Neutral insights & reliable info services for the shifting landscape. Delivering ultra-fast, stable, native, and full-featured China-cost-performance APIs.
We just launched tokenbus on Product Hunt! 🚀
Many devs are struggling to integrate DeepSeek into global apps due to network barriers and billing issues. We’re changing that. No black-box aggregators, just a clean, professional, and fast bridge to the official DeepSeek model.
Get your low-latency pipeline ready in seconds.
Join the discussion here:
https://t.co/7fRtVJapoE
[ FREE $2 FOR CLINE / CURSOR USERS ]
Full-Precision (Unquantized) DeepSeek V4 & Kimi K2.6 API. Standard OpenAI-compatible protocol.
How to claim $2 credits:
Go to https://t.co/7ECWRnCZFi & register.
Redeem Code:
82e865e98a6049ea9e8e781881be5b81
Point Cline Base URL to: [https://t.co/CpQIK7XhO8](https://t.co/CpQIK7XhO8)
Pure unquantized reasoning fidelity. First 50 slots only. ⚡
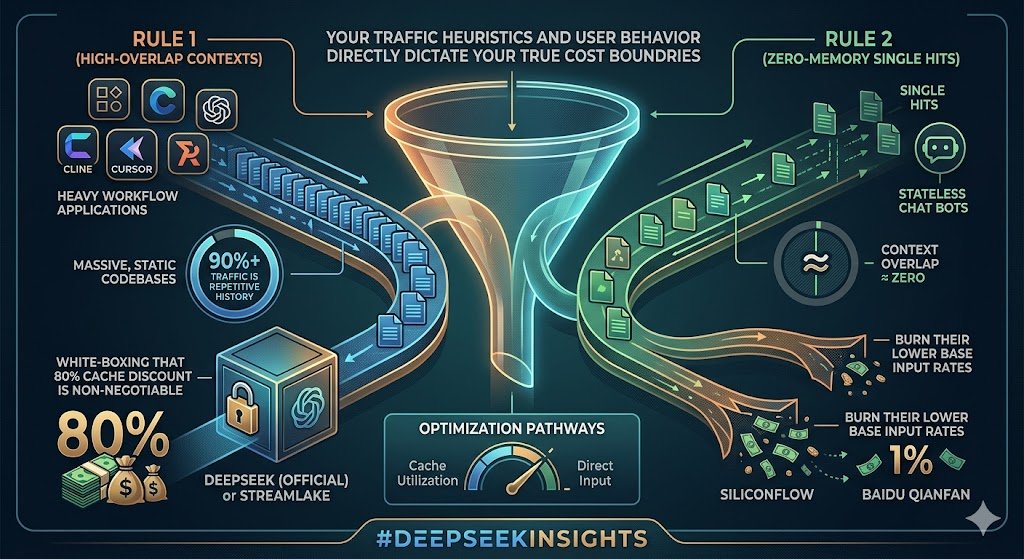
Your traffic heuristics and user behavior directly dictate your true cost boundaries.
Rule 1 (High-Overlap Contexts): If you are running heavy Agent workflows (e.g., Cline, Cursor) or querying massive, static codebases where 90%+ of traffic is repetitive history, lock your preset to DeepSeek (Official) or StreamLake. White-boxing that 80% cache discount is non-negotiable.
Rule 2 (Zero-Memory Single Hits): For multi-tenant distributed endpoints, stateless chat bots, or bulk JSON formatting where context overlap is near zero, bypass the official channel. Go straight to SiliconFlow or Baidu Qianfan to burn their lower base input rates.
#DeepSeekInsights #Deepseek
Modern GPUs (A100/H100) Tensor Cores have ZERO native acceleration for FP4. During decoding, the provider forces a non-native software kernel to decompress weights *on the fly* for every single token generated.
It’s an engineering illusion: Fast off the starting line, completely paralyzed on the highway. #DeepSeek #MoE #Quantization #tokenbus
The hidden trap of 4-bit quantized reasoning models like DeepSeek V4 Flash FP4: The "Stupidity Tax" paid in Output Tokens. See https://t.co/dmoIeDEJSI
When you butcher model weights down to 4-bit, the fine-grained probability gradients collapse. To pass the same LeetCode or agentic math test, the model enters a violent internal logic-loop. It compensates for precision loss by vomiting 3x more `Thinking Tokens` just to self-correct.
The benchmark says the intelligence score is "close to official," but your bill tells a different story. You aren’t buying an optimized node; you are subsidizing the model's internal mess at $0.28/1M output tokens.
White-box infra doesn't play leaderboard games. Keep your pipelines lean. #DeepSeek #AIInfra #tokenbus
On May 29, @deepseek_ai silently slashed input-edit and regeneration caps on its Web/App interface—throttling standard chats to ~6 prompts and Expert Mode to a brutal 3-strike limit.
The Anatomy of the Bleed:This isn't a "negative optimization" update; it's a structural tourniquet. Industrial-scale scrapers have been weaponizing the free v4pro tier via automated reverse-proxies. They syphon DeepSeek’s raw compute, repackage the stolen tokens, and flip them on the black market as premium GPT/Claude API channels. The result? Chronic server congestion and a direct assault on the cluster’s bare metal.
The Architecture of Reality:From OpenAI to Anthropic, the baseline is rigid: every token has a thermodynamic and monetary cost. Unlimited SOTA inference is a mathematical illusion. For serious pipelines, switching to their dirt-cheap commercial API isn't an option—it's the only rational engineering choice.
Relief is projected for H2 2026 with the deployment of new Huawei Ascend hyper-nodes, but the era of the lawless, unmetered AI buffet is officially dead.
#DeepSeek #LLM
We just audited 12 major vendors hosting DeepSeek-V4-Flash on OpenRouter , and the raw data revealed a fascinating industry consensus along with some hidden architectural divergence.
First, the consensus: Over half of the providers (including Parasail, AtlasCloud, and AkashML) have anchored their pricing strictly at $0.14/M input and $0.28/M output. This tacit agreement indicates that under current compute economics, this exact price point represents the optimal equilibrium for sustaining lossless/high-precision deployments while securing a healthy margin.
#DeepSeekInsights #Deepseek