"Capture your institutional knowledge" has meant the same thing for 30 years: index the documents, search over them.
But a document is the output of judgment with the judgment removed.
The judgment is in the diff. The markup between the first draft and the one that ships. And almost every firm throws it away.
@saranormous named the untrainable territory. At @farsight_ai we're building the instrument that lives inside it.
The System of Judgment.
Claude is INSANE for getting more out of Claude Code.
I've documented 6 slash commands that make every session faster, cheaper, and less likely to waste work.
Type / in any Claude Code session and dozens of built-in commands appear immediately. Most engineers ignore them. These 6 are the ones worth using every session.
Inside the guide:
- /clear: wipes the context window between tasks so Claude stops dragging old sequence work into your account research. Run it every time you switch from one task to a completely different one. Faster, cheaper, cleaner.
- /btw: add context while Claude is mid-task without stopping it. Running account research across 20 companies and you remember two are already in your CRM? Use /btw to pass that in. Claude notes it and continues without restarting.
- /statusline: customise the status bar to show model name, context window percentage used, estimated real cost, and how many agents are active in parallel. Set it once per project. No more hitting limits mid-task blind.
- /plan: Claude researches the task and returns a plan before building anything. You review and approve. Then it builds. No more finishing a 5-touch sequence and realising it assumed the wrong persona.
- /rewind and /resume: /rewind rolls back to a checkpoint inside your current session when Claude goes in the wrong direction. /resume brings back a conversation you cleared or closed hours ago. Different commands for different situations.
- /goal: you define the task and exactly what done looks like. Claude works until it meets the condition. A second evaluator agent checks the output before marking it complete. Set 20 account briefs as the goal, walk away, come back to verified output.
Want a copy? Like + Comment "COMMANDS" and I'll send it over ASAP
(Must be following)
🚨 ANNOUNCING FUSION AGENT SWARMS - Build Complete SaaS Apps With Top AI Models
Fusion agents combine Kimi 2.7, GLM 5.2 with Opus 4.8 and GPT 5.5
- multi-agent architectures with open-source sub-agents
- build complete SaaS apps
- one click connectors to 100+ products
- create companion iOS and android apps with one prompt
- accept stripe payments
Amazing websites for coders and makers
https://t.co/DixL0ioh4o - 99 animated free CSS buttons with prompts
https://t.co/QfIg7QXA2P - Ship to production without managing infrastructure
https://t.co/IQNseVG0ks - AI-powered customer support & feedback platform
https://t.co/mbJTIao4ag - AI Programmatic videos with Claude
https://t.co/IGSzHkdiJY - Open source CLI system monitor
The cleverest code you ever wrote is the one you're least qualified to debug
Brian Kernighan saw this in 1974. In The Elements of Programming Style, written with P.J. Plauger, he noted that "debugging is twice as hard as writing a program in the first place."
Then he asked the obvious follow-up: if you wrote it at the top of your cleverness, who exactly is going to debug it? The internet later compressed it into 𝗞𝗲𝗿𝗻𝗶𝗴𝗵𝗮𝗻'𝘀 𝗟𝗮𝘄: write code as cleverly as possible and you are, by definition, not smart enough to debug it.
The asymmetry comes from 𝗰𝗼𝗻𝘁𝗲𝘅𝘁. When you write code, you hold the full mental model: every assumption, every invariant, the reason behind every branch. When you debug it months later, that model is gone. You face the code alone, plus a second puzzle that writing never had: figuring out why it doesn't do what it should. Same person, half the information, harder problem.
In 20+ years, I've seen recursive logic reach production exactly once, and it broke on edge cases. Nobody could follow the flow. We ended up rewriting the entire module in a plain style anyone could maintain. The cleverness saved lines. It cost us the module.
This is not a ban on optimization or advanced techniques. It's a demand for a 𝗿𝗮𝘁𝗶𝗼𝗻𝗮𝗹𝗲. Optimize where you can explain why, and write the reason down. The next debugging session may delete your optimization anyway.
AI raises the stakes on this law. When an assistant writes the clever version for you, you enter every debugging session as someone who never had the context at all. Writing code is now cheap. The half of the job Kernighan called 𝘁𝘄𝗶𝗰𝗲 𝗮𝘀 𝗵𝗮𝗿𝗱 is becoming the whole job.
Cleverness is an asset at write time and a liability at debug time.
Why is it hard to beat Facebook today?
There's 50-year-old math behind that, and it's called 𝗠𝗲𝘁𝗰𝗮𝗹𝗳𝗲'𝘀 𝗟𝗮𝘄: the value of a network grows with the 𝘀𝗾𝘂𝗮𝗿𝗲 of its users. The reason is simple. Five users give you 10 possible connections. A thousand give you roughly half a million. Double the users and you don't double the network. You quadruple it.
For thirty years it was a slide, not a law. Then in 2013, Metcalfe fit ten years of Facebook's own data to the formula. It held. A 2015 study repeated the test with Tencent and found the same 𝗻² curve, plus a surprise: 𝗰𝗼𝘀𝘁𝘀 𝗴𝗿𝗼𝘄 𝗾𝘂𝗮𝗱𝗿𝗮𝘁𝗶𝗰𝗮𝗹𝗹𝘆 𝘁𝗼𝗼. More connections mean more storage, computation, and moderation. The networks won anyway, because value outran cost.
This is why tech keeps producing 𝘄𝗶𝗻𝗻𝗲𝗿-𝘁𝗮𝗸𝗲-𝗮𝗹𝗹 markets. Every new user makes the platform more valuable for everyone already there, which pulls in the next user. Leaving Facebook isn't really an app decision: you'd be abandoning the web of connections, and no rival can offer it without reaching the same scale. GitHub's value to a developer is, also, that every other developer and open-source project is there.
The law runs in reverse also. Each user who leaves subtracts connections for everyone who stays, so value drops faster than the user count.
It's a simplified model, of course: real users cluster, and inactive accounts add just a bit. But the core has data behind it now.
𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀 𝗮𝗿𝗲 𝗹𝗶𝗻𝗲𝗮𝗿. 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 𝗮𝗿𝗲 𝗾𝘂𝗮𝗱𝗿𝗮𝘁𝗶𝗰.
🚨 Gemini can now help you build a viral YouTube Shorts channel like a $/10K content strategist.
Here are 10 prompts that take you from zero to viral YouTube Shorts content in 30 days.
Copy and paste these directly to me to get started:👇
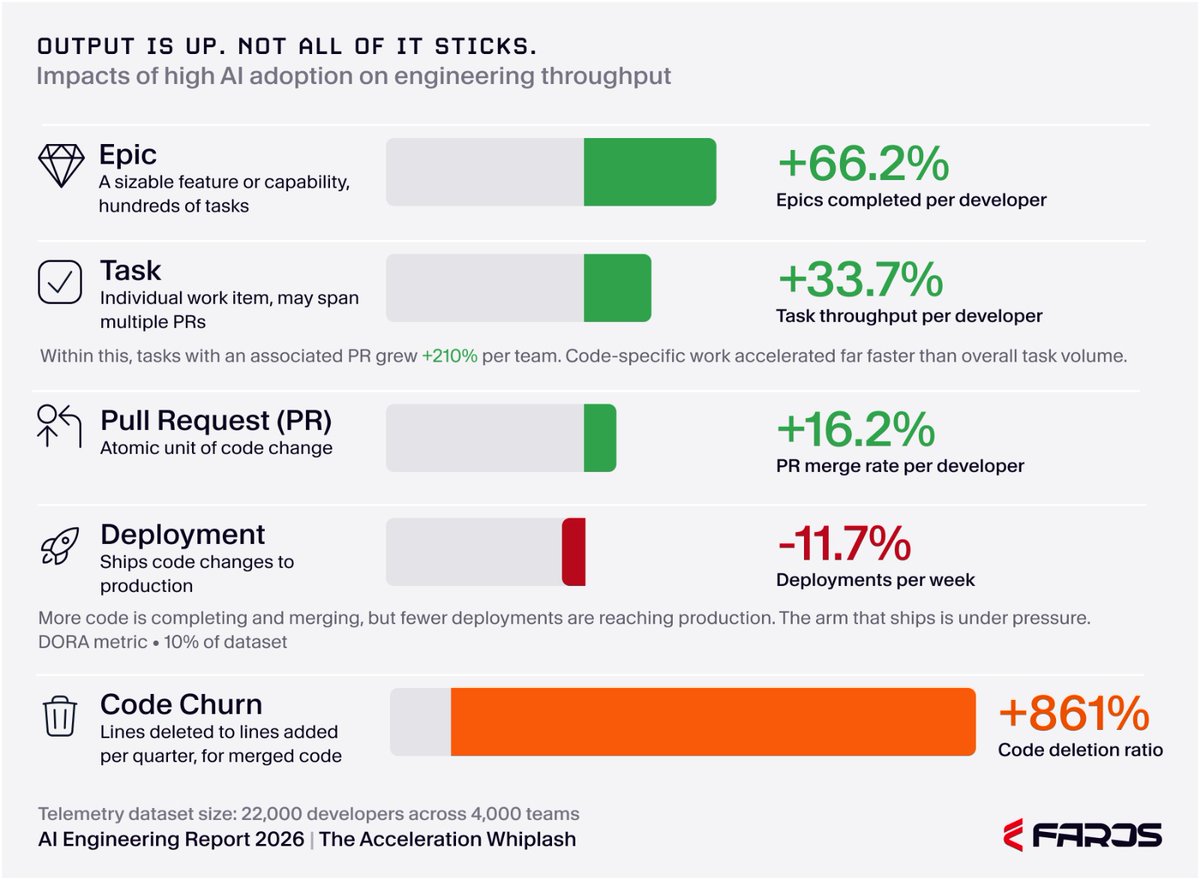
The biggest study ever done on AI coding tracked 22,000 developers for two years.
The headline number is everything the vendors promised. The number underneath it is the one nobody wants to put on a slide.
Here's what the data actually shows.
A software analytics company called Faros pulled two years of real engineering telemetry not surveys, not vibes, actual system data from 22,000 developers across more than 4,000 teams. They compared each company's low-AI period against its high-AI period.
The output gains are real. Let's say that plainly.
Under heavy AI use, epics completed per developer jumped 66%. Task throughput per developer rose 34%. More work shipped, faster. This is the slide the CTO shows the board.
Then you read the second page.
The same teams, same two years, same dataset:
- Bugs per developer: up 54%
- Incidents per pull request: up 242%. More than triple.
- Time spent in code review: up 441%
- Code churn code written then deleted almost immediately: up 861%
- And 31% of pull requests now merge with zero review. Not by policy. Because reviewers physically cannot keep up with the volume.
Faros gave this pattern a name: the Acceleration Whiplash.
Here's the mechanism, and it's important, because it's not "AI writes bad code."
AI flooded a system built for human-paced work with output it was never designed to absorb. The writing got 10x faster. The reviewing, testing, and releasing did not. So the bottleneck didn't disappear. It just moved downstream and turned into incidents in production.
You sped up the factory line and never upgraded the inspection station. Now defects sail straight to the customer.
This is the uncomfortable truth for 2026: AI doesn't remove the hard part of building software. It relocates it. The skill is no longer typing code fast. The skill is reviewing, judging, and controlling a firehose of machine-generated code before it breaks something.
So if your team feels busier and more productive but also strangely more on fire more hotfixes, more "how did this reach prod," more late-night incidents you're not imagining it. You're living in the whiplash.
The fix isn't using less AI. It's putting the guardrails where the bottleneck actually moved: smaller pull requests, quality checks at the moment code is written instead of at the end, and treating review capacity as the real constraint.
More code was never the goal. Working software was.
The teams that win the next year won't be the ones generating the most code. They'll be the ones who can still trust what ships.
ZAI 🔥: GLM-5.2 by @Zai_org scored 51 point on Artificial Analysis Intelligence Index and got placed on the 4th spot! This made GLM-5.2 a new SOTA open-weight model.
Besides that, GLM-5.2 got ranked second on Frontend Code Arena, after currently unavailable Claude Fable 5.
Should be ZOTA! 👀
IBM engineers just showed how to run your own private AI infrastructure stack at home.
"Your data is your data, not your data is our business model."
Most people are racing to upload more of their life into AI tools they do not control.
A few are building private AI infrastructure on their own hardware.
Windows 11. WSL2. Docker. Ollama. Open WebUI. Local Llama and Granite models. Your own data. Your own machine.
No server farm. No cloud dependency. No handing sensitive documents to someone else's AI.
The best part is not the privacy.
It is understanding how AI actually works by building it yourself.
The gap between AI users and AI builders is widening fast.
This is one of the easiest ways to cross it.
Here is how to build your own privacy-preserving AI stack this weekend.
Google owns one of the most powerful learning tools in the world.
It’s free. It’s been available for months.
Yet 95% of people still use it the wrong way.
Here are 8 NotebookLM use cases that can save you hours of time.
🔖 Bookmark this — you’ll thank yourself later.
SOMEONE LEAKED THE ENTIRE CLAUDE FABLE 5 SYSTEM PROMPT AND ANTHROPIC CANNOT DELETE IT
120,000 characters, 1,685 lines and 27,000 tokens that reveal everything from how copyright limits actually work, to the fact that Fable 5 and Mythos 5 are the same model with different safety filters, to a persistent storage API most users had no idea existed.
The repo hit 26.4k stars and the original post got 700,000 views in 48 hours.
Bookmark this.
Membrane just published 3,000+ integration skills for agents that need to touch real SaaS apps.
The painful part is not calling one API.
It is auth, action names, app objects, and the glue code between tools.
application-skills turns that into installable skills for agents.
The useful part:
> one folder per app skill
> skills describe app structure, actions, and when to use them
> examples include Gmail, Slack, HubSpot, Salesforce, GitHub, and Jira
> Membrane handles OAuth, API keys, and token refresh
> built around the open Agent Skills spec
The repo labels the skills MIT, but I would still check the missing root LICENSE file before reusing at scale.
If your agent had app skills by default, which integration would remove the most manual glue?
Link in the reply 👇