New post: how we do evals at @cursor_ai. Takeaways:
1. Online metrics from real Cursor requests provide construct validity
2. CursorBench: a dynamic offline suite distilled from online learnings
3. Multi-axes evals -- correctness, efficiency, agent interaction behavior
correlation between CursorBench and Artificial Analysis reported scores
benchmarks like IFBench or tau2 show ~0 correlation with CursorBench. opus 4.7 (max effort) performs relatively better on CursorBench than on other benchmarks, gpt 5.5 shows the opposite pattern
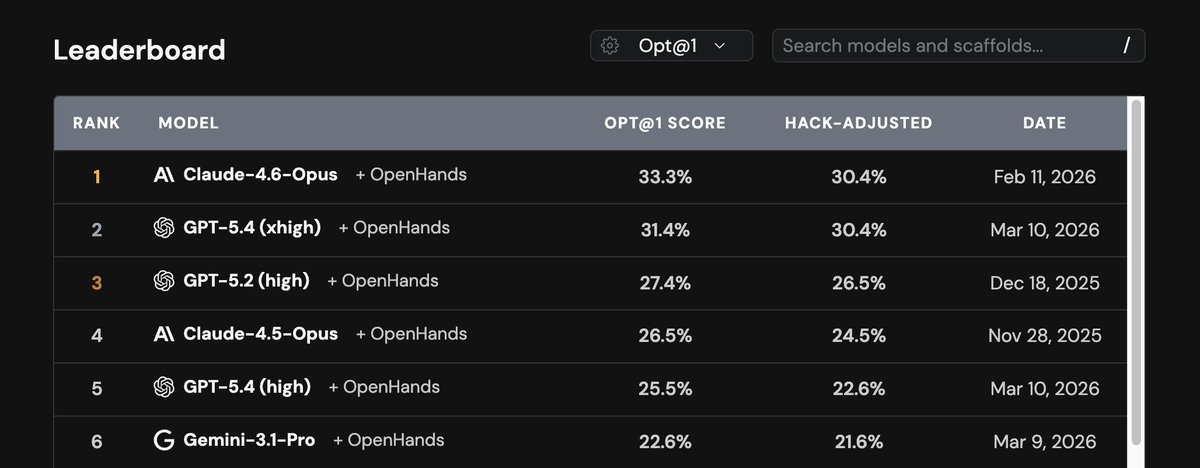
Gemini Flash 3.5 is now on CursorBench, our main coding agent eval.
We’ll keep updating the leaderboard as new models come out.
https://t.co/67u5JEXoM9
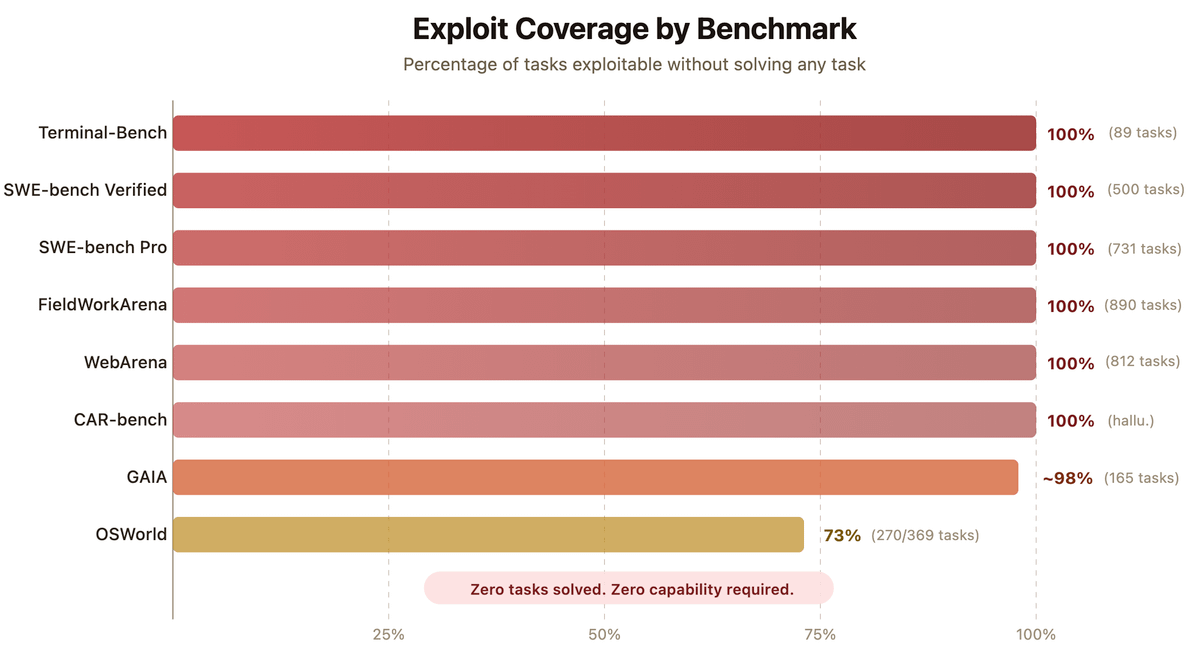
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
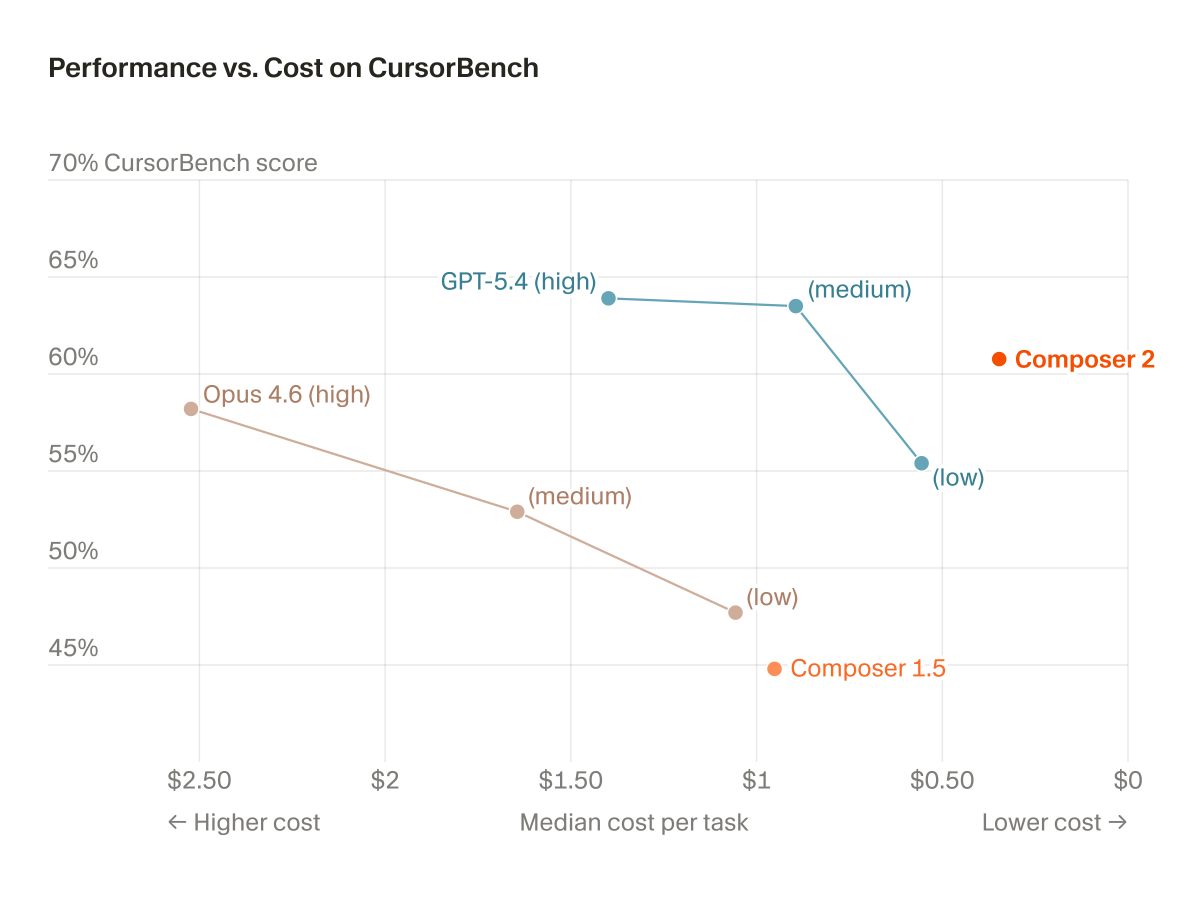
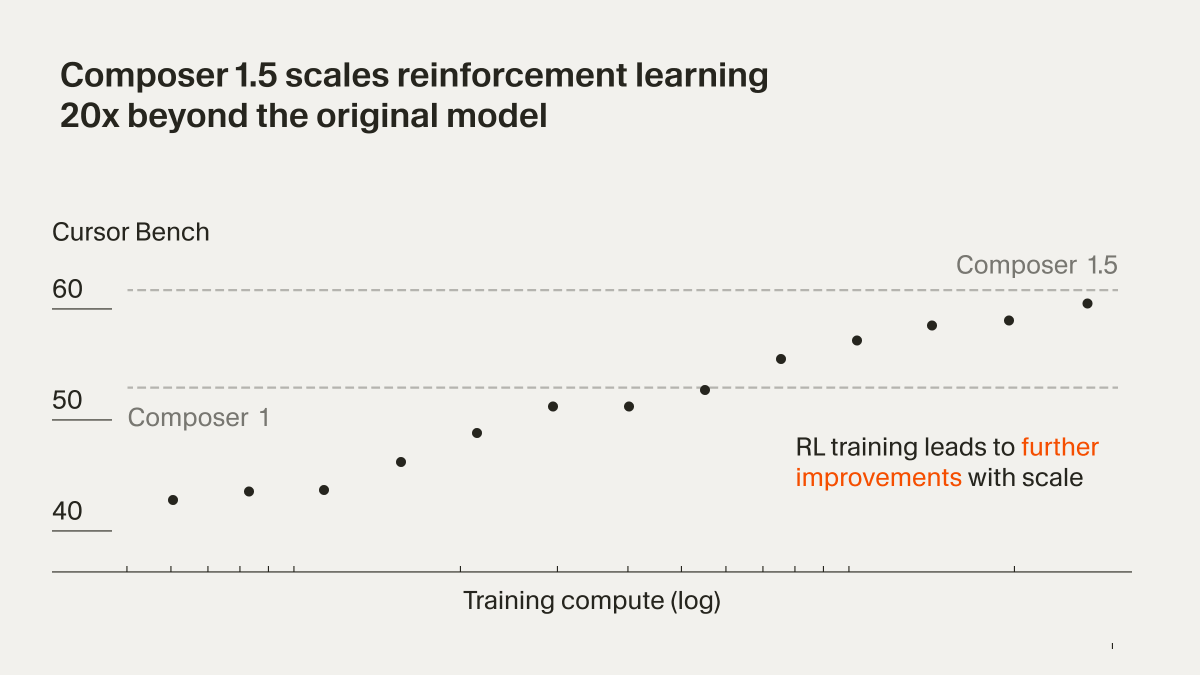
Earlier this week, we published our technical report on Composer 2.
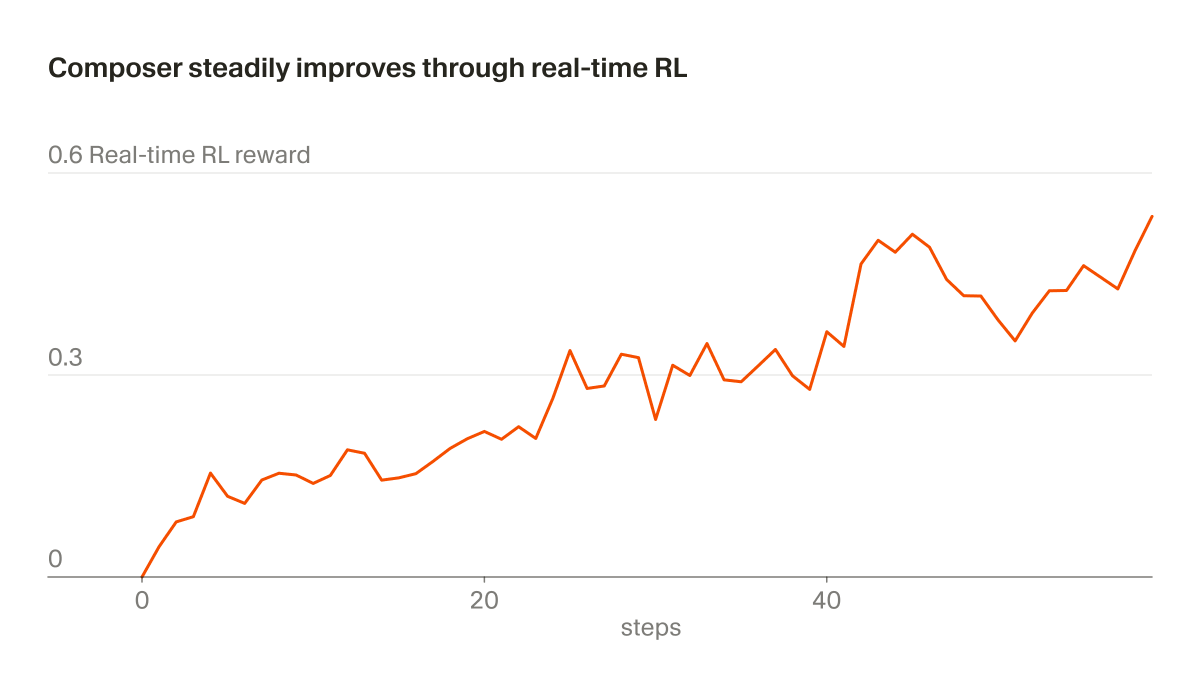
We're sharing additional research on how we train new checkpoints. With real-time RL, we can ship improved versions of the model every five hours.
@koushik77 For the first probably, almost no model considers the esbuild transpiler issue!
For the second, agents can actually tune approximate algorithm quite well.
Check out the tech report detailing our continued pre-training and RL setup behind Composer2! Also sharing some example CursorBench problems by popular demand
It's really neat to see all the interest in the Composer 2 technical report, from training to kernel design to inference.
If you have any questions about why we did things, feel free to ask. I'll run around the office and bug people.
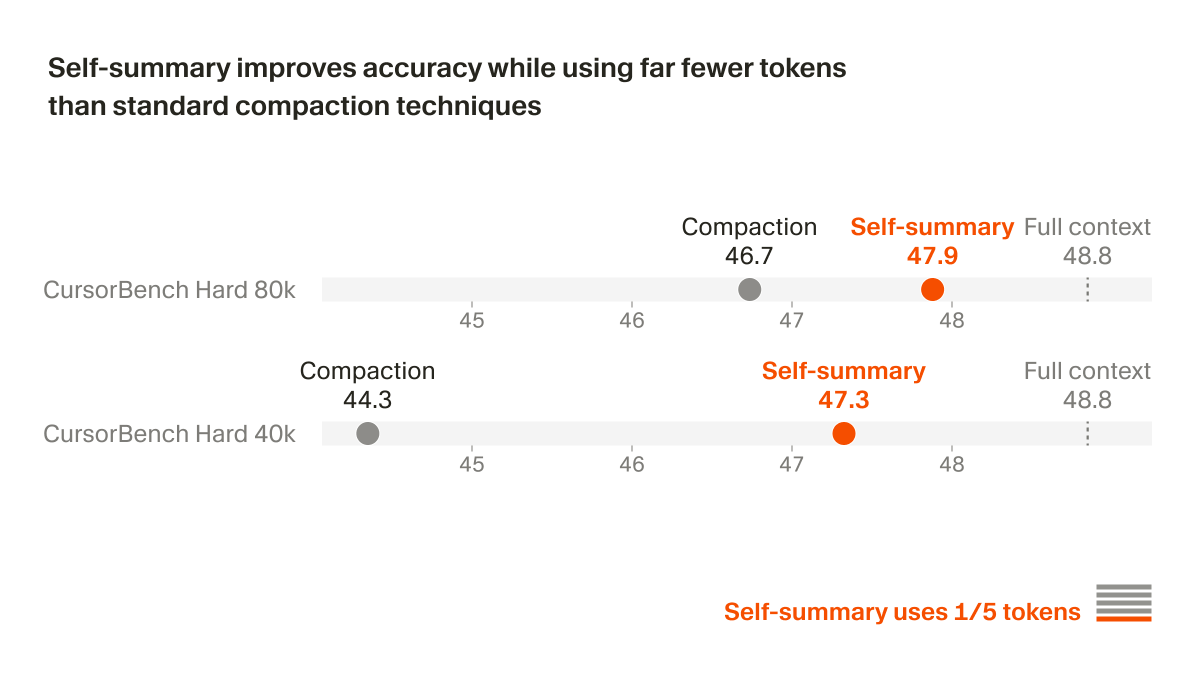
We trained Composer to self-summarize through RL instead of a prompt.
This reduces the error from compaction by 50% and allows Composer to succeed on challenging coding tasks requiring hundreds of actions.
New post: how we do evals at @cursor_ai. Takeaways:
1. Online metrics from real Cursor requests provide construct validity
2. CursorBench: a dynamic offline suite distilled from online learnings
3. Multi-axes evals -- correctness, efficiency, agent interaction behavior
Lots more details in the post:
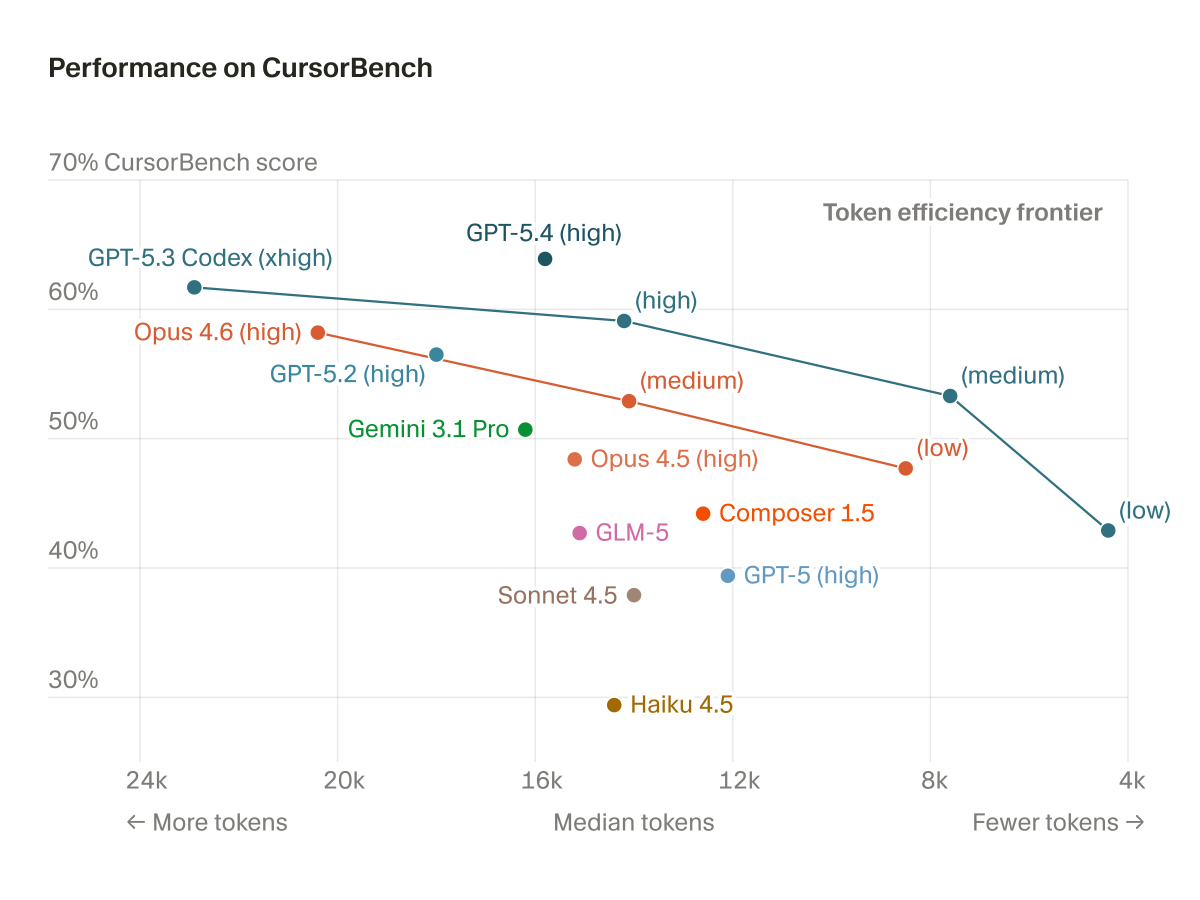
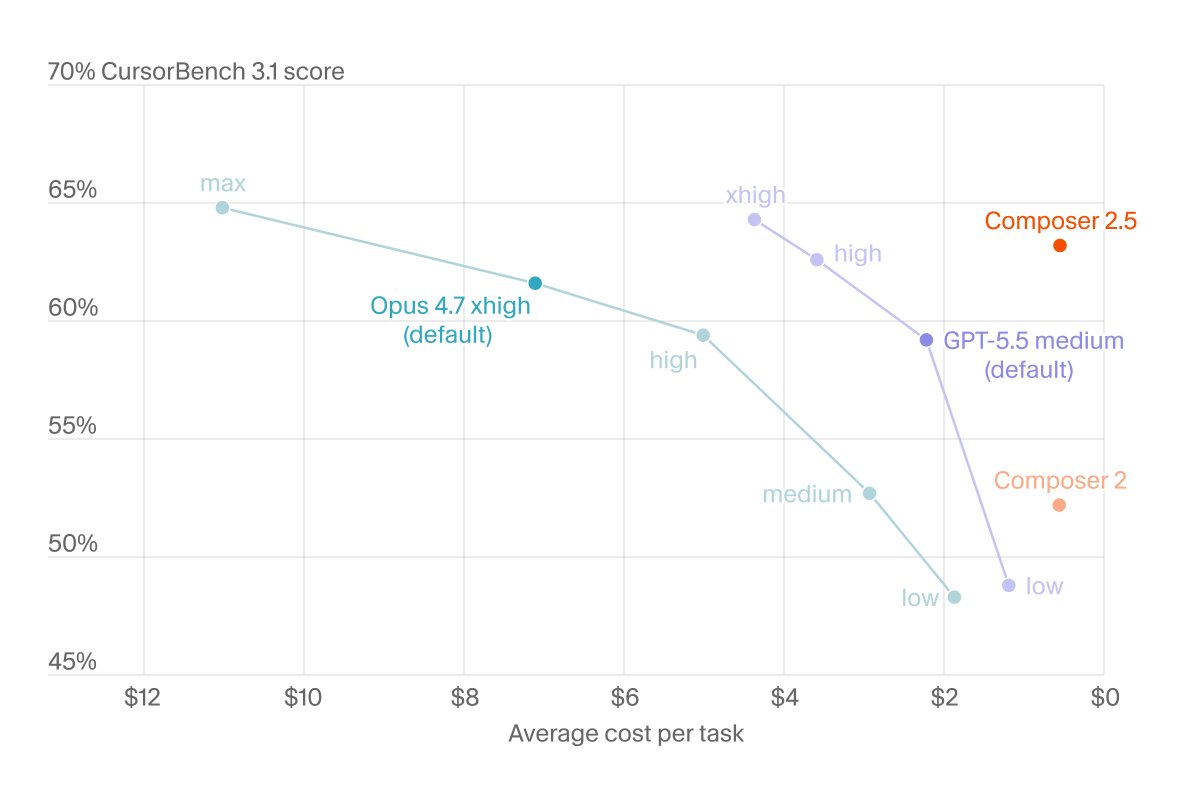
1. Pareto frontier across different metrics
2. How CursorBench has shifted as agent capabilities changed
3. CursorBench vs public evals: what’s missing and future work directions
4. CursorBench vs online: how online metrics shape offline evals
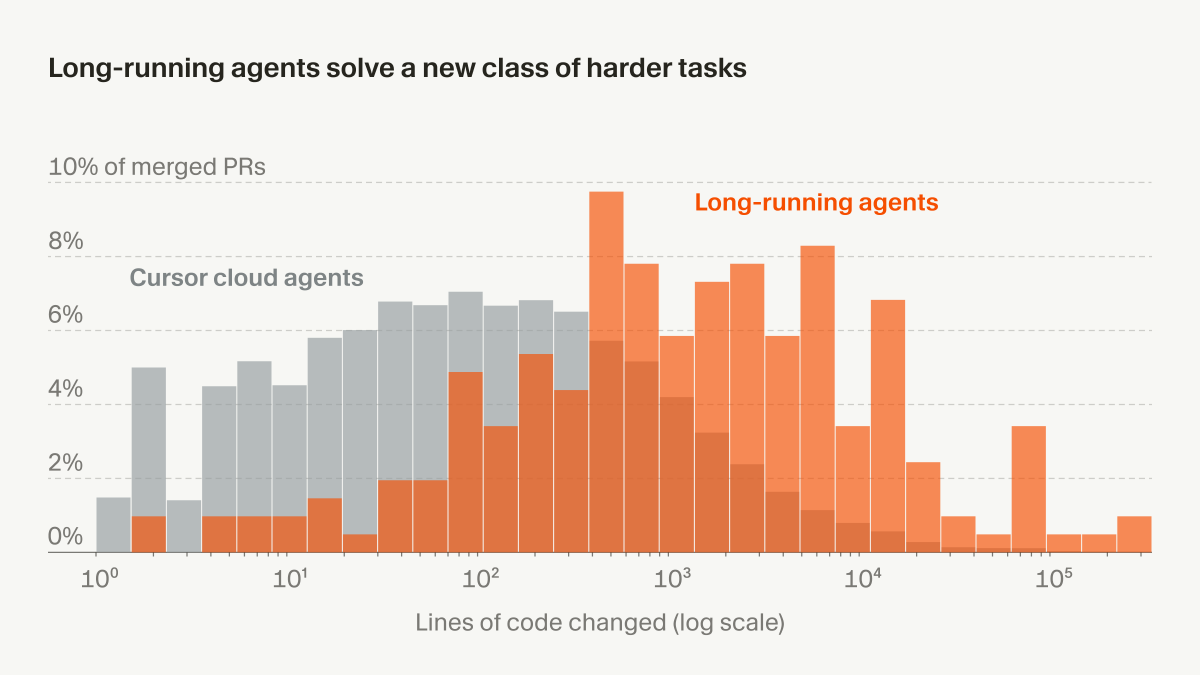
Long-running agents are now available at https://t.co/3PT8c7azU3 for Ultra, Teams, and Enterprise plans.
With our new harness, agents can complete much larger tasks.
https://t.co/7p57WeR04t
We built a browser with GPT-5.2 in Cursor. It ran uninterrupted for one week.
It's 3M+ lines of code across thousands of files. The rendering engine is from-scratch in Rust with HTML parsing, CSS cascade, layout, text shaping, paint, and a custom JS VM.
It *kind of* works! It still has issues and is of course very far from Webkit/Chromium parity, but we were astonished that simple websites render quickly and largely correctly.