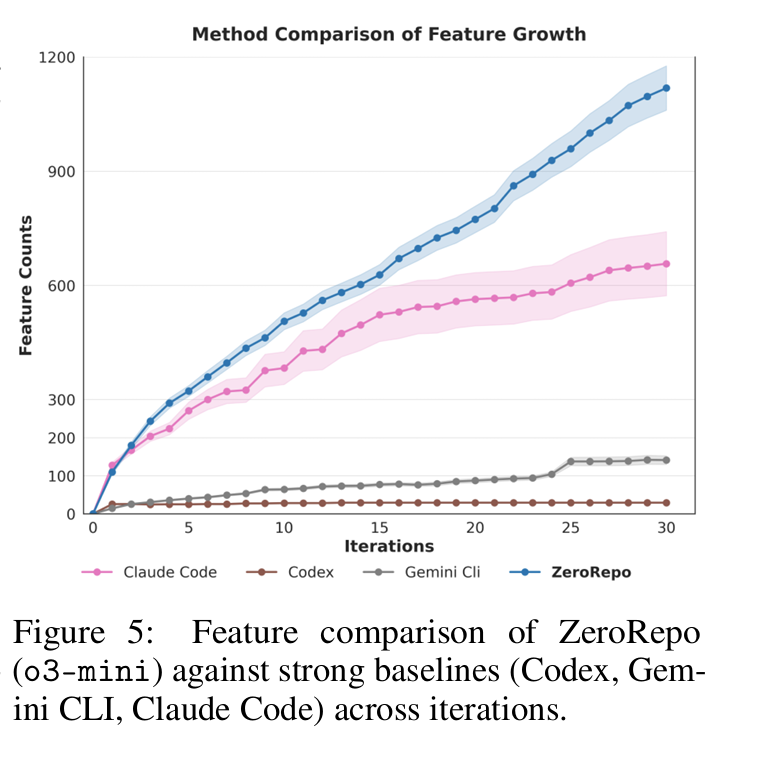
Excited to share ZeroRepo (Accepted to #ICLR2026)! 🌍 It's a graph-based framework that beats SOTA agents in generating complex repositories.
Code is live: https://t.co/7tqnXqZAEC #AI#DevTools
🔥Stop repo agents from reasoning on fragmented docs/graphs. Building on prior RPG/ZeroRepo, we propose RPG-Encoder: a unified repository planning graph that integrates semantic intent with static structure into one navigable representation.
[6 / 7] To analyze agent behavior, we see a “search-then-zoom” pattern: traverse RPG first, then fetch details. To diagnose failures, we sample failed runs and group errors (tool/execution, search, reasoning, context) to pinpoint breakpoints.
[5 / 7] To analyze representational efficiency, we report Steps, Cost, and Eff.=Acc@5/Cost on SWE-bench Verified. RPG-Encoder is most cost-effective: ~6–7 steps, $0.18–$0.22 per task, best Eff. (4.63 on GPT-4.1; 4.15 on GPT-5), suggesting less redundant exploration.
4/7] To study RPG evolution, we compare full reconstruction against diff-based incremental updates across repository commits. To our finding, incremental maintenance reduces overhead by 95.7% while keeping the representation lightweight as the repo evolves.
[3/7](1) Repo understanding: evaluated on SWE-bench Verified/Live; 93.7% Acc@5 (Verified) and >+10% over best baseline (Live), showing stronger repo-scale localization. (2) Repo reconstruction: evaluated on RepoCraft; 98.5% coverage, showing RPG is a faithful semantic blueprint.
[2/7] building on RPG/ZeroRepo, we generalize RPG into RPG-Encoder. (i) Encode: code → RPG, fusing lifted semantics + static dependencies. (ii) Evolve: incrementally update graph topology from diffs. (iii) Operate: unify search/fetch/explore for repo-scale navigation.
[1/7] Today's repo agents rely on fragmented artifacts (flat context, docs, partial graphs), losing global consistency. This makes repo-scale navigation/planning brittle—motivating one actionable representation for the whole pipeline.
🎉"FEA-Bench" is accepted at ACL 2025! We introduce a new benchmark of repo-level code generation for feature implementation.
LLMs still struggle at, but models like R1 show promise. 📄 https://t.co/lwd7zGg5lz
🔗 https://t.co/bJMy4ocESN
🤗 https://t.co/QmVxS0bpZD
#LLM#ACL2025
Exciting news! The data from our paper is now open source. Dive into the details and explore the insights.
Paper link: https://t.co/KqOVLUzeLN
Huggingface Dataset: microsoft/EpiCoder-func-380k · Datasets at Hugging Face
Get the latest open-source data & code first! Follow us now
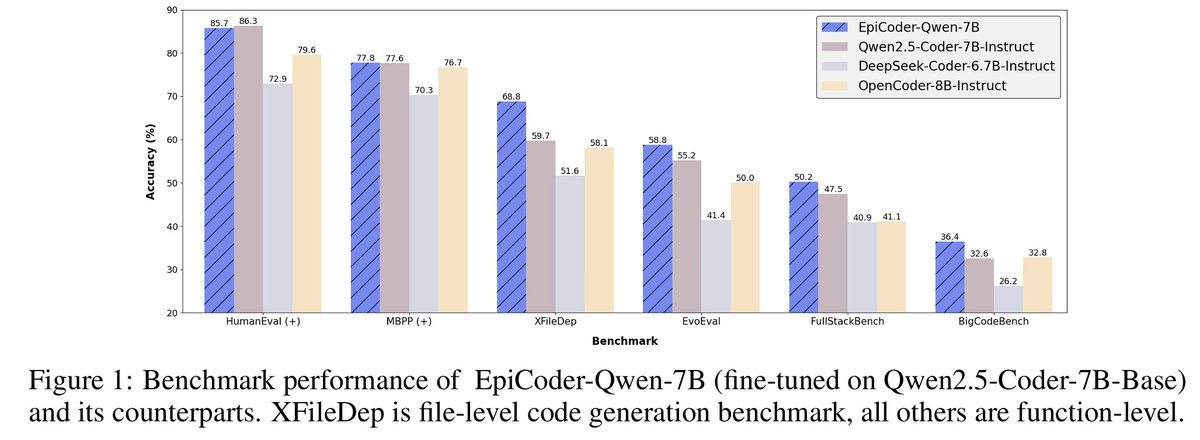
🚀 Introducing EpiCoder: a hierarchical feature tree-based framework for diverse and intricate code generation.
🔍 Outperforming benchmarks, it handles everything from simple functions to multi-file projects deftly.
📢 Open source release soon!
🔗 https://t.co/c9xu0OrC42
🚀 Introducing EpiCoder: a hierarchical feature tree-based framework for diverse and intricate code generation.
🔍 Outperforming benchmarks, it handles everything from simple functions to multi-file projects deftly.
📢 Open source release soon!
🔗 https://t.co/c9xu0OrC42
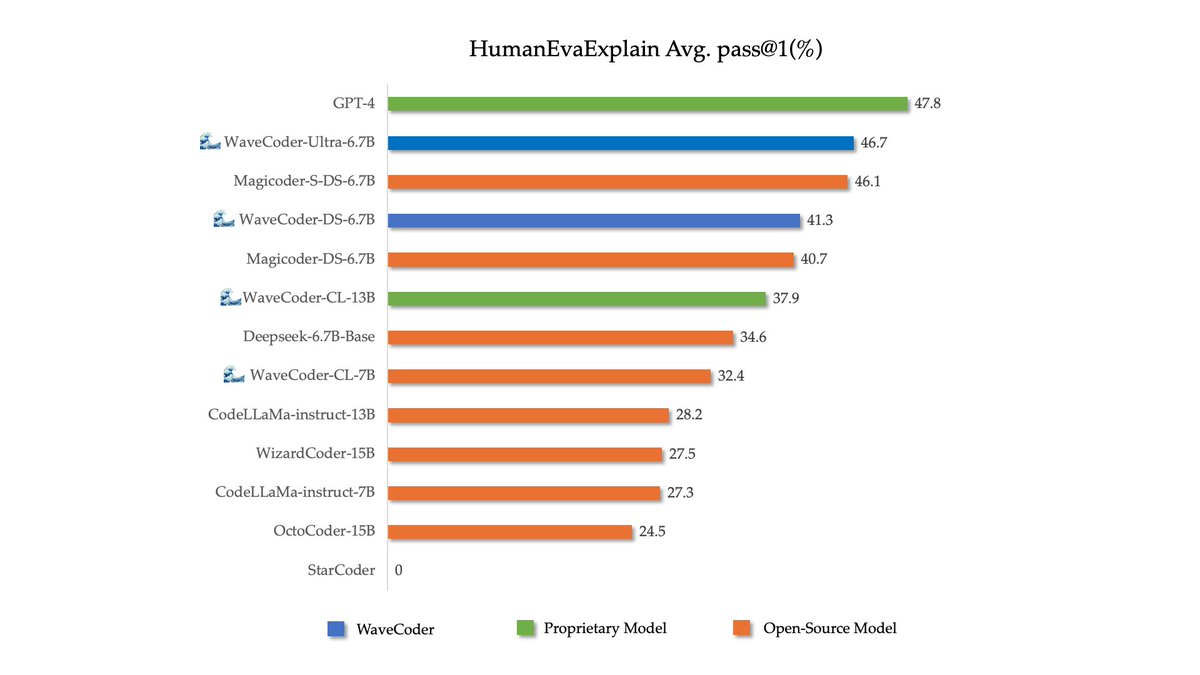
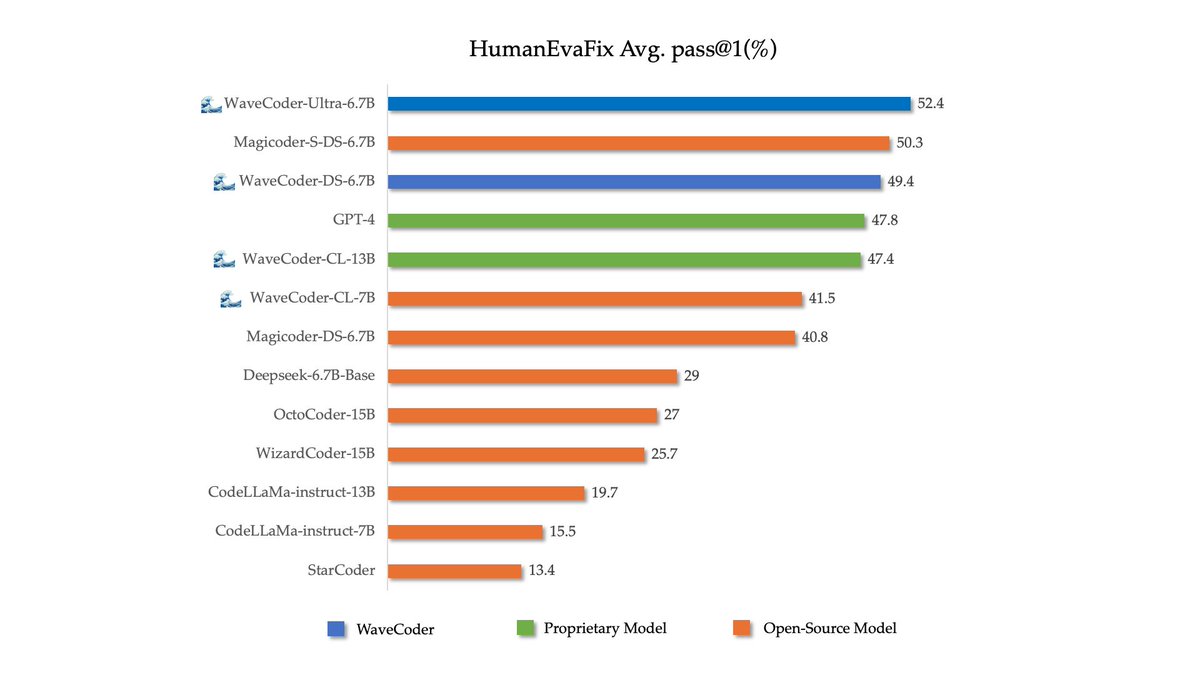
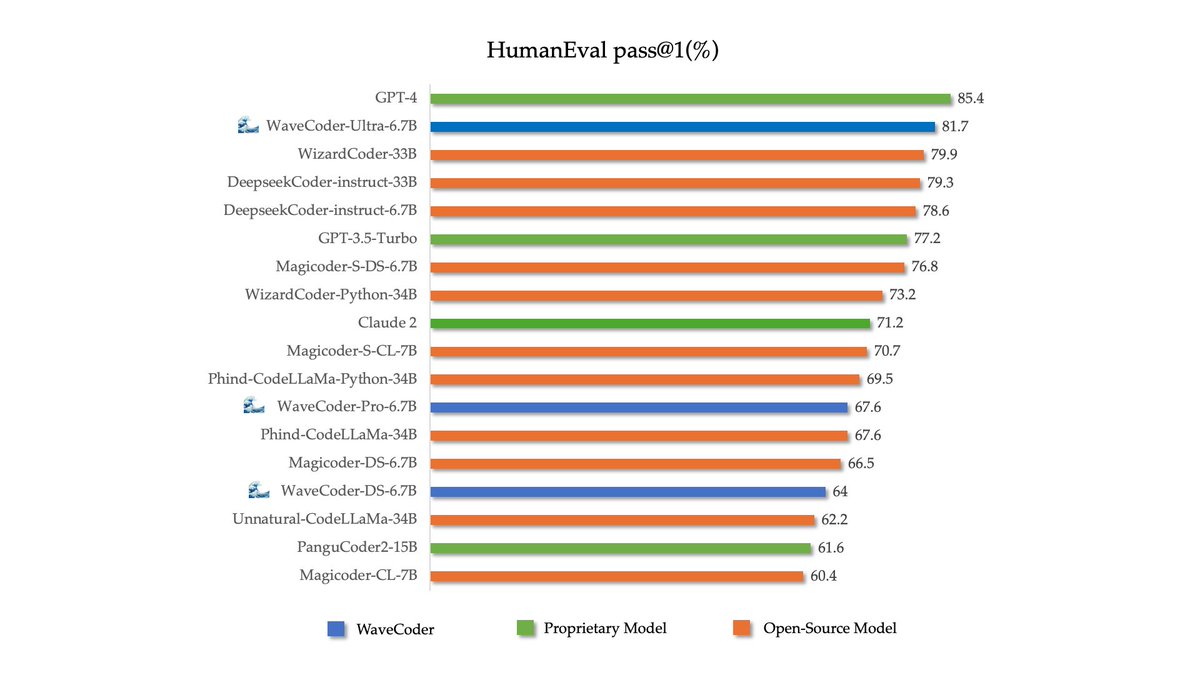
Nice experience on #ACL2024 , and glad to know that WaveCoder-Ultra-6.7B win the 9th place in DS-1000 Leaderboard. Now everyone can download it on https://t.co/mI6VuiiX4x
Check out our repo: https://t.co/EwbxPDUgJn
(3/3) Auto Evol eliminates the need for human efforts and expert knowledge. With it, anyone can create high-quality instruction fine-tuning data and fine-tune a large language model with excellent performance.
(1/3) Quite interesting work!Evol-Instruct has recently undergone a significant update and upgrade, introducing the brand-new automatic evolutionary framework, Auto Evol.
🔥 Excited to share the other key Technology of WizardLM-2!
📙AutoEvol: Automatic Instruction Evolving for Large Language Models
🚀We build a fully automated Evol-Instruct pipeline to create high-quality, highly complex instruction tuning data:
-------- 🧵 --------
👉Motivation First:
Over the past six months, we have dedicated ourselves to exploring methods to scale up synthetic training for LLMs. Although Evol-Instruct has demonstrated excellent performance in creating powerful post-training data, it relies too heavily on the efforts of human experts to design specific evolutionary methods for specific tasks.
Once Evol-Instruct is applied to an entirely new complex task, the methods for executing evolution need to be redesigned. This limitation of Evol-Instruct makes scaling up extremely challenging, prompting us to develop a new method, 💻Auto Evol-Insturct💻, that can evolve instruction data automatically.
Auto Evol allows the training of WizardLM2 to be conducted with nearly an unlimited number and variety of synthetic data.
Let's see: 🧐
1. Limitations of Evol-Instruct:
Evol-Instruct takes the high-quality data as a starting point, and further iteratively refines it using LLMs, improving its complexity and diversity. It has demonstrated superior performance across a broad range of public benchmarks that evaluate diverse capabilities, including instruction following (WizardLM), code generation (WizardCoder), and mathematical reasoning (WizardMath). While Evol-Instruct exhibits outstanding performance, its heavy reliance on heuristic efforts presents notable challenges. Whenever it is used for a completely new task, the methods for execution evolution need to be redesigned. Such a process requires a high level of expertise and considerable costs, hindering its adaptation to a wider spectrum of capabilities.
2. We want to build a fully automated Evol-Instruct pipeline
Auto Evol-Instruct automatically designs evolving methods that make given instruction data more complex, enabling almost cost-free adaptation to different tasks by only changing the input data of the framework. From below figure, we can see the iterative process of optimizing the initial evolving method e0 into the optimal evolving method e∗, which specifically outlines the transition from et−1 to et. We refer to the model used for evolution as the evol LLM, and the model used for optimization as the optimizer LLM. This optimization process involves two critical stages: (1) Evol Trajectory Analysis: The optimizer LLM carefully analyzes the potential issues and failures exposed in instruction evolution performed by evol LLM, generating feedback for subsequent optimization. (2) Evolving Method Optimization: The optimizer LLM optimizes the evolving method by addressing these identified issues in feedback. These stages alternate and repeat to progressively develop an effective evolving method using only a subset of the instruction data. Once the optimal evolving method is identified, it directs the evol LLM to convert the entire instruction dataset into more diverse and complex forms, thus facilitating improved instruction tuning.
3. Fully AI-driven Evol-Instruct can outperform the Evol-Instruct used by human experts.
Our experiments show that the evolving methods designed by Auto Evol-Instruct outperform the Evol-Instruct methods designed by human experts in instruction tuning across various capabilities, including instruction following, mathematical reasoning, and code generation. As shown in the below table, on the instruction following task, Auto Evol-Instruct can achieve a improvement of 10.44% over the Evol method used by WizardLM-1 on MT-bench; on the code task HumanEval, it can achieve a 12% improvement over the method used by WizardCoder; on the math task GSM8k, it can achieve a 6.9% improvement over the method used by WizardMath.
4. Scaling Evol-Instruct to various domains and tasks
With the new technology of Auto Evol-Instruct, the evolutionary synthesis data of WizardLM-2 has scaled up from the three domains of chat, code, and math in WizardLM-1 to dozens of domains, covering tasks in all aspects of large language models. This allows Arena Learning to train and learn from an almost infinite pool of high-difficulty instruction data, fully unlocking all the potential of Arena Learning.
For more details, please refer to:
Paper: https://t.co/KRY1T8IDg5
Project: https://t.co/3NH2xUKISy
We are working with our legal team to publicly release the code of Auto Evol-Instruct.
(2/3) Given any task data in any domain, Auto Evol can automatically plan and design methods for instruction evolution(enhancing the complexity and quality of instruction data to improve the post-training effects of large language models).
@art_zucker Hi, Arthur, we are preparing for open-source related matters. Once everything is ready, we will open-source the model on https://t.co/cPHN5lCZn2
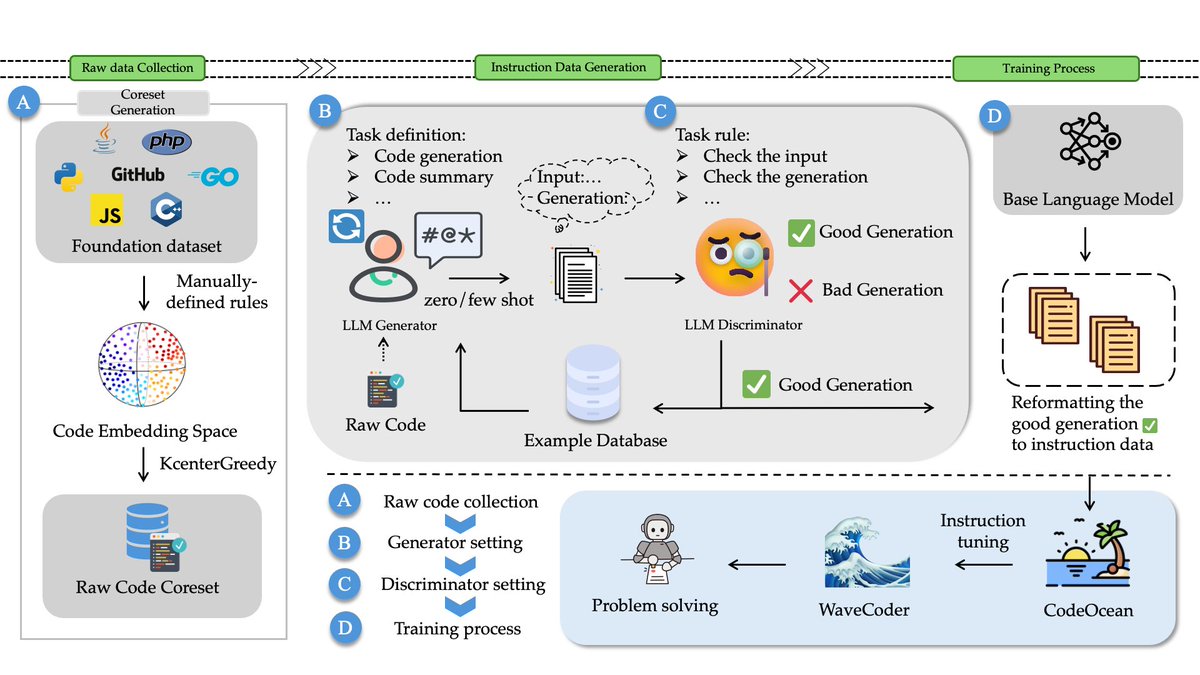
🌊🌊🌊Introduce WaveCoder-Ultra-6.7B with the closest capabilities to GPT-4 so far.
Arxiv:https://t.co/SF8URck1is
WaveCoder-Ultra-6.7B is the newest SOTA open-source Code LLM on mutiple tasks.
We are in the process of preparing for open-source related matters. Please stay tuned. Once everything is ready, we will announce the latest updates through this account.




















![TeamCodeLLM_AI's tweet photo. [7/7] Ablations: (1) Understanding: dropping semantics hurts function-level localization most; dropping dependencies also lowers retrieval. (2) Reconstruction: removing file/function metadata collapses hierarchy, reducing code volume and pass rate. RPG still beats docs. https://t.co/IX6MLVQSA2](https://pbs.twimg.com/media/HAUZPi9aUAA5mGU.jpg)

![TeamCodeLLM_AI's tweet photo. [6 / 7] To analyze agent behavior, we see a “search-then-zoom” pattern: traverse RPG first, then fetch details. To diagnose failures, we sample failed runs and group errors (tool/execution, search, reasoning, context) to pinpoint breakpoints. https://t.co/erQMLOnHgi](https://pbs.twimg.com/media/HAUZLGqbkAA6o89.jpg)
![TeamCodeLLM_AI's tweet photo. [5 / 7] To analyze representational efficiency, we report Steps, Cost, and Eff.=Acc@5/Cost on SWE-bench Verified. RPG-Encoder is most cost-effective: ~6–7 steps, $0.18–$0.22 per task, best Eff. (4.63 on GPT-4.1; 4.15 on GPT-5), suggesting less redundant exploration. https://t.co/tgjo6oqYlE](https://pbs.twimg.com/media/HAUZGH8bAAEJCK5.png)
![TeamCodeLLM_AI's tweet photo. 4/7] To study RPG evolution, we compare full reconstruction against diff-based incremental updates across repository commits. To our finding, incremental maintenance reduces overhead by 95.7% while keeping the representation lightweight as the repo evolves. https://t.co/RY5DZC3LUL](https://pbs.twimg.com/media/HAUZA05a0AAkW1I.jpg)
 Repo understanding: evaluated on SWE-bench Verified/Live; 93.7% Acc@5 (Verified) and >+10% over best baseline (Live), showing stronger repo-scale localization. (2) Repo reconstruction: evaluated on RepoCraft; 98.5% coverage, showing RPG is a faithful semantic blueprint. https://t.co/q3QbhfX5or](https://pbs.twimg.com/media/HAUYjKwbYAEXUBU.jpg)
![TeamCodeLLM_AI's tweet photo. [2/7] building on RPG/ZeroRepo, we generalize RPG into RPG-Encoder. (i) Encode: code → RPG, fusing lifted semantics + static dependencies. (ii) Evolve: incrementally update graph topology from diffs. (iii) Operate: unify search/fetch/explore for repo-scale navigation. https://t.co/wzbOq6sUkc](https://pbs.twimg.com/media/HAUYVWrbAAAt-Xs.jpg)
![TeamCodeLLM_AI's tweet photo. [1/7] Today's repo agents rely on fragmented artifacts (flat context, docs, partial graphs), losing global consistency. This makes repo-scale navigation/planning brittle—motivating one actionable representation for the whole pipeline. https://t.co/VuczS2K5UP](https://pbs.twimg.com/media/HAUYO1RacAA5zxA.jpg)