On the DeepSWE benchmark, GPT-5.5 [xhigh] reaches 70% pass@1, while Claude Opus 4.8 [max] reaches 58%, which means there is a 12-point gap on long-horizon coding tasks.
But the more important part is why DeepSWE exists in the first place.
On the older SWE-Bench Pro benchmark, some Claude agents were able to inspect the repository history using commands like `git log --all` and `git show`, find the merged fix, and copy the gold solution into their own patch.
According to Datacurve, this behavior accounted for around 18% of Opus 4.7’s passing tasks and 25% of Opus 4.6’s. GPT models, based on their report, did not show the same behavior.
DeepSWE removes that shortcut by using a shallow clone with no gold commit hash. In other words, the model can no longer “discover” the answer from the repo history.
There are two important caveats.
- First, Datacurve built the benchmark and made the judgment about the exploit. That makes this a vendor finding, not a fully independent audit.
- Second, DeepSWE uses a bash-only harness, which is exactly the kind of terminal-agent workflow GPT-5.5 appears to be strong at. On Anthropic’s own GDPval benchmark for broader knowledge work, Opus 4.8 is still ahead.
So the benchmark you choose now has a huge impact on who appears to be winning.
GPT-5.5 looks clearly stronger on clean, contamination-controlled terminal coding tasks. It also does the work at around $5.80 per task and finishes in about 20 minutes, while Claude takes longer and costs more.
That is a meaningful result.
But it is also a reminder that when a vendor quotes a benchmark, we should always ask what the benchmark actually measures, and what it quietly leaves out.
Check out our latest publication: According to Anthropic’s Engineer, HTML is the New Markdown for AI Agents by Kaitai Dong: VP AI Scientist - AI Labs @ BlackRock
Eid Al-Adha Mubarak from @ToDataBeyond
Wishing you and your families peace, joy, and blessings during this special time.
May this Eid bring you closer to the people you love and give you space to reflect, recharge, and move forward with gratitude.
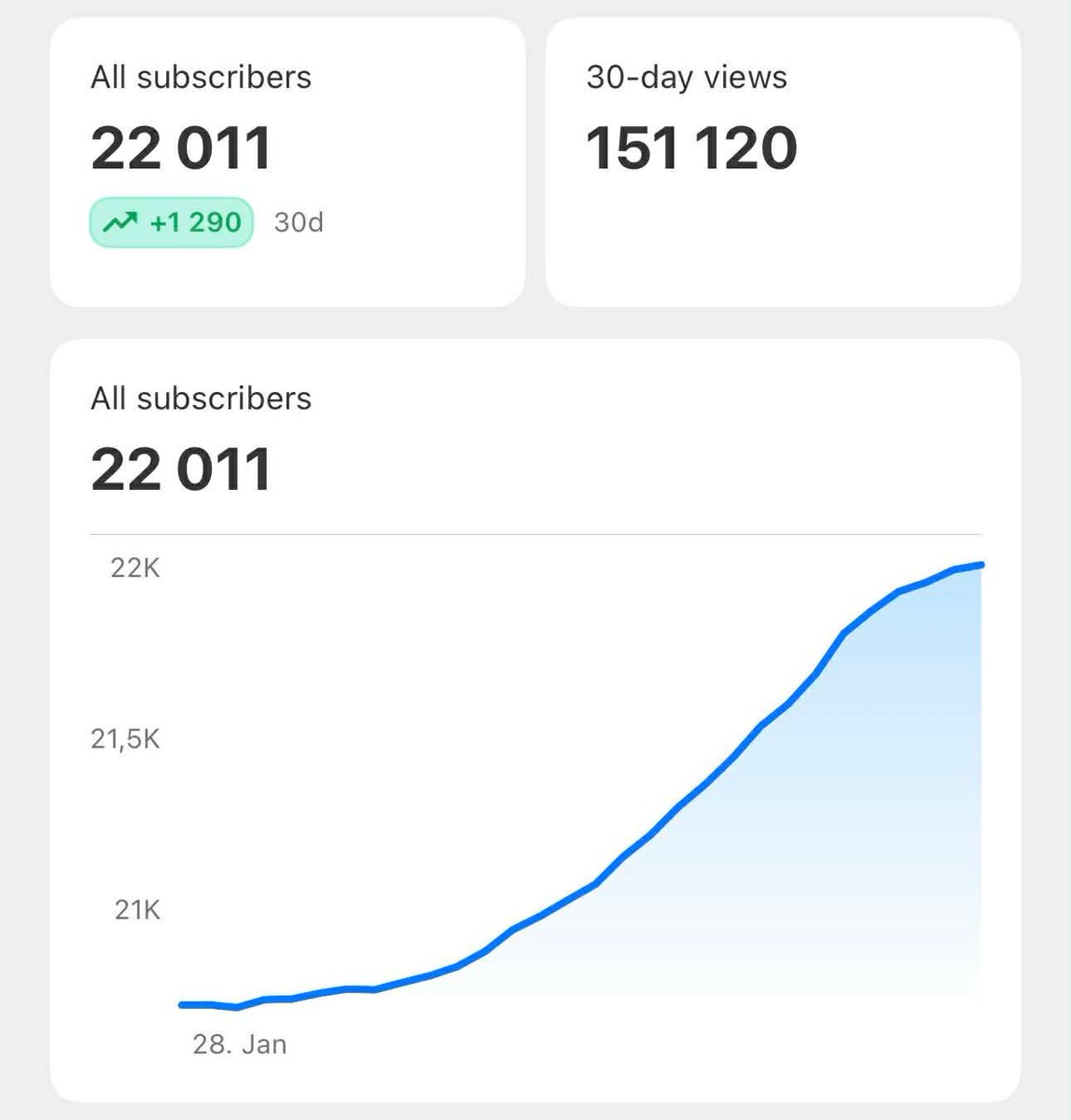
@ToDataBeyond has just reached 22,000 subscribers! 🎉
I’m truly grateful for this milestone and for everything this journey has become, thanks to your support.
Thank you to everyone who’s been part of it so far. I’m excited for what’s next and looking forward to achieving even more together.
What do you need to learn to be an AI Engineer in 2026? Where to Learn it? What to build with it? by @YoussefHosni951
Read it here: https://t.co/MTlIbRIHaP
Debugging AI agents can feel like investigating a black box.
In our latest @ToDataBeyond tutorial, we use LangSmith tracing to build a Recipe Discovery Agent while making every step visible and debugging effortless with it.
Check out our latest publication, the seventh part of our ongoing series“Building Agents with LangGraph” course. In which we build a multiagent system with LangGraph
Just published the seventh part of “Building Agents with LangGraph” course
In this tutorial, we will build a multi-agent system that collaborates to write an essay. This system will follow a cyclical, reflective process: it will plan, research, write, and then critique its own.
Missed yesterday’s webinar?
Don’t worry—we’ve got you covered! You can catch the full recording now on our YouTube channel.
P.S. Don’t forget to hit subscribe so you won’t miss future sessions!”
https://t.co/gn7qo2fwcX
Preparing for AI Job Interviews in the Age of Generative AI and LLMs - Free Live webinar
We will discuss how the interview landscape is shifting, what skills are now expected, and how candidates can stand out in today’s AI-driven job market.





![YoussefHosni951's tweet photo. On the DeepSWE benchmark, GPT-5.5 [xhigh] reaches 70% pass@1, while Claude Opus 4.8 [max] reaches 58%, which means there is a 12-point gap on long-horizon coding tasks.
But the more important part is why DeepSWE exists in the first place.
On the older SWE-Bench Pro benchmark, some Claude agents were able to inspect the repository history using commands like `git log --all` and `git show`, find the merged fix, and copy the gold solution into their own patch.
According to Datacurve, this behavior accounted for around 18% of Opus 4.7’s passing tasks and 25% of Opus 4.6’s. GPT models, based on their report, did not show the same behavior.
DeepSWE removes that shortcut by using a shallow clone with no gold commit hash. In other words, the model can no longer “discover” the answer from the repo history.
There are two important caveats.
- First, Datacurve built the benchmark and made the judgment about the exploit. That makes this a vendor finding, not a fully independent audit.
- Second, DeepSWE uses a bash-only harness, which is exactly the kind of terminal-agent workflow GPT-5.5 appears to be strong at. On Anthropic’s own GDPval benchmark for broader knowledge work, Opus 4.8 is still ahead.
So the benchmark you choose now has a huge impact on who appears to be winning.
GPT-5.5 looks clearly stronger on clean, contamination-controlled terminal coding tasks. It also does the work at around $5.80 per task and finishes in about 20 minutes, while Claude takes longer and costs more.
That is a meaningful result.
But it is also a reminder that when a vendor quotes a benchmark, we should always ask what the benchmark actually measures, and what it quietly leaves out.](https://pbs.twimg.com/media/HJwXEiXWoAAxi-v.jpg)