Owner @TheWriteCure | Content Marketing Manager @TigerDatabase | Tech Marketing Copywriter | I help tech startups create more value through the right words.
Why do Postgres servers fall victim to OOM-killers despite having seemingly sound configurations?
At Swiss PGDay on June 25, @TigerDatabase platform engineers @hintbits and Dimitris will share an intensive exploration of the failure path. They'll examine the complexities of Linux overcommit, cgroups, and Postgres memory architecture to understand why the kernel issues a SIGKILL. ⚡
The session will also highlight how eBPF was utilized for troubleshooting and how combining Patroni hooks with Postgres extensions can create a dependable memory ceiling.
This deep dive offers a debugging experience that provides profound insights into both Linux and #Postgres operations.
Link below.
Learn how Claude Code Agent Teams build and validate a Unified Namespace across Modbus, OPC UA, and MQTT using TimescaleDB and AI-driven governance.
#claudecodeaiagent#unifiednamespace...Show more
Learn why giving PostgreSQL more memory can sometimes make your application slower, and how to fix the hidden system conflict causing performance issues: https://t.co/sk839krEs1
"What AI industrializes isn't bad content — it's plausible mediocrity: grammatically correct, structurally coherent, superficially persuasive, competently formatted, and almost indistinguishable from average," @DavidSmooke
Read the full story: https://t.co/EZTiPsjZii
Postgres has expanded far beyond a traditional relational database thanks to its ecosystem of extensions.
This article explores how those capabilities are being used to simplify parts of modern data architecture: https://t.co/xTtSyErlqL
Discover how a reliable MQTT pipeline helped an explosives manufacturer save their production numbers, turning failing sensor data into real-time machine learning insights: https://t.co/MUccZGH1lW
Here's how one PostgreSQL extension quietly eliminates ingest bottlenecks, slashes query times, and cuts IIoT storage costs by up to 90%
https://t.co/sYoClCaehy
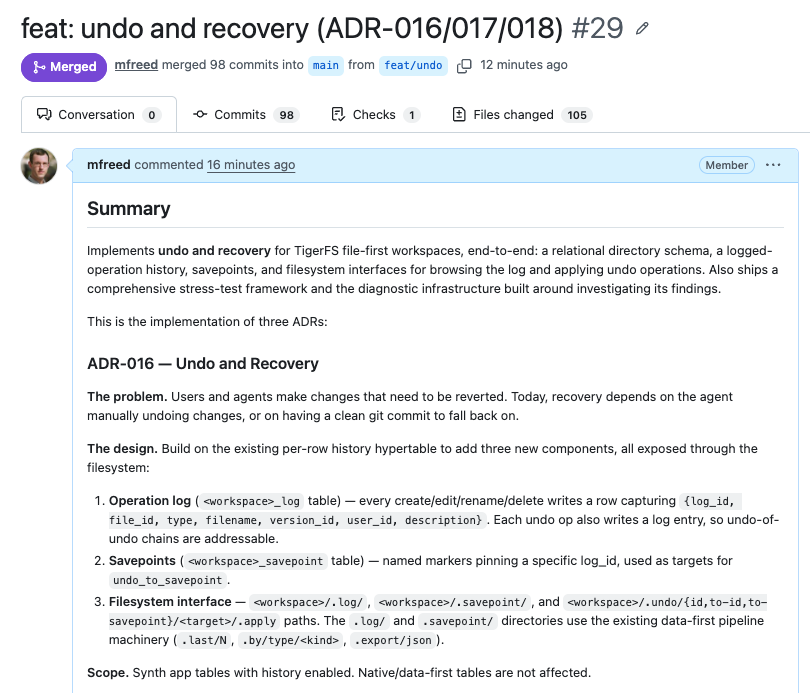
Getting close to TigerFS v0.7: Undo and recovery.
Implements undo and recovery for TigerFS file-first workspaces, end-to-end: a relational directory schema, a logged-operation history, savepoints, and filesystem interfaces for browsing the log and applying undo operations.
Every create/edit/rename/delete writes a row to a per-workspace operation log; named savepoints pin specific log_ids. Undo is exposed as filesystem writes to .undo/id/<log_id>/.apply or .undo/to-savepoint/<name>/.apply. Each undo also logs an entry, so undo-of-undo is also addressed.
Also ships a comprehensive stress-test framework and the diagnostic infrastructure built around investigating its findings.
Learn how to transform raw sensor data into an AI-ready Unified Namespace by unifying time-series and equipment context within a single PostgreSQL instance: https://t.co/TnRtLPSj8b
Two big announcements today kicking off @hannover_messe, but one story:
The industrial historian is being modernized. Legacy products are stuck in 1990s technology, and industrial orgs need to do far more with their operational data: more data, faster decisions, and now AI.
Today we announced @TimescaleDB Enterprise: commercial packaging of our Postgres-based time-series database -- HA, backups, monitoring, admin console, optional cloud sync -- for on-prem and edge.
We also unveiled a strategic alliance with @InductiveAuto. End-to-end: Ignition at the edge and plant → TimescaleDB Enterprise at each site → Tiger Cloud across the enterprise.
Physical AI will run on factories, grids, and fleets, and it needs an open, SQL-native time-series foundation from sensor to cloud.
That's the foundation we already power across 1000s of companies.
🏭🏗️⛏️🛢️⚡🚚⚙️🦾
Why do MQTT pipelines break at scale?
This guide shows the bottlenecks—and a simple batching fix that handles thousands of messages per second: https://t.co/vvgqFqXLsM
pg_textsearch v1.0 is now GA, on @TigerDatabase Cloud and open source.
A full BM25 search engine -- tokenization, indexing, compression, and query execution -- built in C directly inside Postgres. No sidecar or separate system.
Indexes live in Postgres pages, use the buffer cache, and participate in WAL, replication, and backups. Block-Max WAND for fast top-k, SIMD-accelerated posting lists, and parallel builds (138M docs in <18 min).
On MS-MARCO: 2.4–6.5x faster than ParadeDB/Tantivy (2–4 terms), with 8.7x higher concurrent throughput.
Full architecture and benchmarks:
https://t.co/OsKwVgtydL
Two things that make Tiger Cloud a better place to build with Postgres:
1. pg_textsearch now uses Block MAX-WAND for ranked search, with 40%+ smaller indexes. Competitive with the fastest Postgres search solutions.
2. Postgres 18 is the default. Async I/O, skip-scan, parallel GIN builds, uuidv7().
More: https://t.co/5eUULn0Lsb
Start a free trial: https://t.co/JMbEvJg5oo
MVCC is one of the best things about Postgres. It's also costing you more than you think if your rows never change after insert.
Every row in Postgres carries a fixed 23-byte header, plus padding, that tracks who created it, who deleted it, and whether the transaction committed. That machinery exists so concurrent readers and writers never block each other. It's elegant engineering, and for mixed read-write workloads, it earns every byte.
But sensor data doesn't get updated. Log entries don't get edited. Financial ticks don't change after they land. If you're running an append-only workload, those bytes are infrastructure for a problem you don't have. At high ingest rates, they add up: a 1KB sensor reading actually writes 2.5-3.5KB to disk once you account for headers, indexes, and WAL records.
Autovacuum still runs continuously, even when there's nothing to clean up, because Postgres triggers it on insert volume alone.
None of this is a bug. It's an architecture built for a different workload pattern, doing exactly what it was designed to do. Recognizing the mismatch is more useful than trying to tune around it.
@mattstratton from Tiger Data (creators of @TimescaleDB) walks through the per-byte accounting, the write amplification chain, and what changes when the storage model actually fits the workload.
https://t.co/tKDr9O1ok8
Sensor data looks like rows, so most developers store it that way. Relational schema, transactional indexes, the patterns they already know. And it works, for a while.
The problem is that sensor data doesn't behave like rows. It behaves like a time-ordered stream whose value declines with age. The questions you ask of it shift from point lookups to time-window aggregations. The volume grows with every device you add and every sampling rate you increase. And the things that happen in production, out-of-order timestamps, data replays, late corrections, break systems that were designed for clean, ordered inserts.
By the time the architecture stops scaling, retrofitting it is expensive. The schema assumptions are load-bearing, and they're everywhere.
This article from the Tiger Data (creators of @TimescaleDB) blog walks through what actually needs to be different: log-optimized ingestion, time-partitioned storage, lifecycle tiering that lets resolution and cost decline together as data ages. The kind of design that starts from how sensor data actually behaves, not how it looks at first glance.
https://t.co/FYIus9wa5V
TimescaleDB 2.25 on Tiger Cloud: MIN/MAX/FIRST/LAST on compressed data now resolve from metadata instead of scanning chunks. Up to 289x faster.
COUNT(*) with time filters can skip the time column entirely. Up to 50x faster.
No query changes required.
Details: https://t.co/CznKZPjj9U
Start a free trial: https://t.co/JMbEvJg5oo
We're excited to share that Tiger Data is joining Chainguard Commercial Builds to provide secure, production-ready container images. Starting 3/17, TimescaleDB is available packaged inside the Chainguard Factory, a SLSA Level 3-compliant system that delivers:
✅ Minimal attack surface
✅ Zero CVEs
✅ Full provenance & SBOMs
✅ FIPS readiness
✅ SLAs for vulnerability remediation
Enterprises shouldn't have to choose between getting value from their software and maintaining the security layers beneath it. This partnership means your teams get TimescaleDB with the most secure software supply chain on the market - without the overhead of building, patching, or monitoring images yourself.
👉 https://t.co/rkwqtuzw79
#SoftwareSupplyChain #Chainguard #TimescaleDB