🌶️Hot take; #ChatGPT and the likes are the death of nocode/lowcode products ; if you can actually get some code samples to do API calls and connectors why use #NoCode ?
If you need more you need to code anyway.
The 𝐅𝐓𝐈 (𝐟𝐞𝐚𝐭𝐮𝐫𝐞, 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠, 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞) architecture.
A mental map to build ML Systems and not get lost in the process ...
#MachineLearning#MLOps#DataScience
Training ML models is easy.
Transforming the data these models need is the hard part... until you learn this ↓↓↓
𝗧𝗵𝗲 𝗽𝗿𝗼𝗯𝗹𝗲𝗺
Building a real-world ML system is
> 𝟭𝟬% about training and deploying ML models,
and
> 𝟵𝟬% about transforming the data these models needs to work.
And the thing is, 𝗻𝗼𝘁 all data transformations are the same.
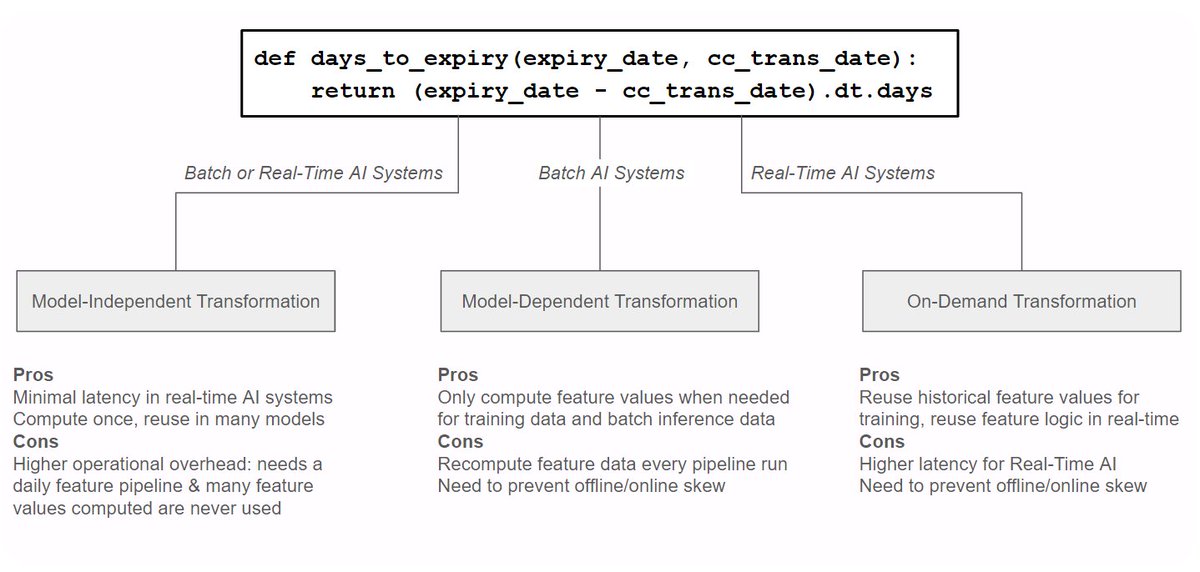
𝗧𝗵𝗲 𝘁𝗮���𝗼𝗻𝗼𝗺𝘆 𝗳𝗼𝗿 𝗗𝗮𝘁𝗮 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻𝘀
In every ML system we can have up to 3 different types of data transformations
1️⃣ 𝗠𝗼𝗱𝗲𝗹-𝗜𝗻𝗱𝗲𝗽𝗲𝗻𝗱𝗲𝗻𝘁 Transformations, for example rolling averages.
> Reusable across models
> Stored in the feature store
2️⃣ 𝗠𝗼𝗱𝗲𝗹-𝗗𝗲𝗽𝗲𝗻𝗱𝗲𝗻𝘁 Transformations, for example feature normalization
> Specific to one model
> Applied in both training and inference
3️⃣ 𝗢𝗻-𝗗𝗲𝗺𝗮𝗻𝗱 Transformations
> Require real-time data
> Used in online inference
Once you understand how and 𝗪𝗛𝗘𝗥𝗘 your data transformation happens, you are in a good position to start building ML software that works.
If you want to learn more about the taxonomy of data transformations read this excellent blog post by the great @jim_dowling
> 🔗 https://t.co/q7gTBCbxag
----
Hi there! It's Pau Labarta Bajo 👋
Every day I share free, hands-on content, on production-grade ML, to help you build real-world ML products.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 so you don't miss what's coming next
Why is building AI systems hard?
Because even with the simplest feature that you can imagine, you need to consider where it will be computed based on whether it's a batch AI system or a real-time AI system.
Luckily, there are some principles to guide you.
A thread 🧵👇
From our SIGMOD'24 paper, an easier read on the work we have done and are doing on making #rondb the database for real-time AI applications. If you thought #redis is good enough for real-time AI, please read this and tell us if we have changed your mind. https://t.co/YCClK5lKIi
Mediocre data access and painful queries = wasting time and money.
It may not be a matter of survival, but it might be a matter of competitive advantage; AI lakehouses have a native Python support. #AI#Lakehouse
If you're relying on traditional lakehouses for AI, you’re behind before yo even started.
This article discusses the move to AI lakehouses with a Python-native query engine, giving Python the respect it deserves; it just makes AI systems work.
Read on: https://t.co/BbZgcfPzJJ
The trick they employ is to force Python clients to use clunky JDBC/ODBC interfaces.
The result? Slow, inefficient data handling. A native query engine bypasses this mess, delivering data at lightning speed. #AI#Performance
Did you know that you can generate and manage your training data right from the Hopsworks UI? @TheMagicLex show how you can simplify your data workflow and enhance traceability with just a few clicks. 🔄
https://t.co/RVZRxqG3k6
A tool that helps enforcing best practices is a good tool. A tool that needs you to enforce best practices upon it is a waste of time.
Feature stores are built for purpose, not sort of stuck together in hope of nothing breaking. It’s about effient and good practices. #AI#MLOps
Ever been in a room when someone said "Our Data Warehouse will do" only to rebuild your AI system few months later?
Let's be honest, feature stores have always been the missing piece you knew you needed, but hoped the warehouse would sort of fit: https://t.co/2KpDlIQePT
Data marts can't keep up with modern AI. Its just not made for it.
For example; feature stores offer support for creating solid point-in-time correct training data. Unless, of course your AI systems do not need training ¯\_(ツ)_/¯ ? #AI#TrainingData
You want pushdown LEFT JOIN. You just didnt know it.
#RonDB does it. and it dramatically reduces latency and increases throughput for queries. This means faster, more efficient data retrieval—critical for high-performance AI and real-time use cases. #AI#Performance
Your AI models are underperforming. Why? Outdated data schemas.
The article explains the shift from star schema to snowflake schema for feature stores, increasing feature richness and performance. Lowering failure.
Get slightly more enlightened: https://t.co/46dJlmxKjY
TLDR;
Sstar schema is OK... for small-scale systems. It will break down at scale.
Snowflake schema scales better and handles complex queries more efficiently. It’s maybe time to upgrade if you want your AI to keep up with the demands of real-time data. #AI#Scalability