Two new paper implementations just dropped on TensorTonic.
Word2Vec: subsampling, skip-gram pairs, negative sampling, SGNS loss, CBOW forward, and a full SGD training step. The paper that started the whole embeddings revolution, built from scratch.
DenseNet: channel growth, composite layers, bottleneck layers, dense blocks with full feature map concatenation, transition layers, and the complete forward pass. The architecture that proved you don’t need to choose between depth and parameter efficiency.
https://t.co/jni5KcSizC
GLM-4.5 is now on TensorTonic.
10+ problems covering partial RoPE, QK-Norm, group-restricted MoE routing, shared experts, multi-token prediction, and the full forward pass.
Implement it from scratch in PyTorch.
https://t.co/34Uklh4LH1
OpenAI’s first open-weight language model since GPT-2 and you can now implement it from scratch on TensorTonic.
9 problems in pytorch covering attention sinks, YaRN RoPE, sliding window, GQA, MXFP4 quantization, MoE routing, and the full forward pass .
https://t.co/34Uklh4LH1
We're hiring for -
- AI engineering intern
- GTM/Growth intern
Remote. Growing at insane speed. 40K users. High agency.
If you're cracked and want to work at early stage startup, then consider applying. More details below 👇
Computer vision lovers, you need to see this.
We just shipped CV puzzles on TensorTonic covering everything from image operation basics and convolutions to pooling, losses, augmentation, and modern architectures all the way up to Vision Transformers.
Implement the full CV stack from scratch in Numpy and PyTorch.
https://t.co/jni5KcSizC
Every ML framework eventually bottlenecks on GPU performance and when it does, the engineers who understand CUDA are the ones who fix it. Flash attention, fused kernels, custom triton ops, all of it starts with writing raw CUDA.
We just released 35 CUDA puzzles on TensorTonic, completely free.
Kernel foundations like vector ops and activations, matrix operations, tiled matrix multiplication, memory coalescing, shared memory, and reduction patterns. Write real CUDA C++ kernels and run them against tests on real GPU hardware.
https://t.co/jni5KcSizC
Part 2/30 of the LLM Series: RoPE (Rotary Position Embedding)
How does a transformer know the difference between -
"the dog bit the man" and "the man bit the dog"?
The words are almost identical, but the meaning changes completely.
RoPE encodes position as rotation, allowing transformers to understand relative order through geometry.
Read more:
https://t.co/HIKKvvjA8Q
We're starting a new series of LLM internals which will be interactive, cool visualizations into the techniques behind modern LLMs: attention variants, Flashattention, LoRA, RLHF, quantization and more.
We just released our first concept: KV caching in LLMs.
Go check out: https://t.co/XGurpCueCr
While its good to implement GPT2, LLaMA, DeepSeek but you should be able to implement classic ML algorithms as well such as linear regression, KNN, decision trees, random forests, PCA, K-means, Naive Bayes, and ridge regression from scratch.
These are the algorithms that show up in every single ML interview.
We shipped a full Classic ML track on TensorTonic with interactive visualizations where you can actually see your linear regression fitting in real time, watch KNN voting with draggable test points, and visualize PCA finding the direction of maximum spread. You implement the math, we show you what it looks like.
Code your first problem - https://t.co/jni5KcSizC
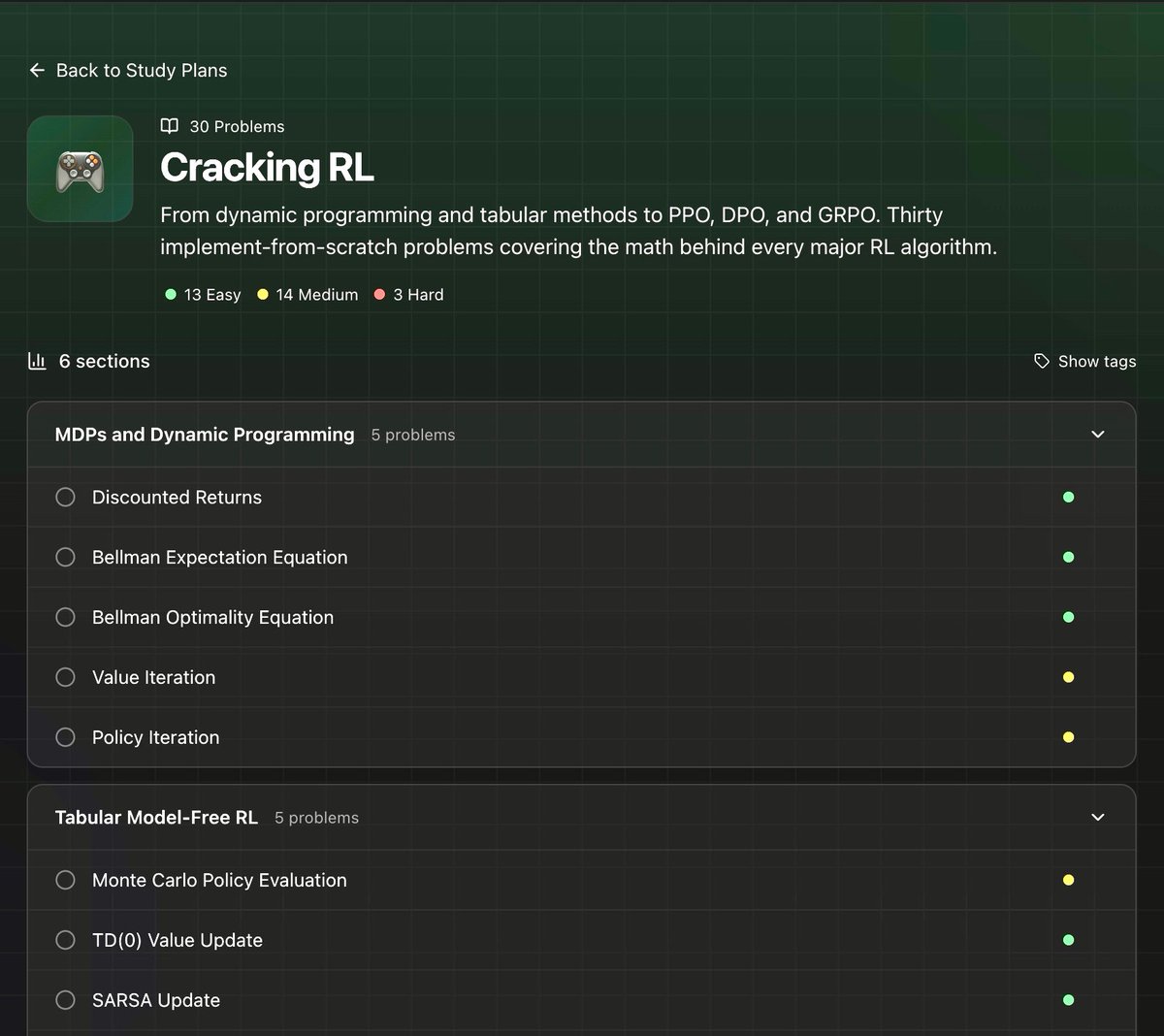
GRPO, DPO, PPO, RLHF are the algorithms behind every major LLM alignment pipeline and if you really want to understand how a base model becomes ChatGPT, you need to implement them yourself.
We just shipped a full RL track on TensorTonic covering all of it.
RLHF with KL penalties, DPO, GRPO, RLOO, PPO clipped surrogate, Actor-Critic, REINFORCE, GAE, all the way down to the fundamentals like DQN variants, Q-Learning, SARSA, Monte Carlo methods, and multi-armed bandits.
https://t.co/jni5KcSizC
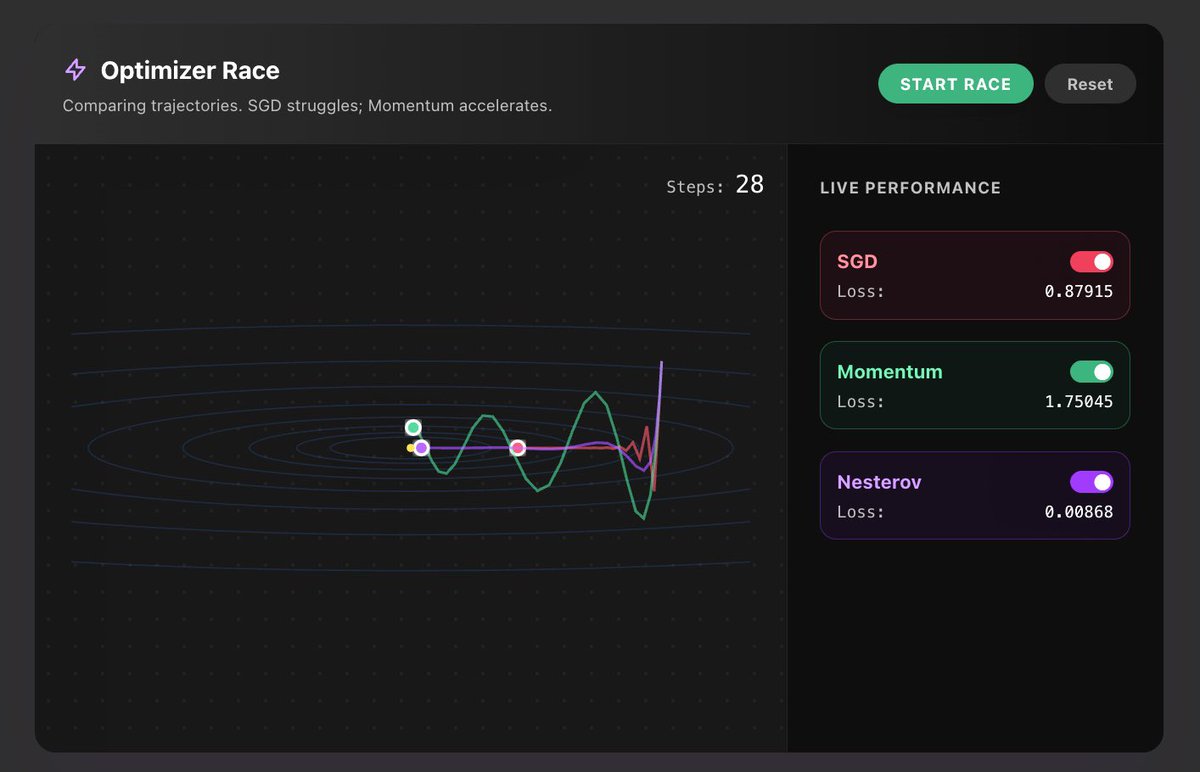
Every ML framework hides optimizers behind one line of code and nobody questions what’s actually happening when you call optimizer.step().
We have coding questions where you implement every optimization algorithm from scratch, starting from vanilla gradient descent all the way to AdamW.
SGD, momentum, Nesterov, Adagrad, RMSprop, Adam, and AdamW, each one building on the last so you actually understand why Adam exists and what the W in AdamW fixes.
https://t.co/jni5KcSizC
New updates -
🚨 You can now bookmark any problem to revisit later
⚡️ More light themes on code editor
🔥 You can now share your profile URL with recruiters
🥳 Badges are now shareable on social media
📱 Cleaner experience on mobile across problems
https://t.co/34Uklh4LH1
NumPy is the backbone of every ML pipeline. Linear algebra for neural networks, matrix decompositions for PCA, vectorized gradient for backprop, feature engineering on tabular data.
We've released 25 problems on array creation, slicing, indexing, broadcasting across mismatched dimensions, and replacing slow Python loops with vectorized ops. The stuff that separates people who use NumPy from people who actually think in NumPy.
https://t.co/jni5KcSizC
Stop reading. Start building
@TensorTonic is pure fire 🔥
Built for developers who prefer writing real code over just reading theory.
Practical. Focused. Implementation-first
Code > Theory: https://t.co/NyEq7VFx5N
#AI#MachineLearning#DeepLearning#Python#LearnByBuilding