World models are increasingly central to how agents learn and plan.
Today we're releasing WorldModelGym, a benchmark built around a single question: if an agent uses a world model to choose among actions, does it pick the right one?
We call this decision-based fidelity. 100+ tracks across Atari, Meta-World, DeepMind Control, and classic control. One frozen policy. Reality scores it.
Read the full post → https://t.co/OzVd1n6Vth
Excited to share RoboWorld 🤖
We roll out generalist robot policies from 4,186 real initial scenes, entirely inside a video world model with no robots, and the rankings hit Pearson r = 0.989 (Spearman ρ = 0.970) with the real RoboArena leaderboard. 🧵
[1/7]
10K+ episodes. 164 hours. 60 tasks.
One of the biggest missing pieces for Human-centric Physical AI has been large-scale, high-quality human-robot interaction data.
HABIT brings together over 164 hours of real human-robot interaction episodes across 60 tasks, providing a valuable resource for developing and evaluating collaborative robot intelligence.
Big congrats to @j__aehwi for leading this project. It was a pleasure to contribute to this work.
Introducing HABIT — a large-scale robot manipulation dataset for human-present environments, where a person shares the workspace and interacts with the robot in every episode.
60 tasks · 10,563 episodes · 164 hours of rich human-robot interaction.
Toward robots that are not just capable, but safe and socially compatible around people.
https://t.co/kEtkqbuoIn
🧵[1/7]
This is really cool work addressing one of the hardest problems in robotics: cross-embodiment transfer!
We propose the achieved Cartesian Delta as a unified action space for Robot Foundation Models and use an online conversion from achieved Cartesian Delta to real Cartesian commands.
These methods show significant improvements in transfer across embodiments and robots, as well as robustness to changes in control frequency and object weight.
If you've ever been frustrated by policy degradation when transferring between robots—even those with the same embodiment—this paper is definitely worth checking out. It offers valuable insights into addressing the cross-embodiment transfer gap.
🤖 How can we learn a reliable policy across different robots and dynamics?
Excited to introduce SPACE, a framework that significantly improves cross-embodiment and cross-hardware (e.g., DROID) learning by addressing dynamics gaps, with execution-time adaptation.
📄 paper: https://t.co/zgByzVwFyz
📷 Project website: https://t.co/ZytiBGmMrY
🧵[1/n]
#Robotics #CrossEmbodiment .
🤖 How can we learn a reliable policy across different robots and dynamics?
Excited to introduce SPACE, a framework that significantly improves cross-embodiment and cross-hardware (e.g., DROID) learning by addressing dynamics gaps, with execution-time adaptation.
📄 paper: https://t.co/zgByzVwFyz
📷 Project website: https://t.co/ZytiBGmMrY
🧵[1/n]
#Robotics #CrossEmbodiment .
We are releasing:
✅ XVR dataset
✅ Data generation pipeline
✅ Training code
✅ Evaluation code
We hope XVR helps advance multi-view reasoning for both VLMs and VLAs.
Project: https://t.co/g7do2Hbcl4
Paper: https://t.co/LWb8hsvYdY
Huge thanks to all my collaborators, especially co-first author @Jay019374 and my advisor @kimin_le2, for making this work possible. 🙌
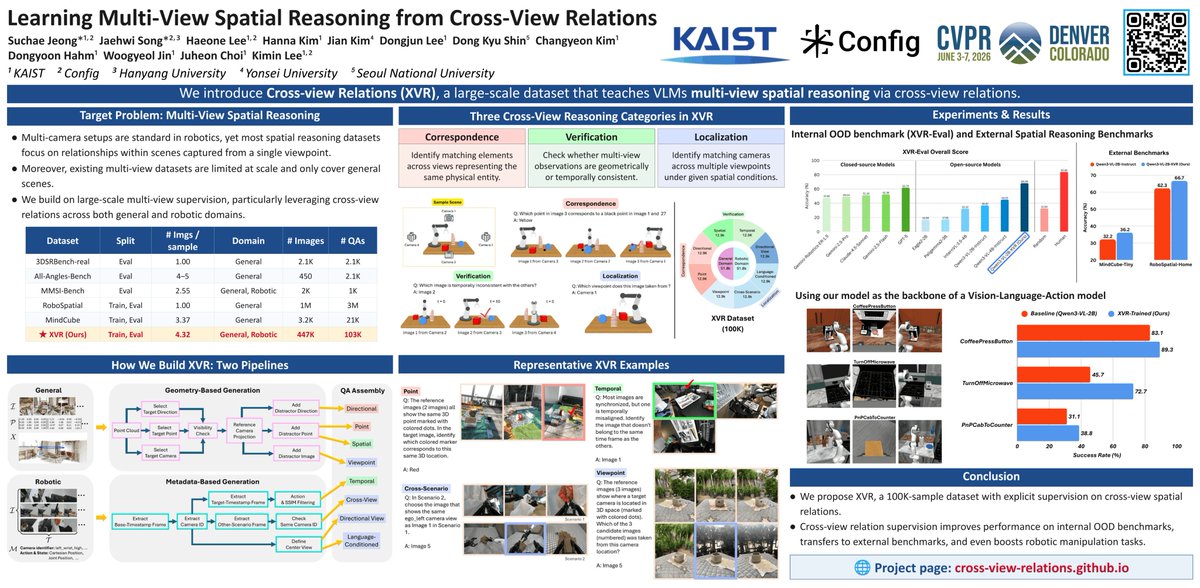
🚀 Our paper "Learning Multi-View Spatial Reasoning from Cross-View Relations (XVR)" has been accepted to #CVPR2026!
Current VLMs can reason from a single view surprisingly well, but they still struggle to connect information across multiple viewpoints.
To address this, we introduce XVR:
• 100K-sample VQA dataset
• 3 categories, 8 tasks
• Designed specifically for cross-view spatial reasoning
Most excitingly, cross-view reasoning transfers to robot manipulation.
Using an XVR-trained VLM as a VLA backbone improves RoboCasa manipulation success rates by +13%p on average.
Project page: https://t.co/g7do2Hbcl4
Paper: https://t.co/LWb8hsvYdY
🍿 More details below
XVR also improves upstream reasoning performance.
Our XVR-trained Qwen3-VL-2B outperforms much larger proprietary models, including GPT-5, Gemini-2.5-Pro, and Claude-4.5-Sonnet on XVR-Eval.
We also observe consistent gains on external spatial reasoning benchmarks such as MindCube-Tiny and RoboSpatial-Home.
The result we're most excited about:
Cross-view reasoning improves robot manipulation.
Using an XVR-trained VLM as the backbone of a VLA model improves manipulation success rates by an average of +13 percentage points across RoboCasa tasks.
Better spatial understanding → Better control.
To teach cross-view reasoning, we built XVR.
📊 100K VQA samples
📌 3 reasoning categories:
• Correspondence
• Verification
• Localization
covering 8 different tasks.
Every question requires information from multiple viewpoints to solve.
🚀 Our paper "Learning Multi-View Spatial Reasoning from Cross-View Relations (XVR)" has been accepted to #CVPR2026!
Current VLMs can reason from a single view surprisingly well, but they still struggle to connect information across multiple viewpoints.
To address this, we introduce XVR:
• 100K-sample VQA dataset
• 3 categories, 8 tasks
• Designed specifically for cross-view spatial reasoning
Most excitingly, cross-view reasoning transfers to robot manipulation.
Using an XVR-trained VLM as a VLA backbone improves RoboCasa manipulation success rates by +13%p on average.
Project page: https://t.co/g7do2Hbcl4
Paper: https://t.co/LWb8hsvYdY
🍿 More details below
Why do current VLMs struggle with multiple views?
Although modern VLMs perform well on single-view reasoning, they often fail when information must be combined across viewpoints.
We found that existing datasets provide very limited supervision for learning cross-view relations.