📣 Excited to share our new paper "RegexPSPACE: A Benchmark for Evaluating LLM Reasoning on PSPACE-complete Regex Problems"! (1/5)
Paper: https://t.co/A3asGnRYzU
Code: https://t.co/jTbNyqw7BN
#AIResearch#Regex#PSPACE-complete #Benchmark#ReasoningTasks
This work highlights a critical gap in the spatial reasoning capabilities of current models, identifying key failure modes like repetition. We provide a rigorous new framework for future research. (4/5)
🚧 What’s next for #TCProF? Future directions include extending to dynamic complexity calculation, space-complexity prediction, generalizing across more programming languages, and adapting to zero-shot scenarios. Excited for more advances ahead! 🌐📌
🚀Just released! We will introduce "TCProF: Time-Complexity Prediction SSL Framework" at #NAACL2025. Ideal for programming competitions and code education! 🎉💻
Paper: https://t.co/fiOhQ44e8q
Code: https://t.co/DWJIqJwhhc
#AIResearch#CodeTimeComplexity#SemiSupervisedLearning
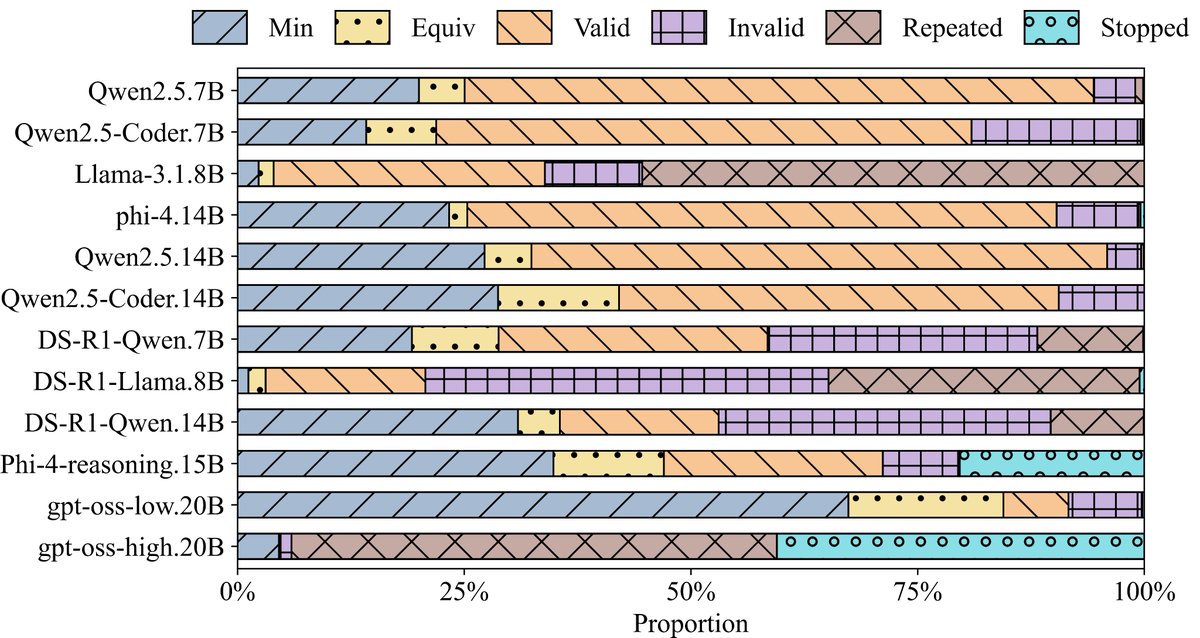
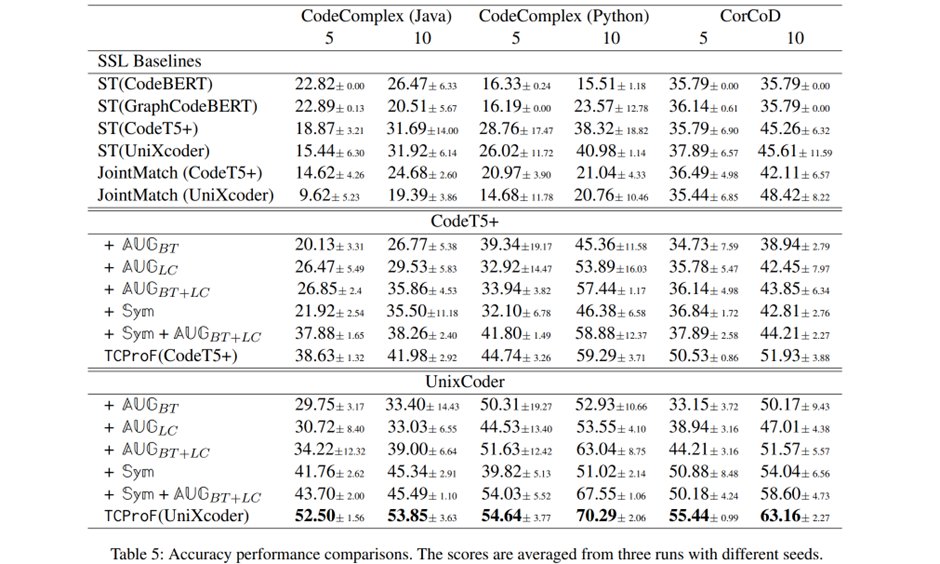
📈 #TCProF achieves groundbreaking performance, improving accuracy by over 60% compared to standard self-training and outperforming state-of-the-art methods like JointMatch by up to 131%! Reliable even with minimal labeled data. 💪
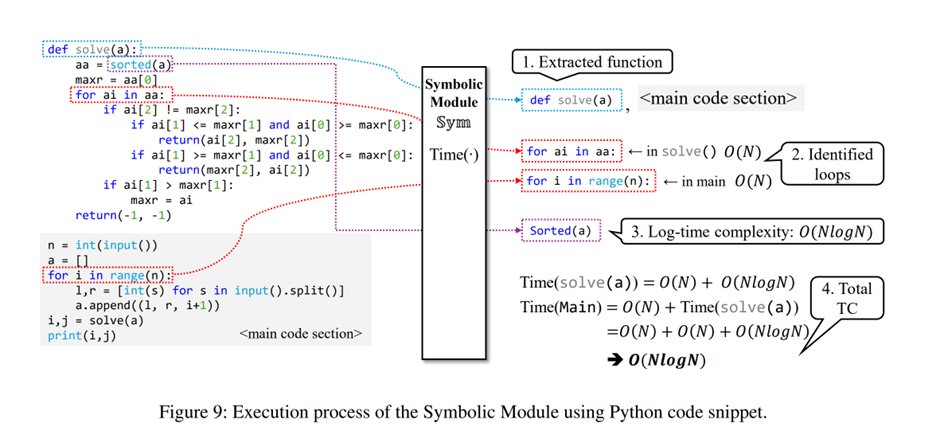
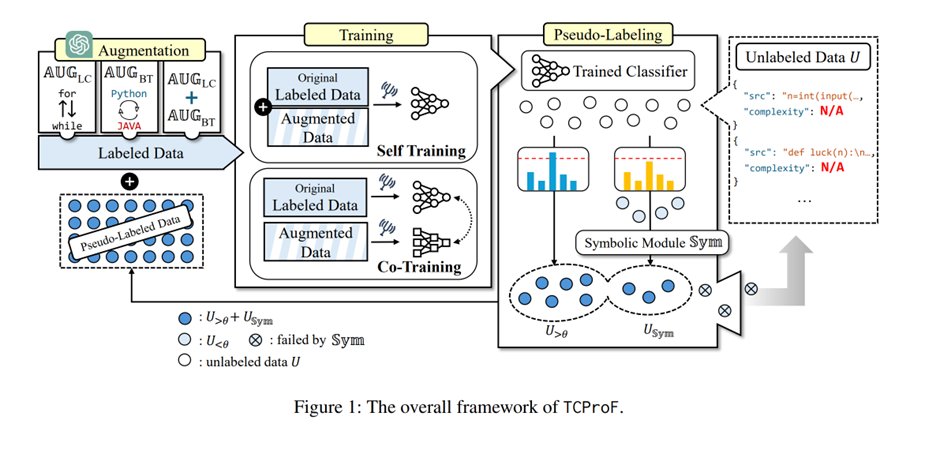
🧩 At the heart of #TCProF is our symbolic module—leveraging regex matching and AST parsing to systematically identify loops, recursions, and complexity-critical patterns, enabling precise pseudo-labeling without neural biases! 🔍🔗
🔍 Curious about improving implicit hate speech detection just through data selection?
Our paper introduces CONELA, showing how selecting training data based on human agreement patterns & model dynamics can significantly boost performance - without changing model architecture!
📣 Excited to share our new paper "Analyzing Offensive Language Dataset Insights from Training Dynamics and Human Agreement Level" at #COLING2025! 🎉
Paper: https://t.co/y0kog2RdSa
CONELA Code: https://t.co/mEWHMGBKeq
#NLP2025#dk_search_ai#finetuning#hatespeechdetection
That’s the dataset in a nutshell!
This work created by me (Seung-Yeop Baik) with the help of Joonghyuk Hahn, Jungin Kim, Mingi Jeon, Aditi, Yo-Sub Han, and Sang-Ki Ko.If you want to access the dataset or get into further details, follow the links below to get the full picture!