If you're aiming for a DevOps role, mastering Linux and a solid understanding of how operating systems and networks function is a must.
#DevOps#Linux#OperatingSystems#Networking
✅Day 15 of #GenerativeAI
Topic - What is RAG | How does #RAG Work
It is an advanced framework that enhances capabilities of LLMs by integrating external information retrieval mechanisms
I's allows AI systems to access & incorporate up-to-date, domain-specific knowledge
🧵
How do we implement 𝗧𝗼𝗼𝗹 𝗖𝗮𝗹𝗹𝗶𝗻𝗴 𝘃𝗶𝗮 𝗠𝗖𝗣?
Let’s unpack the difference between using MCP to implement Tool Calling and baking the Tools directly into your Agents.
I’ve recently seen many MCP vs. Function Calling articles floating around, some misleading. Let’s simplify.
❗️ 𝗖𝗹𝗮𝗿𝗶𝗳𝘆𝗶𝗻𝗴 𝗼𝗻𝗲 𝗱𝗲𝘁𝗮𝗶𝗹: Function Calling and Tool Use in Agentic Systems are almost the same thing. You can implement tools via functions, the only difference is that functions are usually used to enforce stricter structure to the input and output schema.
𝘜𝘴𝘪𝘯𝘨 𝘔𝘊𝘗 𝘵𝘰 𝘦𝘹𝘱𝘰𝘴𝘦 𝘵𝘰𝘰𝘭𝘴 𝘵𝘰 𝘺𝘰𝘶𝘳 𝘈𝘨𝘦𝘯𝘵𝘴:
ℹ️ In this case your Agent becomes an MCP Host and implements one or more MCP Clients to communicate with MCP Servers.
𝟭. User Query is passed to the Agent (usually a Python application).
𝟮. The application implements MCP Client and via it retrieves all available tools from the MCP servers.
𝟯. The list of available Tools is passed together with the User Query to a LLM via a prompt. The LLM figures out which tools need to be invoked and with what parameters.
𝟰. The Agent application communicates with the MCP server (via MCP Client) again and sends the tool execution request. After execution completes the Agent receives the required data.
𝟱. User Query is sent to the LLM together with the data retrieved by the Tool calls.
𝟲. The answer is constructed and returned to the user via the Agent.
𝘜𝘴𝘪𝘯𝘨 𝘕𝘢𝘵𝘪𝘷𝘦 𝘍𝘶𝘯𝘤𝘵𝘪𝘰𝘯 𝘊𝘢𝘭𝘭𝘪𝘯𝘨:
𝟭. User Query is passed to the Agent (usually a Python application).
𝟮. All of the available Functions/Tools are defined as part of the Agent code (procedural memory).
𝟯. The list of available Tools is passed together with the User Query to a LLM via a prompt. The LLM figures out which functions need to be invoked and with what parameters.
𝟰. The Agent application directly executes the functions.
𝟱. User Query is sent to the LLM together with the data retrieved after function execution.
𝟲. The answer is constructed and returned to the user via the Agent.
𝗠𝘆 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀:
❗️ Will MCP eat up the practice of Native Function Calling? If we adopt the standard then I believe so.
❗️ Will MCP compete with LLM Orchestration frameworks? I believe MCP will replace the Tool use abstractions as they are used today and frameworks will be responsible mostly for managing the topology and state of the Agentic systems long term.
Are you using MCP already to expose Tools to your Agents? Let me know in the comments.
#LLM #AI #MachineLearning
One of the most clever data-security tricks I’ve seen in production?
Temporal RLS.
Row-Level Security (RLS) is a feature in PostgreSQL that lets you control which rows a user can access, directly at the database level.
Instead of relying on application code to filter data, RLS pushes access control into the database itself.
Think of it as a WHERE clause that’s always on, customized for each user or role.
The use case:
A fintech company needed to give analysts access to transaction data, but with a 24-hour delay to minimize fraud and insider trading risk.
Instead of writing app logic or enforcing it in a dashboard tool, they enforced this entirely at the database level.
How?
1. Enable RLS on the table
2. Define a policy that filters rows
3. Force RLS for all access (optional but recommended)
Even if someone queries the database directly, using psql, a BI tool, or a SQL client, they would only see rows older than 24 hours. No exceptions.
- Security was enforced at the source
- Versioned alongside schema changes
- No app code involved
Takeaway
RLS isn’t just for tenant filtering. You can use it to build smart rules like time delays, user-level access, or even soft delete enforcement.
All enforced by the database.
Have you used RLS in creative ways beyond tenant isolation?
Practice for Data Modeling Round for Data Engineering Interview 🔜
We are building ultimate practice platform for Data Engineering interview at DataVidhya
Here you will be able to take your data modeling skills to the next level🚀
After this we are planning to add architecture round prep!
You can start practising coding questions using PySpark, Scala, Python, DBT, and SQL!
Here - https://t.co/318vreqwEN
How To Conduct a Customer Behavior Analysis
Identify customer behavior patterns and predict future behavior so you can adjust your product offerings and marketing strategies accordingly
https://t.co/pmCB84bdrp
Every Backend Engineer should master How To Build APIs
I spent 168 hours studying How To Build APIs for backend engineers, so you don't have to
I studied how top engineers build scalable, performant, & maintainable APIs
Here's a complete list to learn it:
Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, https://t.co/A48DBb1ezH:
The original DeepSeek-R1 paper showed that when developing small(er) reasoning models, distillation gives better results than pure RL. In this paper, researchers follow up on this and investigate ways to improve a small, distilled reasoning models further with RL.
So, using the 1.5B DeepSeek-R1-Distill-Qwen model, they find that with only 7000 training examples and a $42 compute budget, RL fine-tuning can lead to strong improvements. In this case, the improvements are enough outperform OpenAI's o1-preview on the AIME24 math benchmark, for example.
Furthermore, there were 3 interesting learning in that paper:
1. Small LLMs can achieve fast reasoning improvements within the first 50–100 training steps using a compact, high-quality dataset. But the performance quickly drops if training continues too long, mainly due to length limits and output instability.
2. Mixing easier and harder problems helps the model produce shorter, more stable responses early in training. However, performance still degrades over time.
3. Using a cosine-shaped reward function helps control output length more effectively and improves training consistency. But this slightly reduces peak performance compared to standard accuracy-based rewards.
Slack runs on more than 3000 Vitesse MySQL shards serving more than 600,000 writes a second and storing 1PB+ of data.
All this gets shepherded through Kafka into their S3 data lake under an Iceberg format. They basically rolled their own Tableflow. Here's how 👇
They have three types of tables in their data lake:
1. A Change-Data-Capture table (CDC) - an Iceberg table with the raw changelog events from the database 🧊
2. A Mirror table - an Iceberg table that mirrors the Vitesse table 1:1 🪞🧊
3. Legacy DS partition tables - their old stack’s Hive-style parquet tables which they still need to populate via the new pipeline, so that their legacy stack doesn’t break. 🐝
THE STACK
• Debezium - the framework for capturing the CDC data (it’s a Kafka Connect connector) ✳️
• Apache Kafka - the pipe ⭐️
• Apicurio - their schema registry 📝
• The Kafka Iceberg Connector ⭐️🤝🧊
• Hive Metastore - their Iceberg catalog 📖
• S3 - their data lake 🐳
• AWS EMR - their Spark vendor ⚡️
THE PATH OF A MESSAGE
1. A message in sent in the Slack app. It gets inserted into a shard of the MySQL Vitess DB cluster.
2. The Debezium connector consumes this via the MySQL binlog and, using the schema in Apicurio, produces a record to Kafka in an Avro format.
3. The Iceberg connector consumes this Avro record, deserializes it (using the same schema), and persists it into a Parquet file in the CDC Iceberg table.
4. Apache Airflow kicks off a Spark EMR job which uses Spark's incremental read feature to consume just the latest updates from the CDC table. It merges them into the Mirror Iceberg table.
5. Further downstream, daily jobs read both the CDC & Mirror table to produce the daily DS partition in the DS table
6. Other teams run their own jobs to consume the DS partitions in order to create fact/metric tables from it and power their data platform
This sounds relatively simple, but a lot of devils exist in the details.
• write amplification - big tables would have small pieces of input trigger a lot of work. They fixed this in 3 ways: running the job less often, merge-on-read mode (not copy-on-write) and for tables above 1T rows - bucket merge.
• debezium bottleneck - had to implement multi-task support in the Vitess connector (usually debezium connectors run with just a single connect task)
• kafka bottleneck - they had to increase partitions for more parallelism and therefore scale, and this led them down a deep rabbit hole on how to preserve ordering (long story)
• vitess bottleneck - further sharding an existing Vitess shard required establishing a shard lineage so that they could keep message order in the pipeline
All of this was done AT SCALE.
• Their Debezium runs 20 Kafka Connect clusters with 300 workers.
• Their Vitess cluster has over 800 tables with 600k writes/sec
• >1PB in the database
Their old stack consisted of a batch job which:
• 💵 cost them upwards of millions of dollars a year
• 👵 was based on Apache Sqoop, which was retired (read: abandoned) 3 years ago already
• 🐌 very large end to end latencies (up to 48hr to see changes)
With this new streaming stack they reduced their costs by 90%.
Not only that, but they improved their DS Partition tables are now ready in 10-20 minutes, whereas before it took them 1-2 days. 👌
This new pipeline is more complex to manage, but ended up worth it for them.
Fun note - while still testing they forgot to run Iceberg's snapshot expiration on their copy-on-write table that merged updates every hour.
In very little time, their few TB dataset ballooned to 650TB in S3. Ouch.
Every Backend Engineer should master Design Patterns
I spent 168 hours studying 23 Design Patterns for software engineers, so u don't have to
I studied all 23 Design Patterns used by software engineers to build scalable, performant, & maintainable code
Here's the complete list
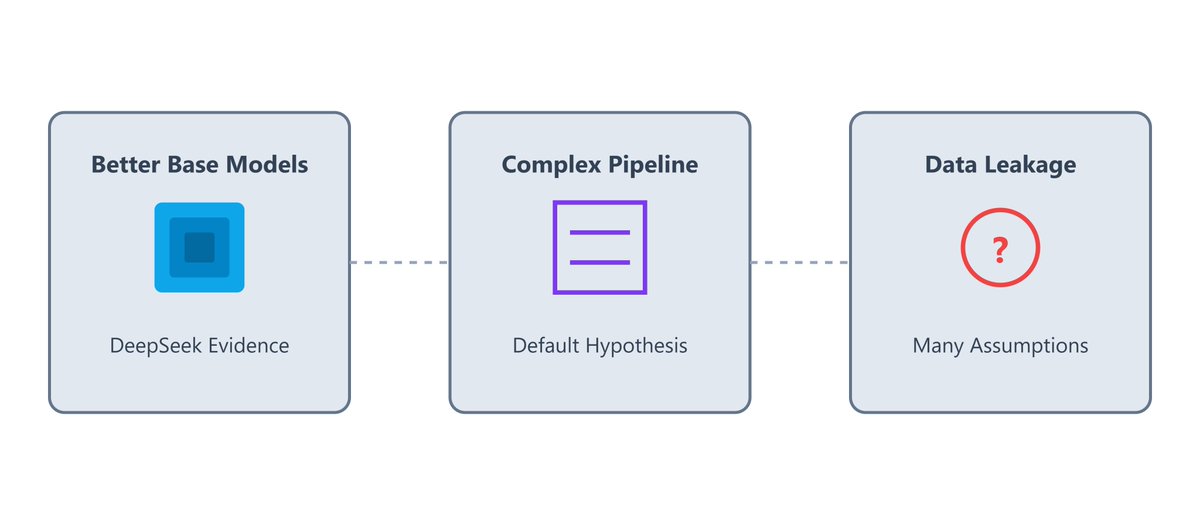
Training LLMs with Reinforcement Learning (RL) isn’t a new idea.
So why does it suddenly seem to be working now (o1/DeepSeek)?
Here are a few theories and my thoughts on each of them: (1/N)