I help 400,000+ engineers level up, one idea at a time.
🚀 Weekly insights on:
🔹 Software engineering
🔹 Tech leadership
🔹 Career growth
🧠 Read by staff/principal engineers, CTOs & builders at top companies.
👉 Join 46,000+ smart readers: https://t.co/vwmiYoFsBf
Recently, I was a guest on the Untrapping Product Teams podcast with David Pereira, where we talked about a mindset shift from good to great engineers
Also, we talked about my new book "Laws of Software Engineering" and what product teams can learn from it
Check it out: https://t.co/PLFoYQdqJX
𝗛𝗼𝘄 𝗼𝗻𝗲 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗶𝗼𝗻 𝗳𝗶𝗹𝗲 𝘁𝗼𝗼𝗸 𝗱𝗼𝘄𝗻 𝟴.𝟱 𝗺𝗶𝗹𝗹𝗶𝗼𝗻 𝗰𝗼𝗺𝗽𝘂𝘁𝗲𝗿𝘀
On July 19, 2024, CrowdStrike pushed a routine update to its Falcon sensor. A single file, Channel 291, had a logic error that caused an out-of-bounds memory read in the Windows kernel. Machines didn't just crash, they 𝗯𝗼𝗼𝘁𝗹𝗼𝗼𝗽𝗲𝗱, dying before the network came up. That was an important detail, because it was not possible to fix it remotely. Every one of those 8.5 million machines needed a human at the keyboard to boot into recovery and delete one file by hand. Airlines, hospitals, and banks froze. It was a Friday morning.
That's 𝗠𝘂𝗿𝗽𝗵𝘆'𝘀 𝗟𝗮𝘄 at production scale. "Anything that can go wrong will go wrong." It's credited to Edward A. Murphy Jr., an engineer on US Air Force rocket sled tests in 1949. Aerospace took it first. Software has lived with it for as long as we've shipped bugs.
I heard many times, "This should never happen". If it can happen, you're choosing not to handle it. So good engineers code defensively: validate input, check for nulls, handle the file that won't be there, fail in a way you can recover from. They treat every 𝘀𝗶𝗻𝗴𝗹𝗲 𝗽𝗼𝗶𝗻𝘁 𝗼𝗳 𝗳𝗮𝗶𝗹𝘂𝗿𝗲 𝗮𝘀 𝗮 𝗳𝘂𝘁𝘂𝗿𝗲 𝗼𝘂𝘁𝗮𝗴𝗲 with a date not yet assigned.
And they respect the timing, because Sod's Law is the meaner sibling. Things fail at the worst possible moment, during the board demo, over the holiday weekend, the morning your on-call lead is unreachable. CrowdStrike shipped on a Friday. The recovery over the weekend. Murphy says it can break, Sod says 𝗶𝘁 𝘄𝗶𝗹𝗹 𝗯𝗿𝗲𝗮𝗸 𝘄𝗵𝗲𝗻 𝗶𝘁 𝗵𝘂𝗿𝘁𝘀 𝗺𝗼𝘀𝘁.
You can't outlaw failure. You design for it, rehearse the recovery, and stop deploying on Fridays.
You didn't actually read your last AI-generated PR, did you?
Don't feel bad. The person who generated it probably didn't either.
You feel it later. A config tweak slips through in a diff nobody looked at closely. Three weeks pass, and then at 2 a.m. latency spikes, a customer notices before you do, and the context that would explain why is scattered across a Sentry alert, a Datadog trace, a Jira ticket, the original PR, and one engineer who's asleep.
Catching the bad change before merge is one problem. CodeRabbit's reviewer seems to handle that well. But a bigger issue is everything after, when the context is spread across six tools.
That's what @coderabbitai's agent is built for. It sits in Slack and connects to the tools the incident is already scattered across: Sentry, Datadog, Jira, the repo itself.
You can @ mention it in the channel. Then it reads the traces, identifies the specific change that caused the spike, and has a fix and a draft postmortem ready for you to review. And it remembers, too. The fixes and conventions your team uses stick around, so nobody has to re-explain the same context every time.
What surprised me the most was the pricing. It is per active minute, around $30 an hour, billed by the second the agent is actually running. Not per token or per model tier.
So, it doesn't replace your engineers, but it handles the repeatable work and the scattered context, so the people on your team can spend their time on the calls that need their input.
See what it does on your stack: https://t.co/YVj0c3qEmh
𝗪𝗲 𝘀𝗽𝗲𝗻𝘁 𝘄𝗲𝗲𝗸𝘀 𝗱𝗲𝘀𝗶𝗴𝗻𝗶𝗻𝗴 𝗼𝘂𝗿 𝘀𝗲𝗿𝘃𝗶𝗰𝗲 𝘁𝗼 𝗵𝗮𝗻𝗱𝗹𝗲 𝗮 𝗺𝗶𝗹𝗹𝗶𝗼𝗻 𝘂𝘀𝗲𝗿𝘀. 𝗪𝗲 𝗵𝗮𝗱 𝘁𝗲𝗻.
We were an early-stage startup with no traction, and, of course, we used Kubernetes for scale that didn't yet exist. One teammate finally said the thing out loud: before you worry about a million users, make sure a hundred of them actually want the product. We were optimizing for a problem we hadn't earned.
That's 𝗽𝗿𝗲𝗺𝗮𝘁𝘂𝗿𝗲 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻, and Donald Knuth named it in a 1974 paper with a line that became a proverb: "Premature optimization is the root of all evil."
Almost everyone quotes half of it, but not the full version. Knuth said to ignore small efficiencies about 𝟵𝟳% 𝗼𝗳 𝘁𝗵𝗲 𝘁𝗶𝗺𝗲, and not to skip the critical 3%. He was never against fast code. He was against making code fast before you know which code matters.
Why did we say this? Because optimization isn't free. You buy speed with complexity, and that complexity stays for the life of the system. Pay that price before you've found the bottleneck, and you get the worst trade: harder code that wasn't even slow. I've watched an engineer spend two days hand-tuning a function that runs once at startup, while the loop eating most of the runtime sat untouched.
The discipline is boring, and it works. Make it work, make it right, then make it fast. When "fast" comes up, profile before you touch anything, because the bottleneck is almost never where you guessed. Roughly 20% of the code burns 80% of the runtime. Your job is to find that 20% with 𝗮 𝗺𝗲𝗮𝘀𝘂𝗿𝗲𝗺𝗲𝗻𝘁, 𝗻𝗼𝘁 𝗮 𝗵𝘂𝗻𝗰𝗵, and leave the rest alone.
The 3% is real. Sometimes you know on day one that a path is critical, a trading engine, a tight inner loop, and you design it with care. That's not premature; that's informed. The rule was never "don't optimize." It's "𝗱𝗼𝗻'𝘁 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲 𝗼𝗻 𝗮 𝗴𝘂𝗲𝘀𝘀."
Build it simple, measure it honestly, then make the slow part fast.
𝗗𝗲𝗹𝗲𝘁𝗶𝗻𝗴 𝟭,𝟱𝟬𝟬 𝗹𝗶𝗻𝗲𝘀 𝗼𝗳 𝗰𝗼𝗱𝗲 𝗺𝗮𝗿𝗸𝗲𝗱 𝗼𝗻𝗲 𝗼𝗳 𝗺𝘆 𝗯𝗲𝘀𝘁 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝘀 𝗮𝘀 𝗮 𝗹𝗼𝘄 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗲𝗿
But that deletion made the system measurably faster. It also reduced his line count, and what was funny was that the team was scored on the lines of code written. Management, none of whom were engineers, had decided that more code meant more productivity. So the engineer who made the system simpler looked lazy, while the ones padding it with copy-paste looked like stars.
That's 𝗚𝗼𝗼𝗱𝗵𝗮𝗿𝘁'𝘀 𝗟𝗮𝘄. Economist Charles Goodhart noticed it in monetary policy. Anthropologist Marilyn Strathern gave it the line everyone quotes: "When a measure becomes a target, it ceases to be a good measure."
A metric is a stand-in for the thing you actually care about: lines of code, tickets closed for quality. Reward the stand-in, and people optimize the stand-in until 𝗶𝘁 𝗾𝘂𝗶𝗲𝘁𝗹𝘆 𝘀𝘁𝗼𝗽𝘀 𝘁𝗿𝗮𝗰𝗸𝗶𝗻𝗴 𝘁𝗵𝗲 𝗿𝗲𝗮𝗹 𝘁𝗵𝗶𝗻𝗴. The number climbs. What it stood for walks away.
Same mistake, new units. Today, some teams measure AI tokens consumed (called tokemaxxing), where more counts as better, and a few include it directly in performance reviews. More tokens, more "work," better engineer. It's 𝗹𝗶𝗻𝗲𝘀 𝗼𝗳 𝗰𝗼𝗱𝗲 𝘄𝗶𝘁𝗵 𝗮 𝗳𝗿𝗲𝘀𝗵 𝗱𝗮𝘀𝗵𝗯𝗼𝗮𝗿𝗱.
It happens anywhere a number gets a bonus attached. Reward coverage percentage, and you get trivial tests that assert nothing, while the hard integration tests stay unwritten. Reward tickets closed, and one bug becomes five. The metric goes green. Quality doesn't move.
Before you attach a reward to a number, ask one question: could gaming it leave you worse off than measuring nothing at all? If yes, you're 𝗼𝗻𝗲 𝗽𝗼𝗹𝗶𝗰𝘆 𝗮𝘄𝗮𝘆 𝗳𝗿𝗼𝗺 𝗯𝗿𝗲𝗲𝗱𝗶𝗻𝗴 𝗰𝗼𝗯𝗿𝗮𝘀.
With the rise of AI, everyone thinks the rules of software engineering don't hold anymore
They are wrong. A lot.
What I found is that old laws are here to stay, and even a few of them are even stronger than before.
Take an example of Conway's Law. The system is shaped by how its builders communicate. Now, we build with agents, and the same thing happens just one layer down. Boundaries between agents, the handoffs, and where it breaks trace back to how you split the work. If your agents don't talk to each other, you will get architecture that doesn't either. The law is now on the orchestration level.
Goodhart's Law is maybe even more visible. It says that the moment a measure becomes a target, it stops telling the real truth. We see this in many companies now with tokenmaxxing: people optimize their work to be at the top of token usage benchmarks because companies have started measuring it, but the real impact is missing.
Don't forget Hyrum's Law too. Given the system has enough users, every observable behavior becomes something someone depends on. AI models make this worse, because they are non-deterministic. A pipeline parses the output once, but the next time you depend on that pipeline, that could be changed.
None of these laws are new; some of them are a few decades old. AI didn't change them; it just raised the price of ignoring them.
I wrote about these and more than 60 others in my book Laws of Software Engineering.
𝗗𝗼 𝘆𝗼𝘂 𝗸𝗻𝗼𝘄 𝘁𝗵𝗮𝘁 𝗺𝗼𝘀𝘁 𝘄𝗲𝗯 𝗽𝗮𝗴𝗲𝘀 𝗮𝗿𝗲 𝘁𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹𝗹𝘆 𝗯𝗿𝗼𝗸𝗲𝗻?
Still, your browser renders them anyway, and that's on purpose.
That tolerance has a name. It's called 𝗣𝗼𝘀𝘁𝗲𝗹'𝘀 𝗟𝗮𝘄, also the Robustness Principle: "Be conservative in what you do, be liberal in what you accept from others." Jon Postel wrote it into the early TCP specifications in 1980, and it shaped how the Internet learned to talk to itself.
The idea has two halves, and the second half is the famous one. Be strict in what you send, following the spec to the letter. Be lenient about what you accept, so a request with an odd header order or a field you can infer is still processed rather than dropped. A browser meets a half-closed tag and renders the page. An email client hits a stray encoding and shows the message anyway. If every system rejected every small deviation, the web would've collapsed.
For decades, this read as pure wisdom. Then the bill came due. Every system that quietly swallows broken input teaches the world that sending it is fine, so producers never fix their bugs, because nothing makes them. Worse, two lenient parsers that guess differently become a security hole. An attacker crafts input that your gateway reads one way, and your backend reads another, then passes through the gap between them. Leniency that started as kindness becomes 𝗮 𝗽𝗹𝗮𝗰𝗲 𝘁𝗼 𝗵𝗶𝗱𝗲.
The pushback got formal. An IETF draft argued that the maxim is actively harmful, and HTML5 stopped treating error recovery as each browser's private mercy and codified the rules in the spec itself. The fix wasn't to get strict. It was to make the leniency 𝗲𝘅𝗽𝗹𝗶𝗰𝗶𝘁 𝗮𝗻𝗱 𝗶𝗱𝗲𝗻𝘁𝗶𝗰𝗮𝗹 𝗲𝘃𝗲𝗿𝘆𝘄𝗵𝗲𝗿𝗲, so no two systems could disagree about what a malformed input means.
So the rule still holds, with a sharper edge. Be strict in what you emit. Be liberal in what you accept, but never silently. Take the variation you can read exactly one way, log it, and reject anything ambiguous instead of guessing.
Tolerance is a factor in decision-making. It's a 𝗯𝘂𝗴 𝗳𝗮𝗰𝘁𝗼𝗿𝘆 when it's a reflex.
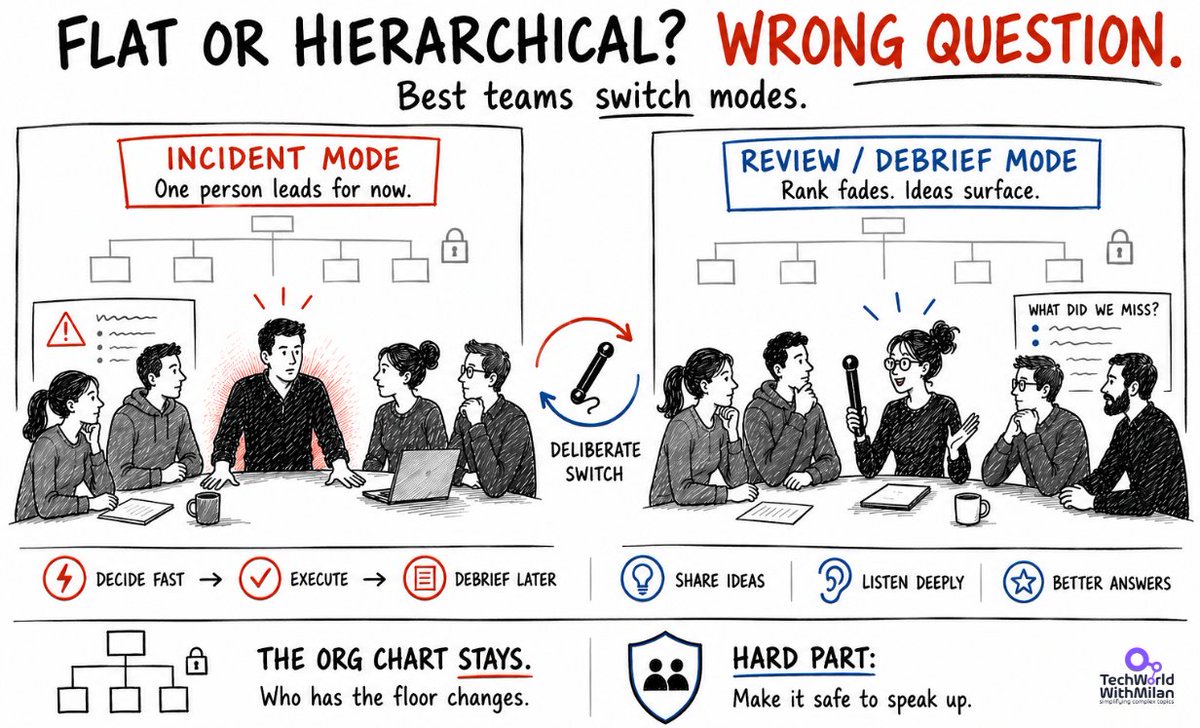
𝗦𝗵𝗼𝘂𝗹𝗱 𝘁𝗲𝗮𝗺𝘀 𝗯𝗲 𝗵𝗶𝗲𝗿𝗮𝗿𝗰𝗵𝗶𝗰𝗮𝗹 𝗼𝗿 𝗳𝗹𝗮𝘁?
For over a decade, tech has argued about whether teams should be flat or hierarchical. Both sides missed the point.
Lindy Greer at Michigan Ross ran five studies on this, and the result doesn't fit either camp. Her best-performing teams weren't flat or hierarchical. They moved between the two, deliberately, depending on what the work needed that day. She calls it hierarchical adaptability. The org chart never changes. What changes is who actually has the floor.
If you run engineering, you already do some version of this. Think about the last incident you ran. Nobody opened a vote. One person took control, everyone else executed, and the real discussion happened later in the postmortem. Now picture a design review run that same way, with one loud senior voice leading the whole thing. You lose the ideas you initially created the meeting for.
The teams that struggle are the ones with only one setting. Stay flat all the time, and you freeze when production is down, and someone just needs to decide. Stay top-down all the time, and the one person who saw it coming says nothing.
Greer's teams made the switch obvious. Military units take off their rank before a debrief, then put it back on at the door. Some of the startups she watched passed a physical object around the room, and holding it meant "talk, the rest of us listen." Sounds stupid, but it worked, because everyone knew which mode they were in.
What we can learn from this is that most engineering orgs are bad at going flat, not at being hierarchical. Handing a senior person authority is easy. Making it genuinely safe for a junior to say "you're wrong" in the ten minutes when that's their job is the hard part. If people don't trust that the flat moment is real, they stay quiet, and nothing changes.
So the question was never flat or hierarchical. It's whether you know which one the moment needs, and whether your team knows it too.
𝗪𝗵𝘆 𝗶𝘀 𝘆𝗼𝘂𝗿 𝗽𝗿𝗼𝗷𝗲𝗰𝘁 𝗮𝗹𝘄𝗮𝘆𝘀 𝗹𝗮𝘁𝗲?
There is a Hofstadter's Law, which says: "It always takes longer than you expect, even when you take into account Hofstadter's Law."
Douglas Hofstadter wrote that in his 1979 book, "Gödel, Escher, Bach". The joke loops back on itself. Even after you pad the estimate because you know you always underestimate, you still underestimate. 𝗞𝗻𝗼𝘄𝗶𝗻𝗴 𝘁𝗵𝗲 𝘁𝗿𝗮𝗽 𝗱𝗼𝗲𝘀𝗻'𝘁 𝗴𝗲𝘁 𝘆𝗼𝘂 𝗼𝘂𝘁 𝗼𝗳 𝗶𝘁.
Let's take Berlin Brandenburg Airport as an example. The planners reviewed the original schedule, deemed it unrealistic, and pushed the software integration estimate from 18 months to 30 months. 𝗧𝗵𝗲𝘆 𝗮𝗰𝗰𝗼𝘂𝗻𝘁𝗲𝗱 𝗳𝗼𝗿 𝘁𝗵𝗲 𝗹𝗮𝘄 𝗮𝗻𝗱 𝘀𝘁𝗶𝗹𝗹 𝗹𝗼𝘀𝘁. The airport opened in 2020, about nine years late. Costs tripled, to near €7 billion. What sank it wasn't ambition. It was the fire safety and smoke extraction systems that kept failing inspection, plus thousands of small defects for which nobody had scheduled time.
That's the real shape of Hofstadter's Law. Estimates miss not because we're lazy but because the work hides from us. It's the dependency upgrade that breaks three other things, or the one engineer who understood the legacy module, who just quit your company. None of it shows up in the plan, because 𝘆𝗼𝘂 𝗰𝗮𝗻'𝘁 𝘀𝗰𝗵𝗲𝗱𝘂𝗹𝗲 𝘁𝗵𝗲 𝗽𝗿𝗼𝗯𝗹𝗲𝗺𝘀 𝘆𝗼𝘂 𝗵𝗮𝘃𝗲𝗻'𝘁 𝗺𝗲𝘁 𝘆𝗲𝘁.
Set Hofstadter next to 𝗣𝗮𝗿𝗸𝗶𝗻𝘀𝗼𝗻'𝘀 𝗟𝗮𝘄 and you get a warning with two edges. Pad too little and delays catch you. Pad too much and the work expands to fill whatever time you give it.
My own rule keeps it simple:
- If something takes two minutes, I do it now and skip the estimate.
- If it's "a few minutes," I plan an hour.
- If it's "a few hours," I plan a day.
We never estimate things perfectly, but we can stop being surprised by the same thing on every project.
"𝗪𝗲'𝗿𝗲 𝟵𝟬% 𝗱𝗼𝗻𝗲" 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗼𝘀𝘁 𝗲𝘅𝗽𝗲𝗻𝘀𝗶𝘃𝗲 𝘀𝗲𝗻𝘁𝗲𝗻𝗰𝗲 𝗶𝗻 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲
It sounds like the finish line, but I find that it's usually the halfway mark
"The first 90% of the code accounts for the first 90% of the development time. The remaining 10% of the code accounts for the other 90% of the development time." Tom Cargill at Bell Labs coined it.
Jon Bentley printed it in his 1985 "Bumper-Sticker Computer Science" column for Communications of the ACM, and it stuck. The math is a joke. The lesson isn't.
The first 90% is the part you can see, the core features and the happy path, the stuff that demos well. You can plan it because you understand it. The last 10% is everything you couldn't predict from the outside: the error states nobody clicked through in the demo, the one customer whose data breaks an assumption you didn't know you'd made, the load test that surfaces an N+1 query, the accessibility pass, the rollback path you hope never to use. 𝗡𝗼𝗻𝗲 𝗼𝗳 𝗶𝘁 𝘄𝗮𝘀 𝘃𝗶𝘀𝗶𝗯𝗹𝗲 𝘄𝗵𝗲𝗻 𝘆𝗼𝘂 𝘄𝗿𝗼𝘁𝗲 𝘁𝗵𝗲 𝗲𝘀𝘁𝗶𝗺𝗮𝘁𝗲.
This is why the demo is so dangerous. It runs, and looks finished, and everyone relaxes. Then months disappear into the gap between "works in the demo" and "works in production." The team didn't slow down. They hit the part where the real work lived.
The damage isn't only the lost time but also the loss of optimism. When you tell stakeholders you're 90% done, they hear "𝗮𝗹𝗺𝗼𝘀𝘁 𝘀𝗵𝗶𝗽𝗽𝗲𝗱," and they plan around a date that was never real. The trust you lose when that date misses costs more than the miss itself.
So 𝘁𝗿𝗲𝗮𝘁 𝟵𝟬% 𝗱𝗼𝗻𝗲 𝗮𝘀 𝗵𝗮𝗹𝗳𝘄𝗮𝘆. Budget the finish as its own phase, with its own time and its own risk. The last 10% isn't where the project ends. It's where half the work was hiding the whole time.
Have you noticed this phenomenon in your projects?
𝗟𝗮𝘄𝘀 𝗼𝗳 𝗦𝗼𝗳𝘁𝘄𝗮𝗿𝗲 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗶𝘀 𝗻𝗼𝘄 𝗮𝗻 𝗮𝘂𝗱𝗶𝗼𝗯𝗼𝗼𝗸 🎧
A lot of people told me the same thing after the book came out: I want to read this, but I can't find time to sit down with it.
So I made the audiobook.
Laws of Software Engineering is now something you can listen to. On your commute, at the gym, or on a long walk. Six hours and nine minutes, all 63+ laws, all seven parts, narrated start to finish.
The laws don't change in audio form. Conway's Law still explains why your architecture mirrors your org chart. Brooks's Law still bites when you add people to a late project. Hyrum's Law can still make every API you ship problematic. You just take them in differently when someone walks you through them, one at a time, while you're out walking yourself.
The audiobook is DRM-free. You get one M4B with chapters, plus the MP3s if you want them. Download it once, and it's yours, on any device, for good.
There's a sample too, so listen first and decide for yourself.
🎧 𝗔𝘂𝗱𝗶𝗼𝗯𝗼𝗼𝗸: https://t.co/JZwxwryzyo
🔊 𝗦𝗮𝗺𝗽𝗹𝗲: https://t.co/YMRvdLAPY5
Prefer to read? You can do it in two ways:
📕 𝗘𝗯𝗼𝗼𝗸 (𝗣𝗗𝗙 + 𝗲𝗣𝘂𝗯), 20% off this week: https://t.co/dZGIgJELVf
📔 𝗣𝗮𝗽𝗲𝗿𝗯𝗮𝗰𝗸, 𝗛𝗮𝗿𝗱𝗰𝗼𝘃𝗲𝗿, 𝗼𝗿 𝗞𝗶𝗻𝗱𝗹𝗲 𝗼𝗻 𝗔𝗺𝗮𝘇𝗼𝗻: https://t.co/SzVJSmYyxo
What is interesting is that most readers chose to buy a hardcover.
If you've already read it, thank you. If you've been meaning to, now's a good time.
Why tasks tend to take up as much time as allocated
Between 1914 and 1928, the British Royal Navy shrank. Their capital ships dropped from 62 to 20, and the crews lost a third of their men. Yet the number of Admiralty officials administering it all grew by 𝟳𝟴%!
The fleet got smaller, but the bureaucracy running it grew. A naval historian named Cyril Northcote Parkinson noticed: 𝘄𝗼𝗿𝗸 𝗲𝘅𝗽𝗮𝗻𝗱𝘀 𝘁𝗼 𝗳𝗶𝗹𝗹 𝘁𝗵𝗲 𝘁𝗶𝗺𝗲 𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗹𝗲 𝗳𝗼𝗿 𝗶𝘁𝘀 𝗰𝗼𝗺𝗽𝗹𝗲𝘁𝗶𝗼𝗻.
The narrow version is the one that runs your sprint. Give a developer two weeks for a task that needs two days, and it takes two weeks. Not because they're lazy. The slack fills up with extra planning, a third refactor nobody asked for, and an afternoon spent arguing about a config format. The work quietly expands to match the time you gave it.
Meetings are one example, too. Book an hour, and the discussion will fill that hour. Book the same agenda for a 30-minute meeting, and somehow it still gets done. The container shapes the contents.
This is why loose deadlines cost you more than tight ones. A short, fixed 𝘁𝗶𝗺𝗲 𝗯𝗼𝘅 creates the necessary pressure focus. Agile teams use it on purpose: keep tasks small, put a hard stop before the sprint closes, and let the box do the disciplining. The constraint isn't cruelty, it's a forcing function.
But there's a floor, and this is where Parkinson meets Hofstadter. Squeeze the schedule to nothing, and you don't get speed; you get missed dates and a burned-out team. Hofstadter says the work takes longer than you think. Parkinson says 𝗶𝘁 𝘁𝗮𝗸𝗲𝘀 𝗮𝘀 𝗹𝗼𝗻𝗴 𝗮𝘀 𝘆𝗼𝘂 𝗮𝗹𝗹𝗼𝘄. The honest estimate lives in the narrow band between them.
Give work less room than it wants, but more than it strictly needs. That gap is where good engineering happens.
𝗧𝗵𝗲 𝟭𝟭-𝗟𝗶𝗻𝗲 𝗟𝗶𝗯𝗿𝗮𝗿𝘆 𝗧𝗵𝗮𝘁 𝗕𝗿𝗼𝗸𝗲 𝘁𝗵𝗲 𝗜𝗻𝘁𝗲𝗿𝗻𝗲𝘁
In March 2016, a developer named Azer Koçulu unpublished a tiny NPM package called left-pad. It padded strings on the left. 11 lines of code.
Within hours, builds across JavaScript started failing. Babel broke. React broke. Thousands of projects that had never heard of left-pad couldn't compile, because something deep in their dependency tree quietly relied on it.
One person walked away from a function nobody thought was important, and large parts of the internet stopped building.
This is the Bus Factor. The number of people who, if hit by a bus, would put your project in serious trouble.
A bus factor of 1 means one person holds the critical knowledge. A bus factor of 5 means you could lose any one of five specific people before the work stops. The metric is brutally simple, and it's almost always lower than people think.
You see it everywhere:
A startup has one engineer who understands the legacy billing system. They take a long vacation, and the team realizes nobody else can debug a single invoice issue.
A 50-engineer codebase has two or three people who actually know how the deployment pipeline works. The onboarding doc says "ask Maria."
The Linux kernel has thousands of contributors, but several subsystems are maintained by a single active maintainer. If they step away, that part of the kernel is in trouble until someone else learns it.
Open source projects measure their health partly by how many maintainers can drive things independently. A bus factor of 1 is a warning sign. The left-pad incident is what happens when you have hundreds of bus-factor-1 dependencies and one of them disappears.
Now stack the bus factor against the 𝗗𝗲𝗮𝗱 𝗦𝗲𝗮 𝗘𝗳𝗳𝗲𝗰𝘁. In bad organizations, the best engineers leave first because they have options. The ones who stay are often the ones who can't easily find work elsewhere. Talent evaporates, and mediocrity accumulates. Like the Dead Sea, where water escapes but salt remains.
Combine low bus factor with the Dead Sea Effect, and you get organizations where critical knowledge is held by people who are increasingly the wrong people to hold it. The institutional knowledge isn't institutional. It's locked inside a few heads, and the strongest of those heads are leaving first.
The fix is straightforward:
𝗣𝗮𝗶𝗿 𝗽𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 on critical systems. The second person doesn't have to write the code. They have to understand it.
𝗖𝗼𝗱𝗲 𝗿𝗲𝘃𝗶𝗲𝘄𝘀 that aren't rubber stamps. A real review forces the reviewer to learn the code well enough to push back.
𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 written for the engineer who joins next year, not the one who already knows. Runbooks for failure modes. ADRs for the why, not just the what.
𝗥𝗼𝘁𝗮𝘁𝗶𝗼𝗻𝘀. On-call is the one place most teams already do this. Extend the principle. Rotate ownership of subsystems, deployment, and incident response.
The honest test: pick a person. Could the team ship next quarter without them? If the answer is no, you don't have a star. You have a single point of failure, and the team is one resignation away from a left-pad of your own.
Pre mesec dana je izašla moja knjiga "Laws of Software Engineering" na engleskom. Postala je #1 bestseler na Amazonu. Predgovore su napisali Rebeka Parsons (bivša tehnička direktorka u Thoughtworks-u) i Edi Osmani (Direktor inženjeringa u Google-u).
Sada konačno dolazi i na srpski.
Na srpskom se zove "Zakoni softverskog inženjerstva", a izdaje je Kompjuter biblioteka iz Beograda. 63+ zakona i principa, u sedam celina, na oko 300 strana.
Konvejev, Bruksov, Gudhartov, Hajramov i mnogi drugi, zakoni koje iskusni inženjeri znaju iz prve ruke, najčešće zato što su se na njima jednom opekli.
U pretplati je sa 40% popusta (1.500 umesto 2.420 dinara): https://t.co/efnBZfiKmK
Ovo izdanje mi posebno znači.
Most engineers think writing better code is what builds a career
Then they watch someone slower, who is a worse coder, get promoted, and spend a year trying to figure out what they missed.
I started writing code in the early 2000s. The first decade I spent trying to type faster and cleaner code. Also, I tried to know the language in depth. Of course, none of that was a waste. Today, AI does most of it better than I ever did, anyway. The parts that actually compounded were somewhere else, and I was slow to notice.
𝗦𝗼 𝗜 𝘄𝗿𝗼𝘁𝗲 𝗱𝗼𝘄𝗻 𝘁𝗵𝗲 𝟭𝟯 𝗹𝗲𝘀𝘀𝗼𝗻𝘀 𝗜'𝗱 𝗵𝗮𝗻𝗱 𝘁𝗼 𝘆𝗲𝗮𝗿-𝗼𝗻𝗲 𝗺𝗲.
What made the list:
- Why the job is mostly debugging, and why that's the skill AI is worst at
- Code is a liability. Half your over-engineering disappears once you accept it
- Why solving the right problems is better than just closing tickets, and the question I ask myself to make sure I'm doing it
- Why is simple harder than complex
- Tests are a contract with future-you, not with QA
- Bring solutions, not just opinions, if you want to be invited back to the next decision
- Why code wins arguments more often than meetings do
- People are more important than the tech, and how to tell an ego argument from a real one
- Why is nobody managing your career except you, even if you have a great manager
👉 Read it here: https://t.co/g0bWoExB7W
--
This issue is brought to you by @ElevenLabs: https://t.co/11czgAWMZg
𝗪𝗵𝘆 𝗬𝗼𝘂𝗿 𝗕𝗲𝘀𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 𝗕𝗲𝗰𝗼𝗺𝗲𝘀 𝗬𝗼𝘂𝗿 𝗪𝗼𝗿𝘀𝘁 𝗠𝗮𝗻𝗮𝗴𝗲𝗿
Your senior engineer is the strongest on the team. They ship cleanly, mentor juniors, and design complex systems. The reward is a promotion to engineering manager.
Six months in, the team is struggling. One-on-ones get skipped. Planning is reactive. The engineer who used to ship the hardest features now spends their days in meetings about other people's features. They're not great at it.
The company didn't gain a manager. It lost an engineer.
This is the Peter Principle:
"In a hierarchy, every employee tends to rise to their level of incompetence."
The mechanism is simple. Promotions reward performance in your current role. They don't test whether you'll be good at the next one. You keep getting promoted as long as you succeed. The day you stop succeeding, the promotions stop. You stay there.
Scaled up, you get an organization where most senior roles are held by people who have hit their ceiling and stopped moving.
The pattern has a specific shape in software. The skills that make someone a great engineer (deep focus, deterministic problem-solving, clean execution) are not the skills that make someone a great manager (context-switching, ambiguity tolerance, conversations, soft-skills). Being world-class at one tells you nothing about the other.
The dysfunction this creates in tech orgs:
The promotion path runs through management. Engineers who want raises, scope, or recognition have to take jobs they don't want and may not be good at.
Companies confuse seniority with leadership. The best programmer becomes the tech lead by default, even when nobody (including them) thinks it's a good fit.
Bad managers are rarely demoted. The Peter Principle's grim corollary: once someone reaches their level of incompetence, they tend to stay there. Demotion feels like punishment, even when both sides would benefit.
The fix is structural, not individual. Three patterns that work:
𝗗𝘂𝗮𝗹 𝗰𝗮𝗿𝗲𝗲𝗿 𝘁𝗿𝗮𝗰𝗸𝘀. Engineers advance to staff, principal, or distinguished without ever managing people. The IC track gets the same titles, compensation, and respect as the management track. Most large tech companies do this now. Many smaller ones still don't.
𝗧𝗿𝘆-𝗯𝗲𝗳𝗼𝗿𝗲-𝘆𝗼𝘂-𝗽𝗿𝗼𝗺𝗼𝘁𝗲. Move the engineer into the role on a trial basis. Six months as acting manager. If it works for both sides, make it permanent. If not, return to engineering with no penalty.
𝗧𝗿𝗲𝗮𝘁 𝗺𝗮𝗻𝗮𝗴𝗲𝗺𝗲𝗻𝘁 𝗮𝘀 𝗮 𝘀𝗸𝗶𝗹𝗹, 𝗻𝗼𝘁 𝗮 𝗿𝗲𝘄𝗮𝗿𝗱. Train new managers. Coach struggling ones. Stop using management as the prize for performance in a different job.
The Peter Principle isn't a knock on the people who get promoted. They didn't ask for the trap. The fix is on the organization that built the trap.
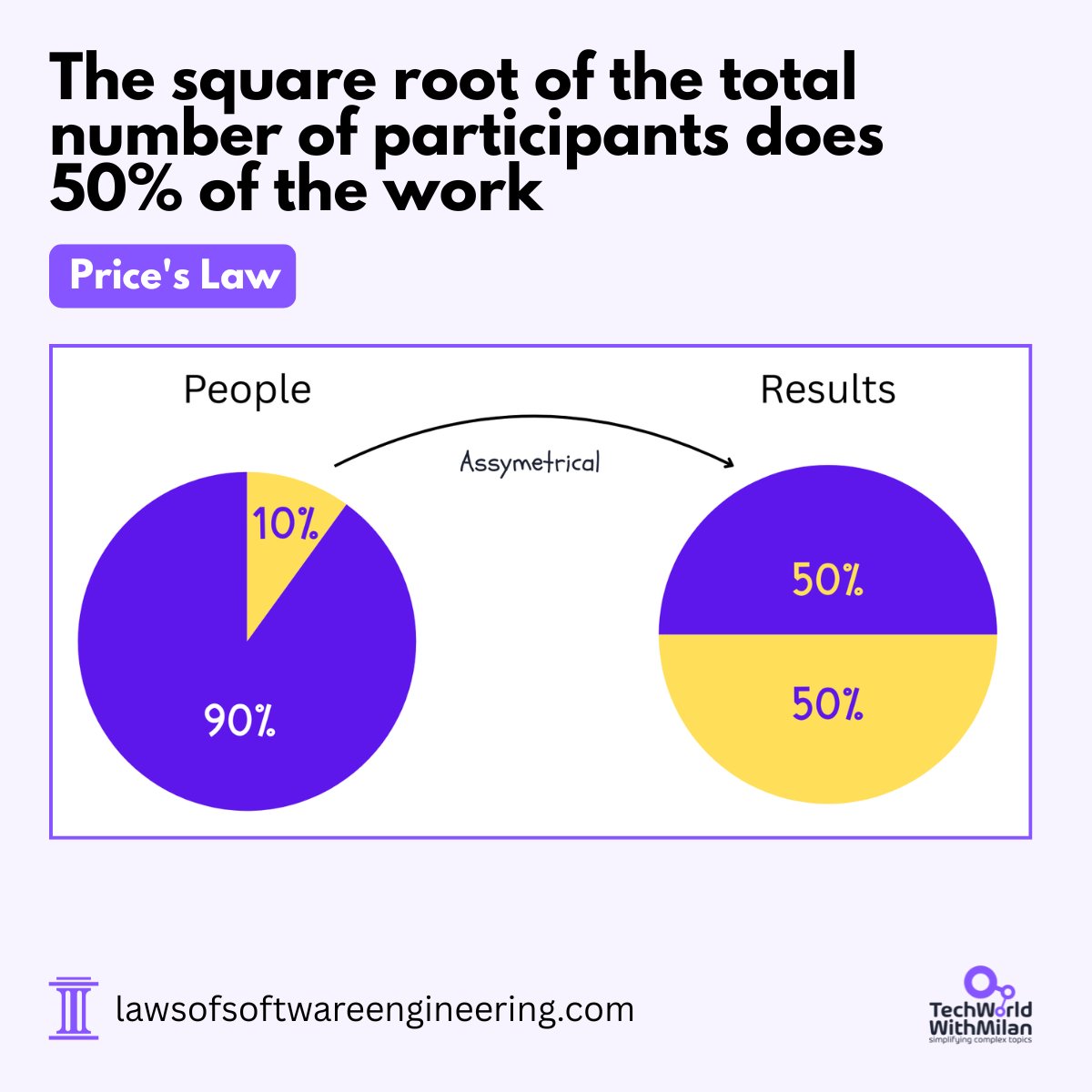
𝗪𝗵𝘆 𝗛𝗮𝗹𝗳 𝗬𝗼𝘂𝗿 𝗧𝗲𝗮𝗺'𝘀 𝗢𝘂𝘁𝗽𝘂𝘁 𝗖𝗼𝗺𝗲𝘀 𝗙𝗿𝗼𝗺 𝗮 𝗛𝗮𝗻𝗱𝗳𝘂𝗹 𝗼𝗳 𝗣𝗲𝗼𝗽𝗹𝗲
In an engineering org of 100 people, about 10 of them produce half the output. Of 400, it's 20. Of 10,000, it's 100.
This is Price's Law:
"The square root of the number of people in a group does 50% of the work."
Derek de Solla Price observed it in scientific publishing in the 1960s. The most prolific authors weren't a bit more productive than average. They were dramatically more, and the gap widened as the group grew.
In software, you can see it too:
A GitHub project with 30 contributors. About 5 of them (√30 ≈ 5) wrote half the meaningful code. The rest shipped patches, docs, and one-time fixes.
A product team of 16. Four engineers consistently solve the hardest problems and shape the architecture. The others handle maintenance, smaller features, and the day-to-day.
The most public test of this law was on Twitter in late 2022. About 7,500 employees. Price's Law would predict a core of around 87. Musk took over, cut staff roughly in half, and the platform kept running. The basic functions are held.
But the law only predicts who produces visible output. It says nothing about resilience. Twitter cut redundancy in SRE, security, and content moderation. Some laid-off engineers were asked to come back. Critical skills had been cut. Output continued. The buffer underneath it was gone.
This is the part most people get wrong. Price's Law is not a layoff plan, nor is it an argument that most of your team is dead weight. The 87 produces visible output. The 7,413 hold the system up.
What the law actually says:
Adding people doesn't double output. The math doesn't work that way. Going from 100 engineers to 400 doesn't move the core from 10 to 40. It moves it from 10 to 20.
If your top contributors leave, you lose more than the headcount suggests. Replacing one of the √N takes longer and costs more than replacing an average hire.
Hiring quality matters more than hiring quantity. One excellent engineer outperforming three average ones is normal. Engineering throughput tracks hiring bar more than headcount.
Retention of the core √N is strategic, not HR. They burn out the same as everyone else, often faster, because they take on the hardest work. Losing one of them is a much bigger event than it looks on paper.
The real implication of Price's Law isn't who matters. Its output is wildly uneven, and the org chart almost never reflects this. Knowing where the work actually comes from is the first step to not losing it by accident.
Every senior engineer learned these the hard way. Conway's Law. Brooks's Law. Hyrum's Law. 63+ principles that shape every system, team, and decision. One book, so you don't pay the same tuition.
Do we all need to go through the same problems?
After 20 years in the industry, I saw that we learn from the same mistakes again and again
When a team adds people to a late project, the project ships later. Someone optimizes code nobody runs. An abstraction holds until the first weird input, then it leaks. An API ships some accidental behavior on a Tuesday, and then three other teams depend on it.
We keep learning this stuff the same way. Usually, those are production issues or failed launches. Sometimes, when good engineers leave us. None of it is cheap.
So I decided to write it all down. On 300 pages, 63+ laws, seven parts covering architecture, teams, estimation, quality, scale, design, and decision-making. Each one has its origin, the real systems where it showed up, and the other laws it fights with or backs up.
Forewords by Rebecca Parsons and Addy Osmani. Twenty engineers, architects, and managers reviewed my drafts before they shipped.
The poster below shows the main 56 of them. If you've been doing this for a while, most of it will look familiar. That's the point.
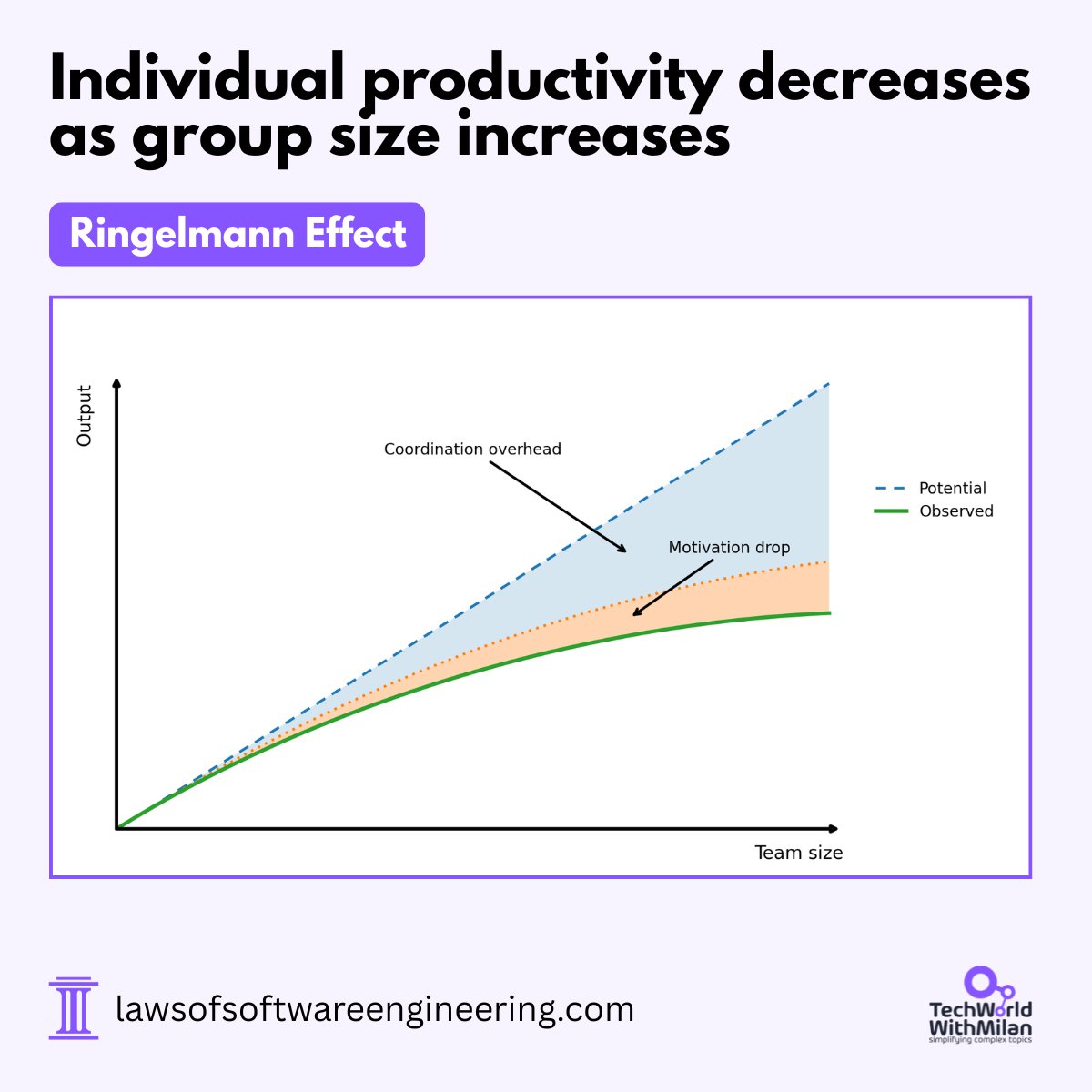
𝗧𝗵𝗲 𝗛𝗶𝗱𝗱𝗲𝗻 𝗖𝗼𝘀𝘁 𝗼𝗳 𝗔𝗱𝗱𝗶𝗻𝗴 𝗣𝗲𝗼𝗽𝗹𝗲 𝘁𝗼 𝗬𝗼𝘂𝗿 𝗧𝗲𝗮𝗺
Researchers studied thousands of open-source projects on GitHub to examine how individual productivity changes as teams grow.
The numbers are interesting:
𝟮-𝟱 𝗽𝗲𝗼𝗽𝗹𝗲: 1,850 lines of code per developer per month
𝟭𝟬 𝗽𝗲𝗼𝗽𝗹𝗲: 1,200 lines per developer (a 35% drop)
𝟱𝟬+ 𝗽𝗲𝗼𝗽𝗹𝗲: 450 lines per developer (a 75% drop)
This is the Ringelmann Effect. In the 1880s, a French engineer, Max Ringelmann, had people pull on a rope and measured how hard each person actually pulled.
One person pulling alone gave 100% effort. Two gave about 93% each. Eight gave around 50%. The total force kept growing. Per-person effort kept dropping. Each added body did less than the one before.
The same thing happens in software teams.
The mechanism has two parts.
First, 𝘀𝗼𝗰𝗶𝗮𝗹 𝗹𝗼𝗮𝗳𝗶𝗻𝗴. In a meeting of 3, you speak. In a meeting of 20, you assume someone else will. Same thing in code: when 10 engineers share a feature, some quietly assume someone else has the tricky parts.
Second, 𝗰𝗼𝗼𝗿𝗱𝗶𝗻𝗮𝘁𝗶𝗼𝗻 𝗼𝘃𝗲𝗿𝗵𝗲𝗮𝗱. The number of relationships in a team of N people is N(N-1)/2. A team of 4 has 6 relationships. A team of 6 has 15. A team of 10 has 45. Each new hire adds N more channels for code reviews, merge conflicts, discussions, and meetings. None of those ship's features.
This is why Amazon creates teams at a size that two pizzas can feed (5-8 people). It's why open-source projects with thousands of contributors split themselves into small subsystem teams instead of a single massive committee.
The fix isn't to make large teams more efficient. Past a point, you can't. The fix is to stop building large teams.
Cap core teams at 9. Split when you cross 15. Use modular architectures so coordination stays local, not global. Make individual contributions visible so loafing has nowhere to hide.
Adding the 10th engineer probably won't speed up your team. It will just make the other 10 a little slower.