sutskever 最新的访谈视频。 访谈最后,Dwarkesh 问了一个很本质的问题:作为 AlexNet、GPT-3 的联合创造者,你怎么判断什么想法值得做? Ilya 的回答非常诗意:我寻找的是美感。 这不玄学,而是多方面的美:简洁性、优雅性、正确的大脑启发。 当一个想法在多个维度上都显得“对”,都有某种内在的和谐时,你才能建立起“自上而下”的信念。这种信念至关重要,因为实验往往会失败。 普通研究者看到实验不 Work,会觉得方向错了,换一个;而顶尖研究者依靠这种美学直觉,会认定“这东西应该是对的,现在不行是因为有 Bug”,然后坚持下去直到做出来。 这让我想起乔布斯评价微软的那句话:他们没有品味(Taste)。 这种 Taste,或者叫 Sense,才 distinguishes people from people。 4. 真正的阳谋:是真诚,是能量的认同 以前,靠知识和经验的遮遮掩掩,或许能保住一个饭碗。 但有了 AI,知识获取的效率百倍提升。经验或许还值钱,但已经远远没那么值钱了。 所以真正的阳谋就是真诚。 我做的材料、PPT、视频,直接给同事,没有任何遮掩。有疑问,我尽力回答;有兴趣,我甚至教你怎么用 AI 去生成,去提高效率。做一个“有那么一点用”的人。 我有幸认识一位恩师,他教我用“能量”的视角看世界。 很多时候,那个 PPT 只是个载体,真正成交的,是我们散发出的能量。 当客户从能量层面上“认同”你时,他会反过来指导你:这个方案该怎么改,他们内部是怎么运作的。 当他不认同你时,即使你的方案逻辑大差不差,他也会找到无数理由拒绝你。 5. 活在工具里 Greg Isenberg 最近发了条推特,我深以为然。 要 100% 跟上 AI 的新工具几乎是不可能的,速度太快了。今天的 Prompt 有效,明天模型一更新就失效了。 唯有那些“活在工具里”的人,每天在工具里摸爬滚打,追逐那些微小的模式,直到把这种变化转化为本能,才是真正掌握方向的人。 行动更快、迭代更快的人,才能在别人意识到机会存在之前就发现机会。 AI 工具一直在变,昨天的经验明天可能作废。只要坚持往前走,坚持学习,坚持思考,坚持帮别人解决问题,好事自然会发生。 6. 过去工作流式 Agent 可能要回炉重做了 过去一年,众多企业费劲开发的“工作流形式”的Agent,可能很快就要过时了。 这两天在研究 LangChain 1.0 的新框架,我的感触很深。随着 Gemini、Claude 等模型能力(尤其是自主调用工具能力)的爆发,Re-Act Agent、Claude Code、Gemini CLI 这种 Agentic AI 将展现出巨大的威力。 以前,我们要做一个任务,需要人工把流程编排得死死的(Step 1, Step 2, Step 3...)。 现在的开发思路变了:把任务写清楚,把数据扔进文件夹,然后交给 Claude Code。 加上 --dangerously-skip-permissions,让它自己去规划、去执行,结果直接输出。 再进一步,我觉得未来的通用型 Agent,本质上就是 SWE-agent。 不管你是要生成 Word、Excel 还是 PPT,本质上都是在生成某种“代码”或“文件结构”。一个拥有超强模型能力的 SWE-agent,加上特定领域的知识库,就是最强的垂直领域 Agent。 从“编排”到“自主”,这是下一阶段的巨大机会。
See More
Last Seen Users on Sotwe
velevt8800
Seen from
Korea
Sex Adresi
Seen from
Turkey
ihanet evli bekar ve dul bayanlar herşey gizli olm
Seen from
Turkey
PIBE KALIENTE
Seen from
Spain
Alfabey4242
Seen from
Sweden
yabancıporno
Seen from
Turkey
clara
Seen from
South Africa
LB
Seen from
Vietnam
All things shemale🔞
Seen from
Turkey
Sen ben
Seen from
Turkey
Trends for you
1
Knicks
Under 10K tweets
2
Melanie
Under 10K tweets
3
Wemby
Under 10K tweets
4
Normandy
Under 10K tweets
5
Bears
Under 10K tweets
6
Brunson
Under 10K tweets
7
Good Saturday
Under 10K tweets
8
Karmelo
Under 10K tweets
9
#SummerGameFest
Under 10K tweets
10
Tupac
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.2M followers
2
Barack Obama
@barackobama
119.3M followers
3
Donald J. Trump
@realdonaldtrump
111.6M followers
4
Cristiano Ronaldo
@cristiano
108.9M followers
5
Narendra Modi
@narendramodi
107M followers
6
Rihanna
@rihanna
97.3M followers
7
NASA
@nasa
92.1M followers
8
Justin Bieber
@justinbieber
90.6M followers
9
KATY PERRY
@katyperry
86.8M followers
10
Taylor Swift
@taylorswift13
80.6M followers
11
Lady Gaga
@ladygaga
72.2M followers
12
Kim Kardashian
@kimkardashian
69.4M followers
13
YouTube
@youtube
68.6M followers
14
Virat Kohli
@imvkohli
68.5M followers
15
Bill Gates
@billgates
63.4M followers
16
The Ellen Show
@theellenshow
62.5M followers
17
CNN
@cnn
61.9M followers
18
Neymar Jr
@neymarjr
61.1M followers
19
X
@x
60.9M followers
20
Selena Gomez
@selenagomez
59.9M followers
Olivia
Online
✨
⭐
💫