New SOTA on Humanity's Last Exam (HLE)
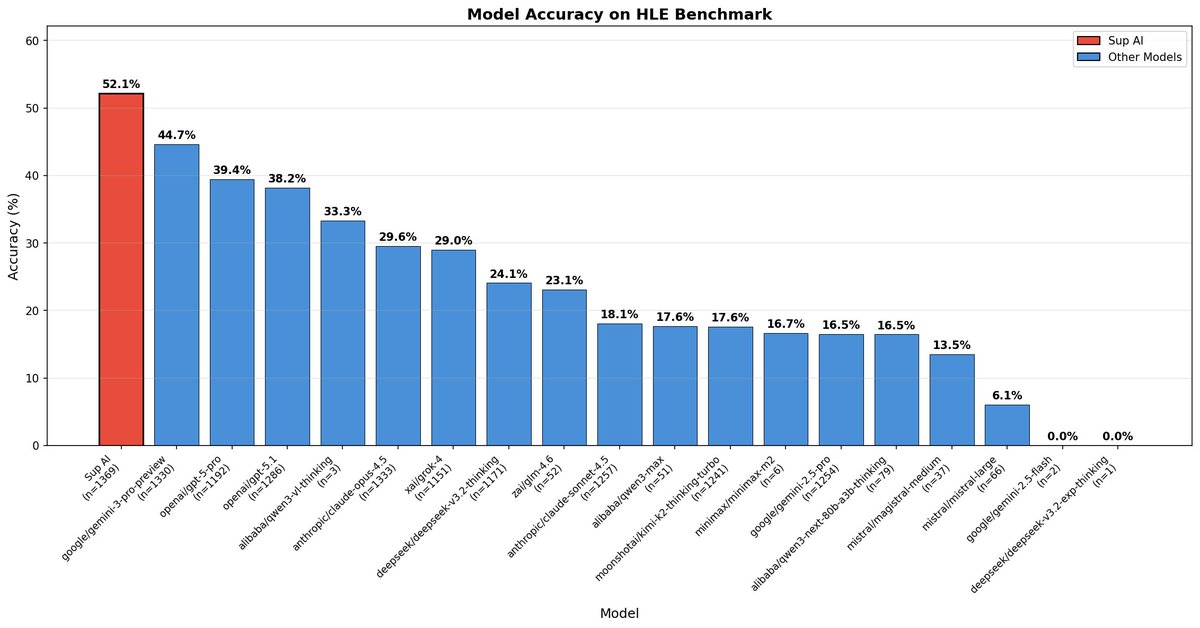
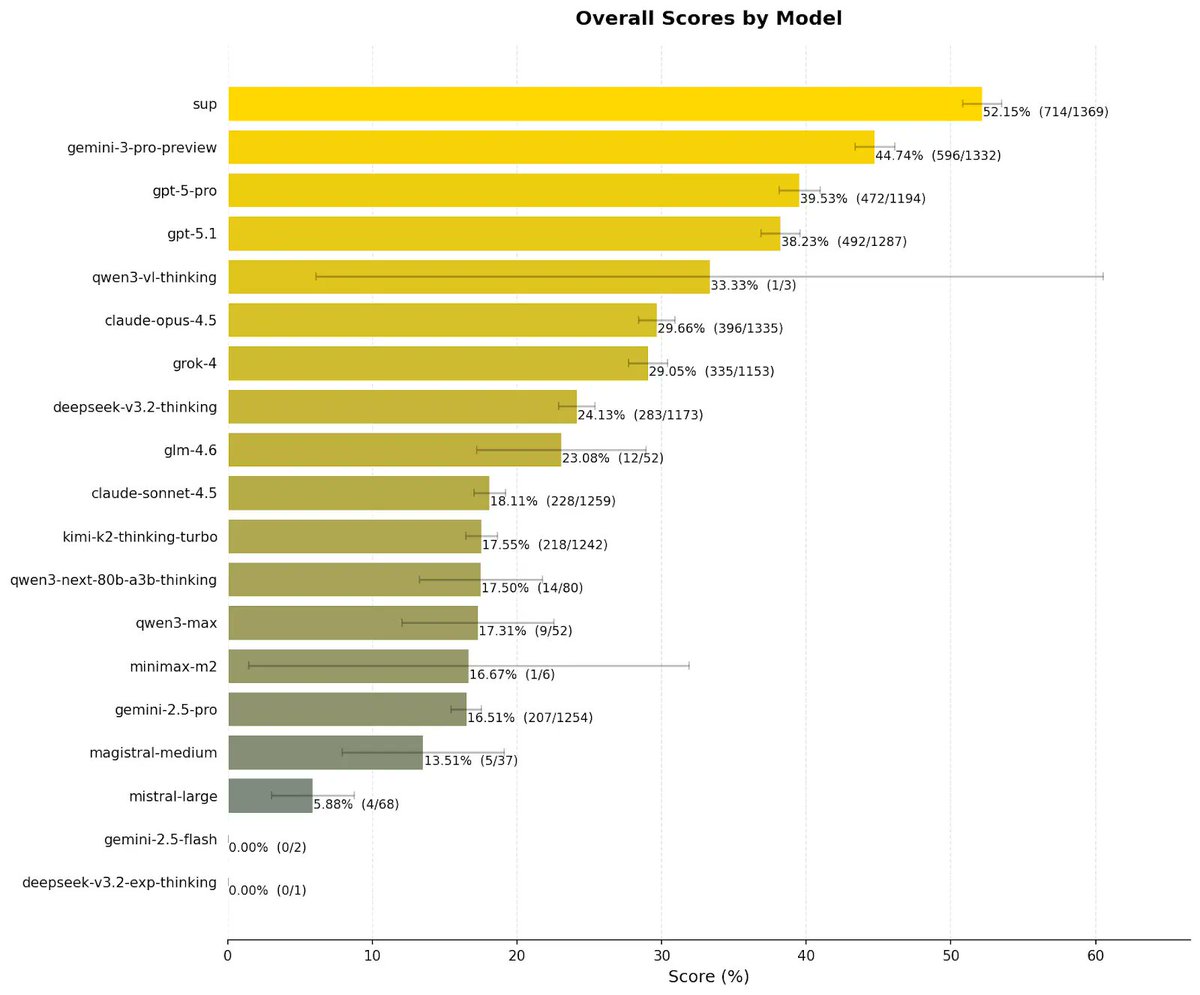
We have achieved 52.15% accuracy on the world's hardest open-source AI reasoning test, setting a new benchmark record.
Sup AI is now outperforming every individual frontier model, including Gemini 3 Pro Preview and GPT-5 Pro.
Our lead over the next best model? +7.49 points.
Check the full evaluation & code:
https://t.co/l8FuQDRfxI
#AI #MachineLearning #HLE #SupAI
Sup AI is live on @ProductHunt 🚀
"Which AI model is the best?"
Wrong question.
The best model isn't a model. It's an orchestra.
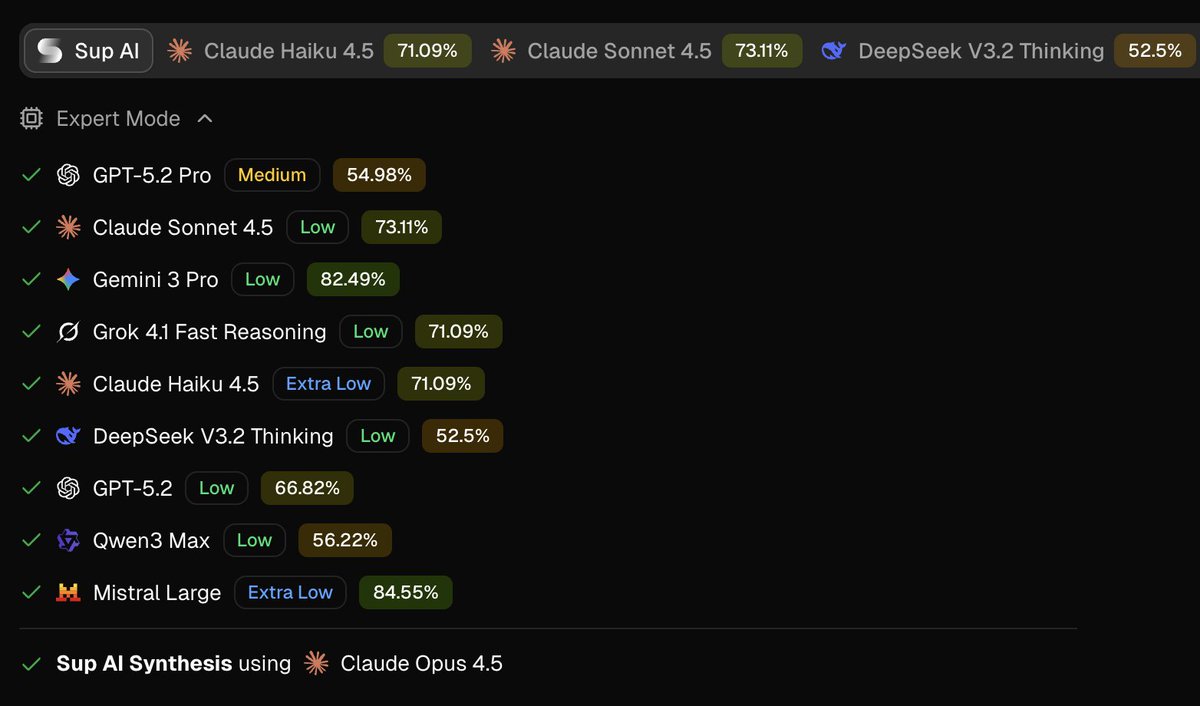
Sup AI runs 9 frontier models in parallel and synthesizes their answers→ 52.15% on HLE benchmark (without the help of tools).
→ Multi-model consensus (up to 9 models)
→ Ensemble RAG with live web + your files
→ Every claim cited
$10 free credit to start
20% off with code: PRODUCTHUNT
Links below 👇
We just launched Sup AI on @ProductHunt!
We combine multiple AI models and use confidence scoring to give better answers with fewer hallucinations.
#1 on Humanity's Last Exam: 52.15%. Beating every individual model.
$10 starter credit to try it, and 20% off your first month with code "PRODUCTHUNT"
https://t.co/lskoGKfWBE
Love seeing @Perplexity ship Model Council. Multi-model is the right direction.
At Sup AI, we've pushed this further: 9-model ensembles + segment-level confidence scoring (logprob signals across every claim).
Text can lie. A model can sound 100% confident while hallucinating. The math doesn't lie.
Result: 52.15% HLE (SOTA) + 3 questions solved where ALL 9 individual models failed.
The future isn't "which model is best." It's "what does each model know vs. what is it guessing?"
Introducing Model Council in Perplexity.
Run three frontier models at once, compare outputs, and get a more accurate, higher‑confidence answer.
Available now on web only for Perplexity Max subscribers.
This is exactly right. And it compounds with model diversity.
At Sup AI: 5 prompt variations × 9 frontier models = 45 reasoning paths cross-validated before synthesis.
Single prompt on single model = leaving 90% of accuracy gains on the table.
My friend Gary Gurevich built a "hyperplane metaprompt" that automates the prompt side: generates 5 non-overlapping angles, predicts objections, synthesizes with traceability.
Full template 👇
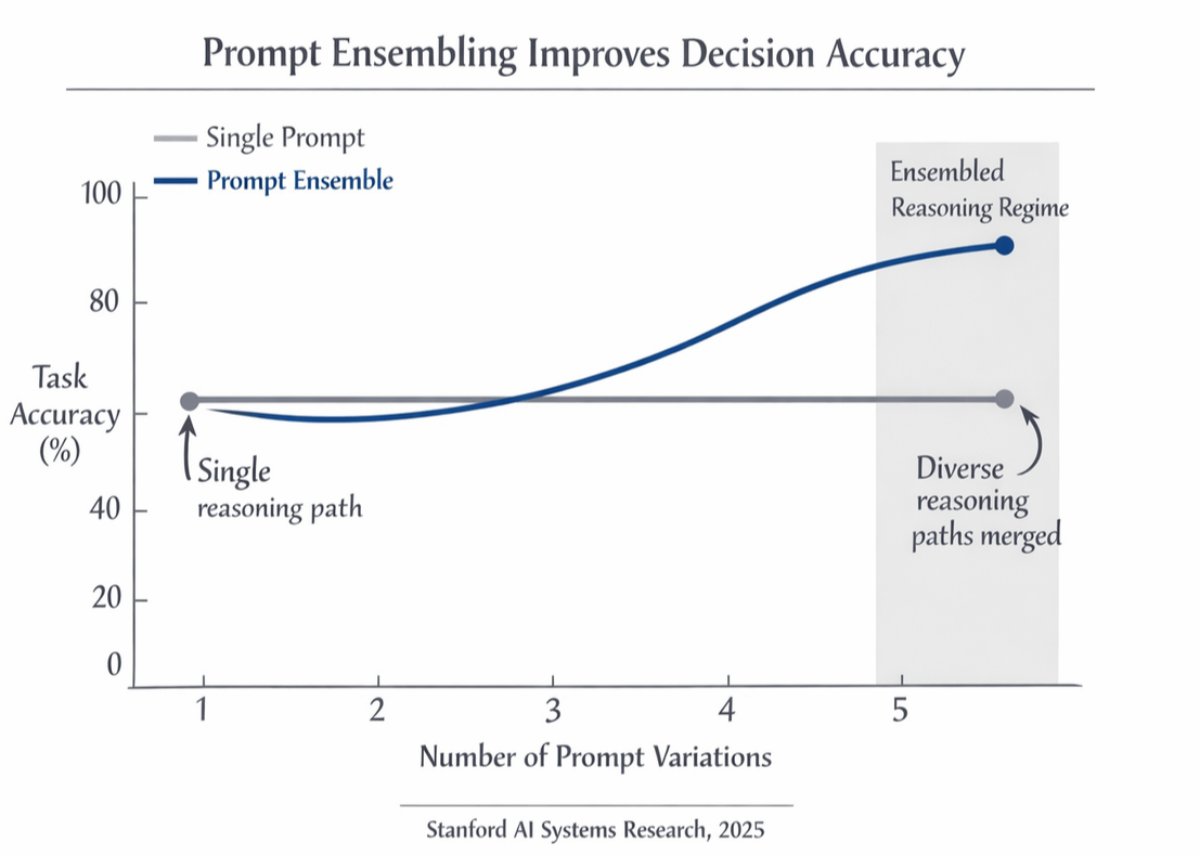
Stanford researchers just published a prompting technique that makes today’s LLMs behave like better versions of themselves.
It’s called “prompt ensembling” and it runs 5 variations of the same prompt, then merges the outputs.
Here’s how it works 👇
Gary's Hyperplane Method:
"Generate a metaprompt to restate any prompt 4 ways (sharpening, scope-widening, cross-domain). Each restatement's center of mass overlays the original but extends in NON-OVERLAPPING directions.
Answer all 5. Predict my objections. Answer those. Synthesize with full traceability."
[your prompt]
Unpopular opinion: The AI model race is a distraction.
See this tug-of-war? 👇
9 AI models vs. 1 "best" model.
The crowd wins. Every time.
No single LLM excels at everything: Claude crushes analysis, GPT-5 dominates creative, Gemini nails structured data.
Orchestration intelligently routes each task to the RIGHT specialist.
Sup AI proved it: 52.15% on Humanity's Last Exam, beating Gemini 3 Pro by 7.5 points.
The companies winning in 2026 won't have the "best" model.
They'll be the ones who stopped picking sides.
Does orchestration become a first-class category this year? 👇
#AI #AIOrchestration #MultiModel
Microsoft CEO Satya Nadella just confirmed the Sup AI thesis:
"Assigning roles to models and orchestrating them gets better results than any single frontier model."
We’ve built the engine to prove it.
• 52.15% accuracy • +7.4 percentage points vs. single models • Available today
Stop waiting for the next GPT. Start orchestrating. 🎯
AI agents don't fail like chatbots…
AI agents fail like software in production.
One bad action breaks trust.
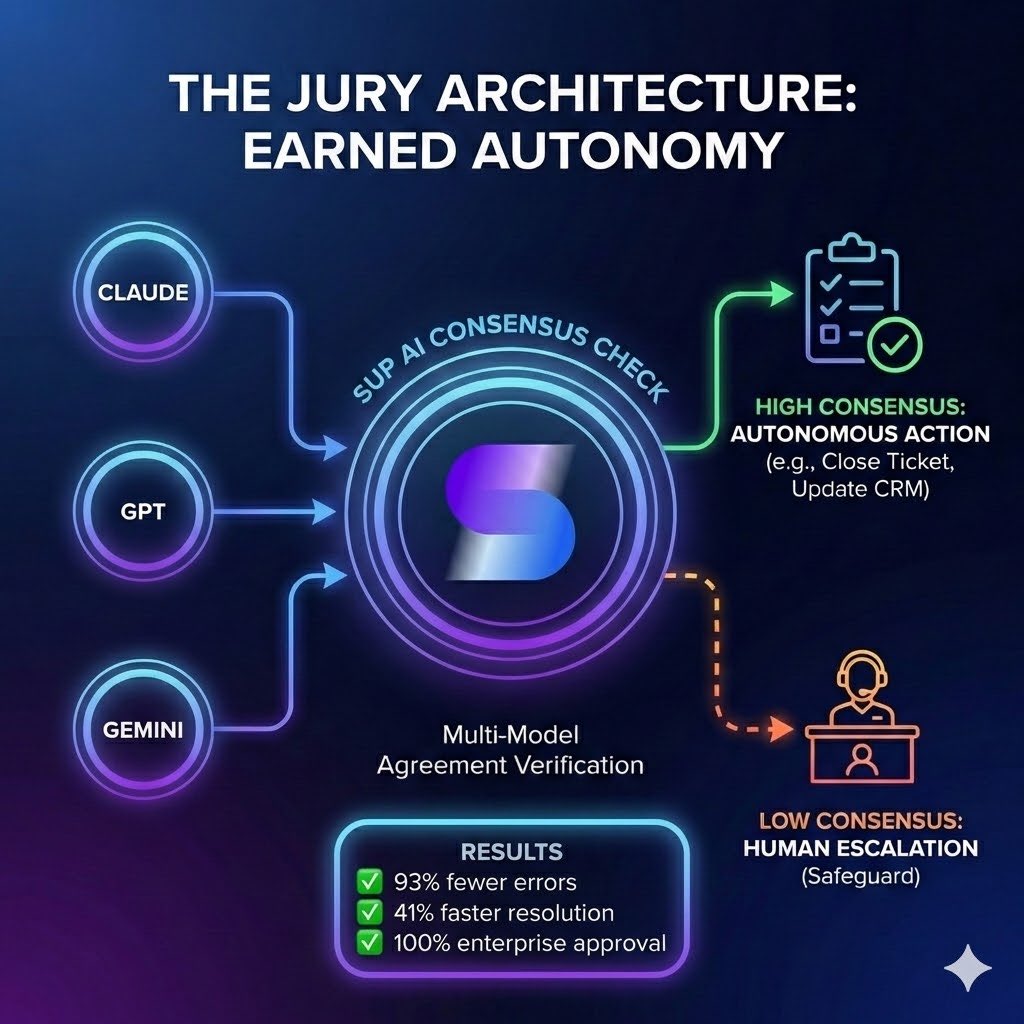
@usevemly AI employees close tickets and update CRMs in live systems. Early on: too confident, too many errors.
Fix: Sup AI as decision layer → Multiple models propose actions → Only executes on high consensus + confidence → Otherwise: blocked or escalated
Results:
• 93% fewer incorrect tool calls
* 41% faster resolution
* 100% enterprise approval
Full case study: https://t.co/zzw18DUi2y
Autonomy you can actually trust.
#AgenticAI #EnterpriseAI
☑️ Pro Mode → Expert Mode
☑️ Orchestrator now auto-picks thinking effort per model = massive cost savings + fixes slow GPT-5.2 Pro
☑️ Advanced model selector with per-model controls
☑️ Timestamps + generation times on all messages
Sup AI memory just leveled up
We upgraded from Voyage Multimodal 3 → 3.5 with @VoyageAI
* Best-in-class multimodal RAG
* More accurate chat memories
* Hyper-personalized answers
* Everything becomes permanent knowledge️
#SupAI#VoyageAI#Multimodal#RAG
Sup AI Chrome Extension is live
Your address bar → direct access to frontier models with forced citations.
→ Default search goes to Sup AI → !g for instant Google fallback → mode=fast / thinking / deep-thinking / pro → models=gemini-3-flash or models=qwen3-max,gemini-3-flash → Zero permissions. Zero data collection.
https://t.co/lQ24BvXmpT
3/ At Sup AI, we've seen this pattern work.
Our multi-model orchestration scored 52.15% on Humanity's Last Exam: +7.49 points above any single frontier model.
The future isn't bigger models. It's smarter systems.
1/ AI just solved an Erdős problem confirmed by @terencetao
GPT-5.2 cracked Problem #728, a conjecture unsolved for decades.
But the breakthrough isn't "one smart model." It's the architecture.
2/ The solution required ORCHESTRATION:
• GPT-5.2 generated the proof (intuition) @sama
• Harmonic's Aristotle verified it in Lean (rigor) @vladtenev
• Human feedback refined the approach @terencetao
This is constructive synthesis in action.
Sup AI whitepaper is live on the methodology behind 52.15% on HLE:
• 3 correct answers synthesized when EVERY model failed
• Grok 4 (29%) uniquely solved 16 Qs vs GPT-5 Pro's 9 (40%)
• Low correlation pairs >high accuracy pairs
• 58.44% theoretical ceiling w/ models
• 42% Qs unsolved by ANY model
• Full methodology, IQ curves, correlation matrices: https://t.co/EiKtyUOGzo
#AI #MachineLearning #OpenSource #AIResearch #EnsembleAI #AIOrchestration #HLE