The Biomedical NLP group co-located at the University of Massachusetts Amherst and Lowell. Led by Dr. Hong Yu. @UMass_NLP @manningcics @UMassLowell #NLProc
@PrakamyaMishra@YaoZonghai@vashisht51 🔔 Conclusion:
This study leverages synthetic edit feedback to improve factual accuracy in clinical summarization using DPO and SALT techniques. Our approach demonstrates the effectiveness of LLM-based edit data in enhancing the reliability of clinical NLP applications.
(14/N)
🎉 New paper alert! #EMNLP24
SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
🔗 https://t.co/ZzGlJNm7nA
Work done by @PrakamyaMishra@YaoZonghai@vashisht51, Feiyun Ouyang, Beining Wang, Vidhi Dhaval Mody, and Prof. Hong Yu
(0/N)
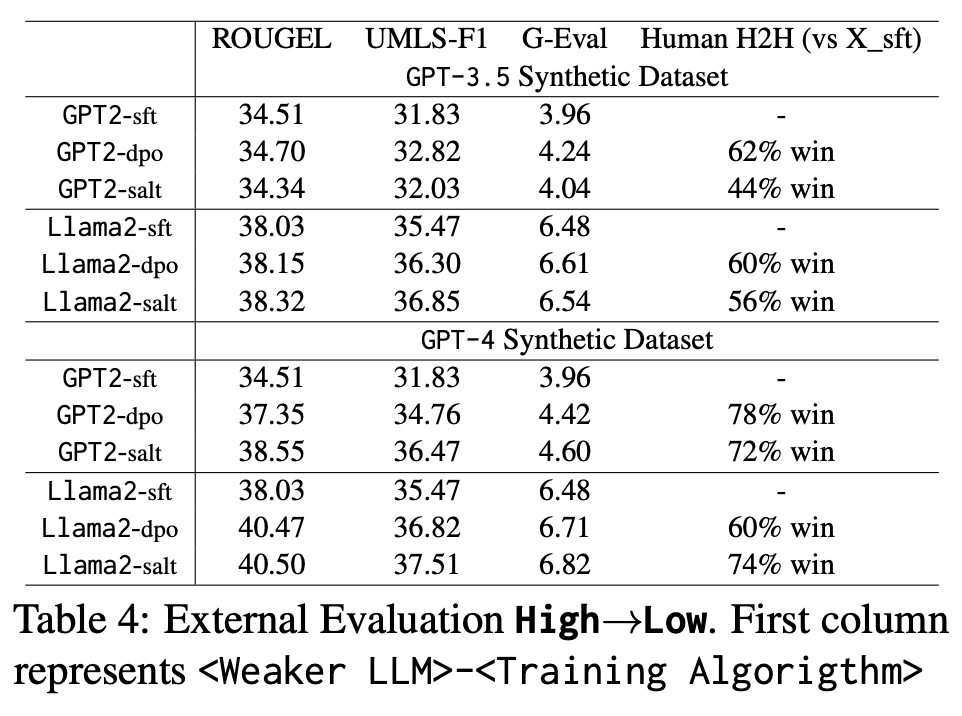
@PrakamyaMishra@YaoZonghai@vashisht51 📊 External Evaluation: We compared STF-trained models vs. DPO/SALT-trained ones and found that GPT-2 & Llama2 excelled with GPT-4 edits over GPT-3.5. SALT's granular feedback improved alignment, with GPT-2 showing higher ROUGEL in High→Low training and stable factuality.
(13/N)
@jcz12856876 @YaoZonghai@YangZhichaoNLP 📊 Results show that LLMs’ self-explanations are quite different from Human-craft CoTs and have less variance, though using LLMs’ self-explanations for ICL leads to better performance. We also question treating human-craft CoTs as the gold standard for in-context exemplars. (8/N)
🎉 New paper alert!
Large Language Models are In-context Teachers for Knowledge Reasoning #EMNLP24 finding
🔗 Read the paper: https://t.co/jkOPm4cSZL
Work done by @jcz12856876 @YaoZonghai@YangZhichaoNLP and Prof. Hong Yu
#BioNLP#InstructionTuning
(0/N)
@jcz12856876 @YaoZonghai@YangZhichaoNLP 🧪 To verify the causality, we propose teach-back to align the teacher’s rationales with the student’s self-explanations. Experiments show that teach-back can greatly improve the in-context teaching ability of a model.
(7/N)