The new feature is implemented. Changes are being deployed to production. All of a sudden, Slack is full of Sentry errors from clients. Code red!
You dig into it and soon realize that the errors are due to the price attribute being missing from the response. Whoops! You’ve introduced an unintentional breaking change. Price is now cost, but clients still expect price. Let’s revert and fix!
With all the AI tooling, this is becoming more expressed than ever. Added required request attributes, changed response type from str to str | None. We should catch such changes early in the process, not only when client errors start flying around.
For FastAPI apps, that’s easy to do. FastAPI generates an OpenAPI schema out of the box. We can compare the schema from the PR with the schema from the main branch and detect breaking changes during the testing step in CI/CD pipelines.
Read the full post to learn how to easily do that for FastAPI apps with oasdiff and GitHub Actions:
https://t.co/A5ahJhIp48
Best cache is no cache. Way too often, I see cache as the answer to your performance problems. Slow API responses due to slow queries? Just put Redis in front of the database.
Cache always comes with a price. You need to create it, maintain it, and, worst of all, invalidate it at some point.
So before you start running into Redis’s or CloudFront’s lap - check whether you really:
- pushed everything from your database with indexing, partitioning, and repacking,
- have optimized queries that are using index-only scans,
- need to store that much data
- need to access all that data
- need to access data so frequently
If there’s no other way, go for the cache. But often the problem lies elsewhere, and solving it means you don’t need to deal with the cache and its invalidation.
Stick to simplicity!
Rewriting Python code with Rust seems easy. Especially with AI. But the devil is always in details.
To confidently rewrite Python code to Rust with AI, you should follow these four steps 🧵
The AI ponzi scheme goes like this:
Everyone is generating all these long ass docs and then passing them off for others to read
Then the person receiving is like, wtf this is way too long, and hands that into an AI to read and summarize
Then they are generating a long ass response back
and this cycle goes like that forever. and we call this work now 😅
The token lords watch this from their towers nodding and grinning.
Most engineers change teams way too often.
If you chop and change a lot you never learn how to build a codebase that can be supported. You never see the consequences of the choices you made.
Growth comes from breadth and depth.
Google 把内部工程师的代码审查(Code Review)规范公开啦
这几乎是目前业界最顶级的标准
很多程序员只会写代码,但不知道怎么审代码,可以看看 Google 是怎么做的
1.双向指南:不仅教审查者怎么挑毛病,还教作者怎么写出容易通过的代码
2.术语科普:解释了 Google 内部常用的 LGTM(看起来不错)和 CL(变更列表)到底意味着什么
3.实战价值:这套规范不是理论,而是 Google 每一位工程师都在用的实际操作准则
如果你想提升团队的代码质量,或者想知道顶级大厂的开发门槛,这份文档必读!
https://t.co/OdaozRkMYn
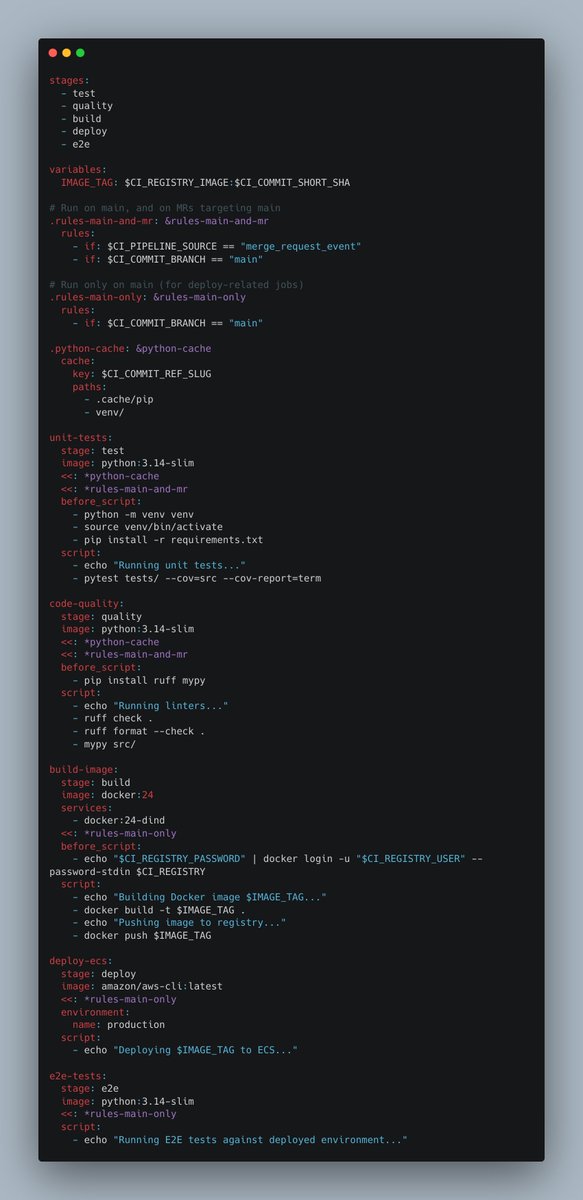
The first thing I do on every project is setting up CI/CD with code quality, tests, deployment and e2e tests.
This way, you eliminate “works on my machine” situations and set up things for success and calm Friday deployments.
Check the course below👇
Are you a #python package maintainer and looking for funding? Read the Docs allows you to collect funds via EthicalAds. And now if you'd like, you can route that directly to the #Django Software Foundation
https://t.co/mUh1amp8Bl
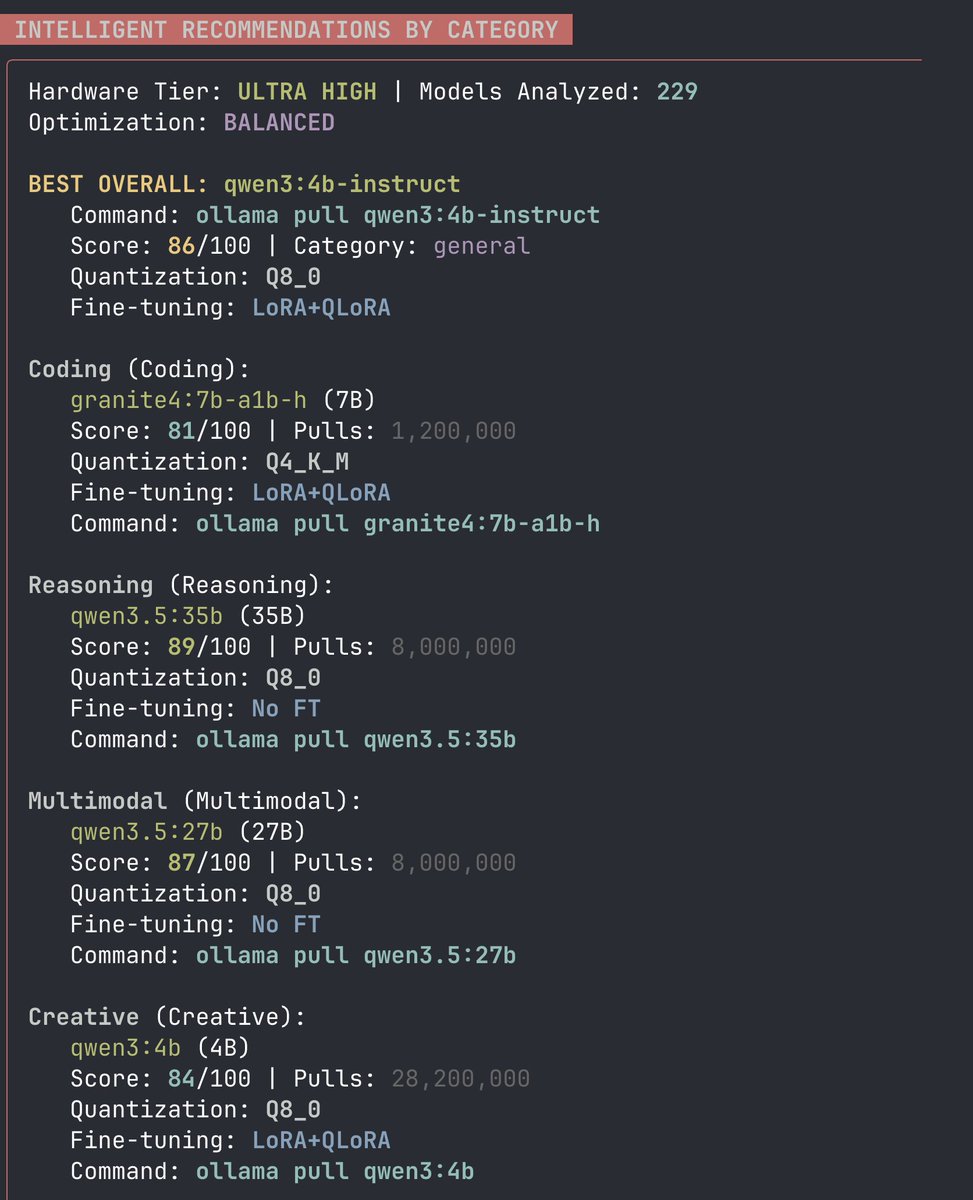
Really cool way to find out which models you can run on your computer:
1. Install llm-checker
$ npm install -g llm-checker
2. Detect your hardware
$ llm-checker hw-detect
3. Get a recommendation
$ llm-checker recommend --category coding
Here are some of the recommendations I got:
7 Python tips that will level up your code 🐍
1. Use f-strings instead of .format() or % for string formatting - cleaner and faster
2. List comprehensions are more Pythonic than for loops for creating lists
3. Use enumerate() instead of range(len()) when you need both index and value
4. Context managers (with statements) automatically handle resource cleanup
5. Default dict values with .get() to avoid KeyError exceptions
6. Use pathlib instead of os.path for file operations - more readable and cross-platform
7. Generator expressions save memory for large datasets compared to list comprehensions
Which tip do you use most often?
“Celebrated are the minimal dependencies, the humble function that just quietly does the job, the code that doesn't need to be touched for years because it was done right once.” https://t.co/EmT4KleCx2