I break down high-tech companies to help you invest in the best growth stocks | Former @MITLL rocket scientist turned full-time investor | $7M AUM (and growing)
$NVDA's Q3 earnings prove that they are now UNSTOPPABLE:
• Overall revenue: $18.1 Billion, up 206% y/y
• Datacenter revenue: $14.5 Billion, up 279% y/y
• Earnings per share: $4.02, up 593% y/y 🤯
• $NVDA's P/E now lower than $TSLA or $PLTR
And their run has just begun:
$NVDA @NVIDIADC just shipped the biggest jump in AI yet.
I sat down with @nvidia Vice President of DGX Systems and he had a few surprising things to say.
Don't say I didn't warn you:
Great post. Minor flag:
12,000 GPUs in an NVL72 configuration = ~167 racks. Each Vera CPU rack delivers 22,528 cores / 45,056 threads. 400,000 cores ÷ 22,528 = ~18 Vera CPU racks alongside 167 GPU racks — roughly a 9:1 GPU rack to CPU rack ratio
In chip terms: 400,000 CPU cores ÷ 88 cores per Vera CPU chip = ~4,545 Vera CPU chips alongside 12,000 GPUs — roughly a 2.6:1 GPU chip to CPU chip ratio
That 33-to-1 ratio only looks so skewed toward CPUs because of mismatched units on Jensen's part.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
YOU make the long nights and weekends spent researching, writing, and editing worth it.
Thank you for spending some of your precious time with me each week! 🍻
💡 Building and scaling AI requires infrastructure that generates more revenue per watt and drives the lowest token cost.
NVIDIA Vera Rubin + LPX unlocks up to a 10x annual revenue opportunity from the same gigawatt-scale data center.
More tokens per watt. Higher value tokens = more intelligence + more interactivity.
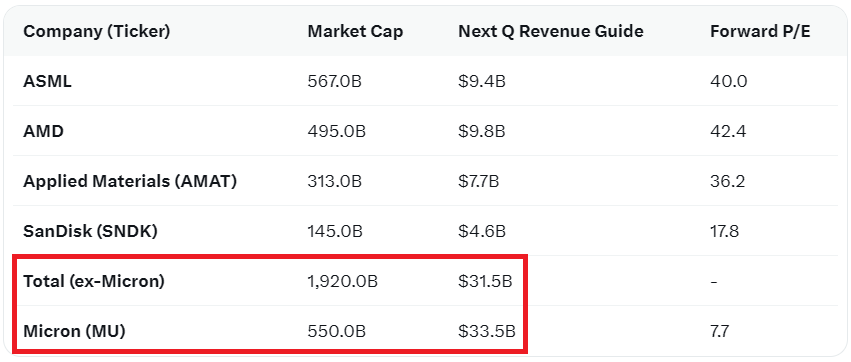
$MU Holy Shit
Micron will generate more revenue next quarter ($33.5B) than $AMD, $ASML, $AMAT, and $SNDK combined ($31.5B).
Their combined market cap is $1.92T. $MU sits at $0.55T with 81% margin guided.
Same output. Four times cheaper. You do the math.
@stpitts@nvidia It was great meeting you @stpitts! Thanks for taking the time and looking forward to chatting again in the future.
The Groq 3 LPU genuinely blew my mind!
Wall Street has NO IDEA what $NVDA's about to ship
Here's an exclusive look at @nvidia's mind-blowing Vera Rubin systems and the new Groq 3 LPU chips
Don't say I didn't warn you: