Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
Audio is the modality of interaction. Audio language model is out.
Introducing the Audio Interaction Model, a new paradigm for end to end streaming unified audio models
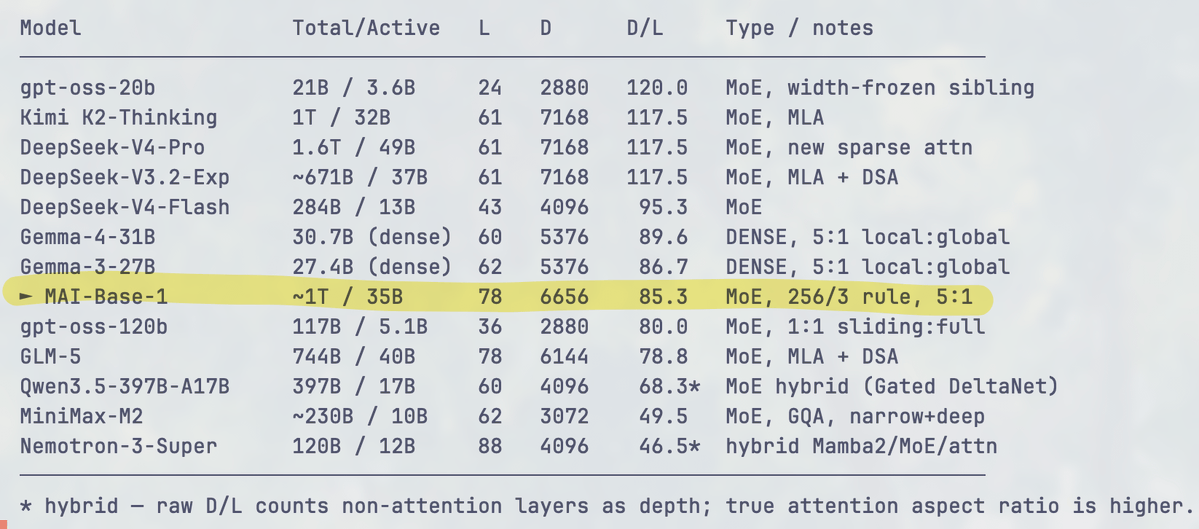
the only knob they change is model depth (number of layers), everything is derived from it with heuristics.
first heuristic:
hidden size = L * 256/3
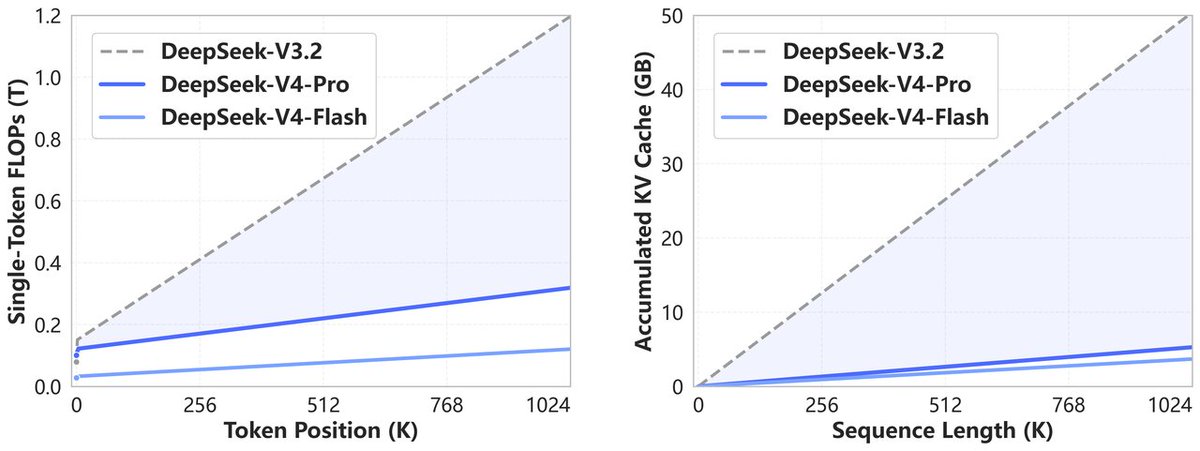
this is derived from recent models, here is how it compares to others.
other parameters:
- fixed expert sparsity (unless ablated)
- FFN expansion is 2x, latentMoE hyperparameters are 2x compression -> 3x expansion (see the plot on latentMoE to understand what this means)
IIUC, this reads inputs N times to update the memory more. This is something I tried in Infini-attention and it does improve in some cases for NIH but was not consistent.
Our fix is simple: to use N recurrent forward passes for learning fast weights. This gives the model enough time to learn a good representation of context. We call this process “sleep”. This is not the same as looped transformers–our model still uses a single forward pass outside the sleep phase (i.e. when the context window is not full).
Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
https://t.co/c9AvsRKybj
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: https://t.co/CRj96VGYQn
GitHub: https://t.co/eNW0K9Xh8E
🐟
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Today we release Contrastive Neuron Attribution (CNA), a method for steering LLM behavior by identifying and ablating sparse circuits in the MLP basis without training a sparse autoencoder, modifying weights, or degrading general capability benchmarks.
Given a small set of contrastive prompt pairs that elicit a target behavior and its opposite, CNA isolates the top 0.1% of MLP neurons whose activations differ most between the two sets. Ablating that small circuit removes the behavior while leaving the rest of the model intact, and the intervention remains robust at high strengths where residual-stream methods like Contrastive Activation Addition (CAA) start to degrade.
Validated on the refusal circuit across 8 instruct-tuned models, including Llama-3.1-70B, Llama-3.2-3B, Qwen2.5-72B, and Qwen2.5-14B.
The work on CNA was led by @yaboilyrical, with support from @qorprate and @karan4d.
Albert Einstein + ElevenLabs.
AI agents can make education more accessible - a teacher for every student in every field. A classroom size of one learning from icons who shaped the world
Today with his estate, we’re bringing Albert Einstein to ElevenLabs
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn.
This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information.
In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can …
🔵Be created by instruction-tuning for the stream format
🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in)
🔵Multi-Stream LLMs are fast, they can predict+read tokens in all streams in parallel in each forward pass, improving latency
🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security
🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized.
Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
What do we gain? First off, we can improve latencies because we now overlap thinking, system inputs, tool use and even auditing calls (and we show this in the paper).
Second, we find that the models we train in a clean ablation with this format actually have a significantly easier time withstanding prompt injections, because it is easier to separate input and output if they are separate streams.
this is fascinating, they train an encoder/decoder but use LLM matching the target model's shape for each part, so the latent space is just plain language and they can detect reward hacking, unwanted behavior and more
could even see it being used as an eval to quantify how smart a model is, i love this
Interesting! Few years back, I did experiment and observed 4x reduction without regression. In some cases, it even gave boost. But still entailed computing that giant LxL matrix so I dropped it.















![fly51fly's tweet photo. [LG] Reward Models Are Secretly Value Functions: Temporally Coherent Reward Modeling
A Nikulkov [AI at Meta] (2026)
https://t.co/UCxxkYtD7w https://t.co/d1hZpW31ou](https://pbs.twimg.com/media/HHBZFV2boAEc_S7.jpg)
![fly51fly's tweet photo. [LG] Reward Models Are Secretly Value Functions: Temporally Coherent Reward Modeling
A Nikulkov [AI at Meta] (2026)
https://t.co/UCxxkYtD7w https://t.co/d1hZpW31ou](https://pbs.twimg.com/media/HHBZFJKbAAAe1rs.jpg)
![fly51fly's tweet photo. [LG] Reward Models Are Secretly Value Functions: Temporally Coherent Reward Modeling
A Nikulkov [AI at Meta] (2026)
https://t.co/UCxxkYtD7w https://t.co/d1hZpW31ou](https://pbs.twimg.com/media/HHBZEzCaUAAi_lB.png)



















![fly51fly's tweet photo. [LG] Reward Models Are Secretly Value Functions: Temporally Coherent Reward Modeling
A Nikulkov [AI at Meta] (2026)
https://t.co/UCxxkYtD7w https://t.co/d1hZpW31ou](https://pbs.twimg.com/media/HHBZFhObUAEvQri.jpg)