we've been cooking on entity resolution 👩🍳 in this demo, we extract all the majors/degrees from a messy resume and resolve them to the government CIP taxonomy 🤯 i think we are accidentally building a resume parser RIP 💀
With Taylor, you can build as many classifiers and entity extractions as you want for free. You only pay for usage once you're satisfied with results 😁
the AI race has never been faster. if you're not shipping, you're falling behind OpenAI. that's why we also shipped a blog post today! 😉
check it out to learn how we automatically extract skills from job postings & resolve to a skills taxonomy. link below 🚀🚀 🚀
no one's talking about the 86M param moderation model meta released this week!! so i decided to talk about it. read my yapping about PromptGuard below 😁
Today, common ways to build entity extraction are (a) use a LLM or (b) use AWS.
LLMs are easy to use but can be unreliable. AWS is scalable but difficult to use.
If you need high accuracy AND seamless out-of-the-box entity extraction, check out our Entity Extraction!
If you want to extract key information from documents, but you're struggling to deduplicate misspellings, alternative names for the same thing, etc. this might be just what you need!
Our entity extraction deduplicates and matches entities to your set of unique labels.
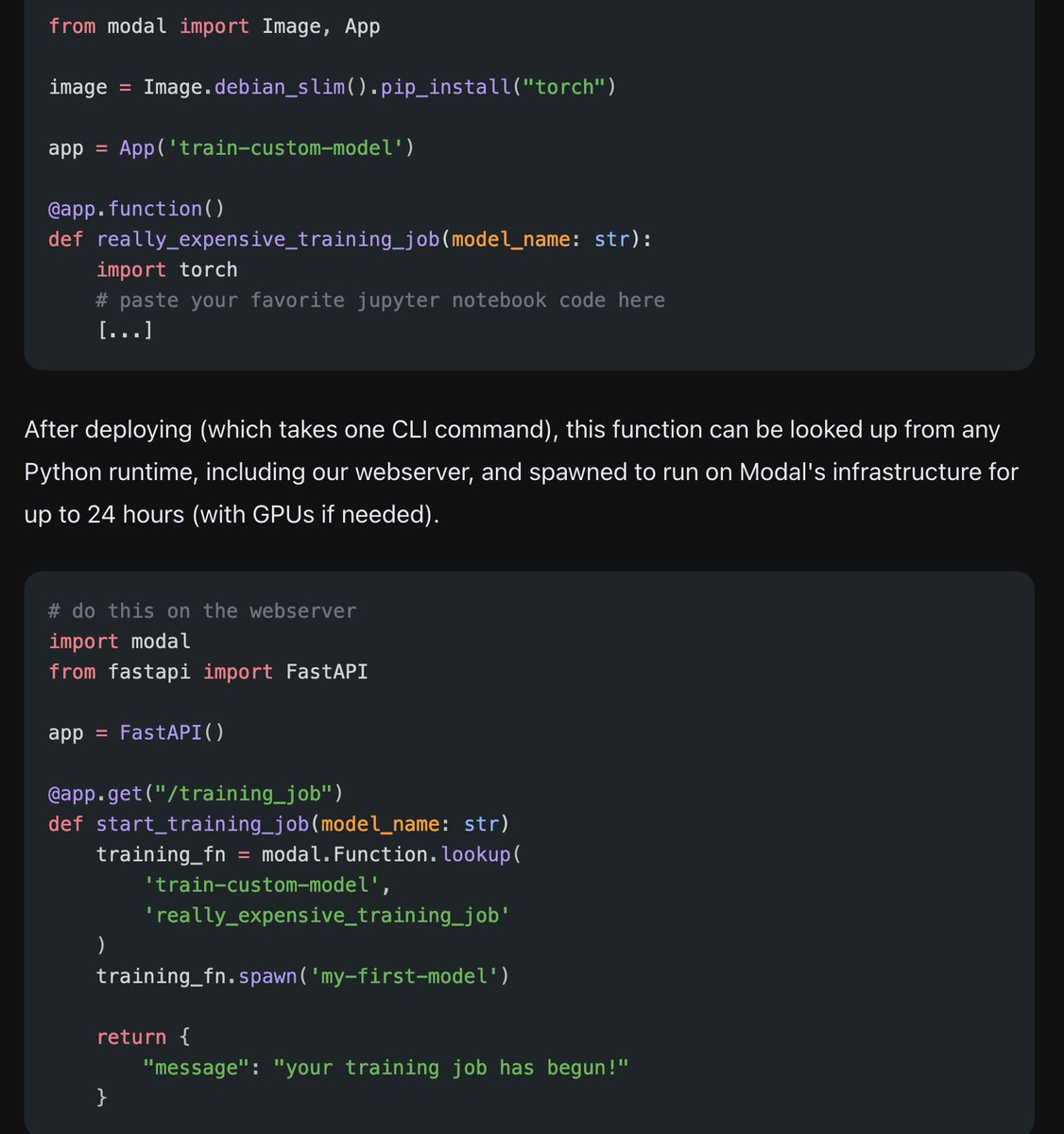
It's been awesome watching @andersonbcdefg cook using Modal!
"The ability to spawn jobs from one Python environment that run in a totally different Python environment (different packages, more CPUs, GPUs, etc.) is a great benefit to machine learning engineers."
We are so excited to share more about our partnership with @modal_labs , a serverless platform for high-performance computing.
Check out our blog for how we use Modal to build & deploy high accuracy text classification models for our users.
https://t.co/kJqaCGk0Uo