Large multimodal models often lack precise low-level perception needed for high-level reasoning, even with simple vector graphics. We bridge this gap by proposing an intermediate symbolic representation that leverages LLMs for text-based reasoning. https://t.co/LsytaswF5i 🧵1/4
Why do neural nets generalize so well?🤔
There's a ton of work on SGD, flat minima, ... but the root cause is that their inductive biases somehow match properties of real-world data.🌎 We've examined these inductive biases in *untrained* networks.🎲
https://t.co/Co65qSJQES ⬇️
And today is T - 2 weeks for my other @NVIDIA#GTC session - a fireside chat with @ChrSzegedy, cofounder of @xAI. Christian is one of the seminal research figures in the Deep Learning community, but the main focus of our chat will be on something that he has been working very hard on over the past seven years: automated reasoning. This also happens to be perhaps the hottest topic in the current wave of applied AI research and application.
Again, I know that most of you will not be able to attend this event in person (but I do encourage as many of you to watch it online), and I would like to give you all an opportunity to ask some questions which I may weave into our discussion.
Link to the session in the GTC catalog: https://t.co/nQi7HMMZGO
#GTC24 #GTC2024 #ArtificialInteligence #AI #DeepLearnign #DL #ML #GenerativeAI #GenAI @NVIDIAAIDev@NVIDIAAI@NVIDIAGTC
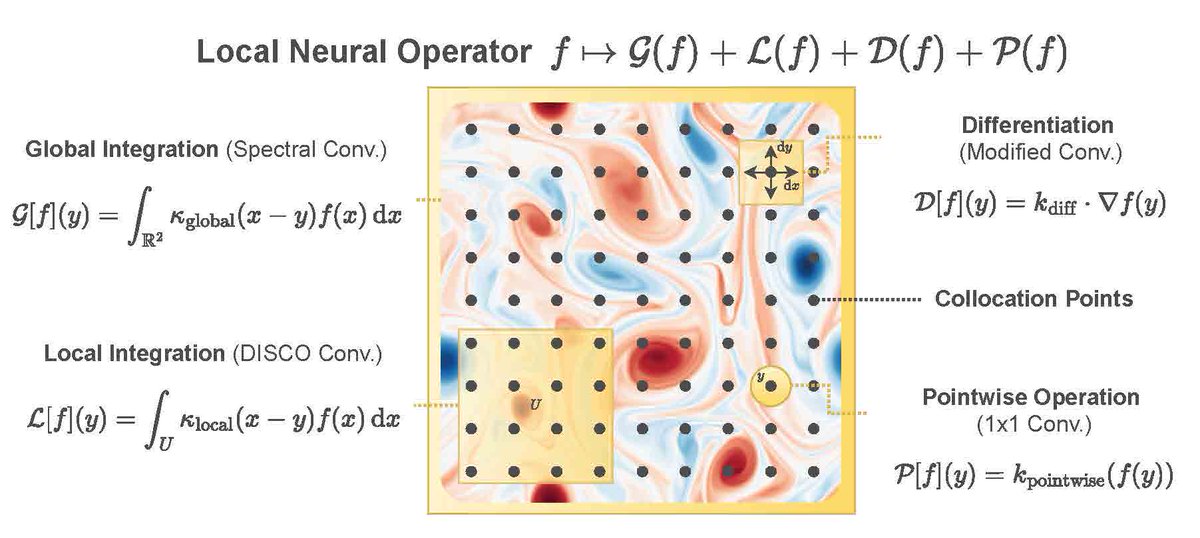
How do we capture local features across multiple resolutions? While standard convolutional layers work only on a fixed input-resolution, we design local neural operators that learn integral and differential kernels, and are principled ways to extend standard convolutions to varying resolutions and grids.
Layers of such local neural operators can be combined with global neural operators such as Fourier neural operators (FNO) to provide rich expressive architectures for learning PDEs.
We show improved performance on many PDEs such as Darcy flow, turbulent fluid flow and spherical shallow water equations.
https://t.co/bkJ2QhFcvR
@julberner@Azizzadenesheli
Me: Can you draw a very normal image?
ChatGPT: Here is a very normal image depicting a tranquil suburban street scene during the daytime.
Me: Not bad, but can you go more normal than that?
(cont.)
Inception used 1.5X less compute than AlexNet and 12X less than VGG, outperforming both. The trend continued with mobile net... etc.
IMO, today's LLMs are insanely inefficient/compute. Regulations that impose limits on the amount of compute spent on AI training will just accelerate the trend of making them much more efficient, by letting large labs refocusing their efforts.
Regulation starts at roughly two orders of magnitude larger than a ~70B Transformer trained on 2T tokens -- which is ~5e24.
Note: increasing the size of the dataset OR the size of the transformer increases training flops.
The (rumored) size of GPT-4 is regulated.