AI Engineering Specialization
🚀 Intro to AI Engineering
🔓 Open-source AI Models
🧠 Learn Embeddings and Vector Databases
🤖 Learn AI Agents
💬 Learn OpenAI's Assistant API
📱 Build AI Apps with LangChain.js
https://t.co/ps2NBsewLi
New Andrej Karpathy interview: "To get the most out of the tools that have become available now, you have to remove yourself as the bottleneck.
You cannot be there to prompt the next thing. You need to take yourself outside the loop. You have to arrange things such that they are completely autonomous.
The more you can maximize your token throughput and not be in the loop, the better. This is the goal. So, I kind of mentioned that the name of the game now is to increase your leverage. I put in very few tokens just once in a while, and a huge amount of stuff happens on my behalf."
---
From @NoPriorsPod YT channel (link in comment)
You can now train Qwen3.5 with RL in our free notebook!
You just need 8GB VRAM to RL Qwen3.5-2B locally!
Qwen3.5 will learn to solve math problems autonomously via vision GRPO.
RL Guide: https://t.co/iR9AF3BIFu
GitHub: https://t.co/aZWYAtakBP
Qwen3-4B: https://t.co/OzzCLFkSoW
Spending hours watching #longvideos just to find a few key insights? There’s a smarter way. With DoblAI, instantly generate accurate #transcripts, #translations and #subtitles — fully synced and ready to use. Work faster, repurpose content easily, and make every video count
Excited to share our latest deep-dive on @NVIDIA's DGX Spark AI-PC! Discover how we unlocked advanced reasoning in Llama 8B through full fine-tuning—entirely offline, thanks to DGX Spark’s unified 128GB memory.
Learn how synthetic data and chain-of-thought prompts are pushing the boundaries of local LLMs.
🖇️ Read the full recipe and results on the PyTorch Foundation blog: https://t.co/EJ2YNyYXDK
👥 @bhutanisanyam1 (PyTorch Meta), Hamid Shojanazeri (PyTorch Meta), Clement Anthonioz Blanc (Meta)
#PyTorch #DGXSpark #AI #LLM #FineTuning
A solid 65-page long paper from Stanford, Princeton, Harvard, University of Washington, and many other top univ.
Says that almost all advanced AI agent systems can be understood as using just 4 basic ways to adapt, either by updating the agent itself or by updating its tools.
It also positions itself as the first full taxonomy for agentic AI adaptation.
Agentic AI means a large model that can call tools, use memory, and act over multiple steps.
Adaptation here means changing either the agent or its tools using a kind of feedback signal.
In A1, the agent is updated from tool results, like whether code ran correctly or a query found the answer.
In A2, the agent is updated from evaluations of its outputs, for example human ratings or automatic checks of answers and plans.
In T1, retrievers that fetch documents or domain models for specific fields are trained separately while a frozen agent just orchestrates them.
In T2, the agent stays fixed but its tools are tuned from agent signals, like which search results or memory updates improve success.
The survey maps many recent systems into these 4 patterns and explains trade offs between training cost, flexibility, generalization, and modular upgrades.
Google just dropped "Attention is all you need (V2)"
This paper could solve AI's biggest problem:
Catastrophic forgetting.
When AI models learn something new, they tend to forget what they previously learned. Humans don't work this way, and now Google Research has a solution.
Nested Learning.
This is a new machine learning paradigm that treats models as a system of interconnected optimization problems running at different speeds - just like how our brain processes information.
Here's why this matters:
LLMs don't learn from experiences; they remain limited to what they learned during training. They can't learn or improve over time without losing previous knowledge.
Nested Learning changes this by viewing the model's architecture and training algorithm as the same thing - just different "levels" of optimization.
The paper introduces Hope, a proof-of-concept architecture that demonstrates this approach:
↳ Hope outperforms modern recurrent models on language modeling tasks
↳ It handles long-context memory better than state-of-the-art models
↳ It achieves this through "continuum memory systems" that update at different frequencies
This is similar to how our brain manages short-term and long-term memory simultaneously.
We might finally be closing the gap between AI and the human brain's ability to continually learn.
I've shared link to the paper in the next tweet!
Need to optimize applications with large models and stretched memory resources?
Learn how to accelerate large-scale LLM inference and Cache Offload with CPU-GPU Memory Sharing in NVIDIA’s recent developer tech blog:
📎: https://t.co/eyx4DLi6ta
#PyTorch#OpenSourceAI#AI #Inference #Innovation
NVIDIA's brilliant paper gives a lot of details and actionable techniques. 🎯
Small Language Models (SLMs) not LLMs are the real future of agentic AI.
They gave a recipe for swapping out the large models with SLMs without breaking anything and show that 40%‑70% of calls in open agents could switch today.
It argues that SLMs, already match big models on many routine agent tasks, cost far less to run, and slot neatly into mixed‑model pipelines, so most agent calls should shift to SLMs.
🗝️ The central claim
SLMs that fit on a laptop already handle the narrow language chores inside most agents.
Because those chores rarely need open‑ended chat, the authors say an SLM‑first design is the natural default, and large models become occasional helpers.
@NVIDIAAIDev 👏
This github repo is a goldmine.
3.4K Starts ⭐️ in 4 days.
end-to-end, code-first tutorials covering every layer of production-grade GenAI agents, guiding you from spark to scale with proven patterns and reusable blueprints for real-world launches.
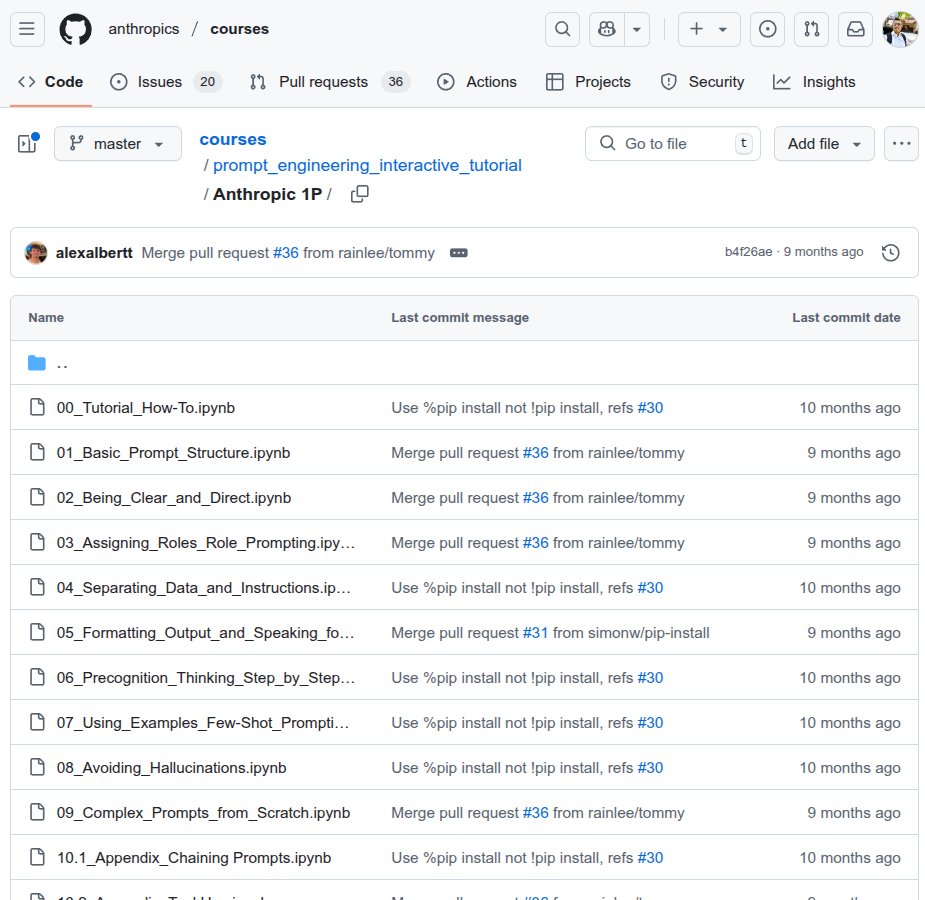
Anthropic free masterclass on prompt engineering is one of the best 👌
Teaches you how to write effective prompts for Claude models. You’ll start with basic prompt structure, clarity, and role assignment in three beginner chapters.
Intermediate lessons cover separating data from instructions, formatting outputs, and step-by-step reasoning (“precognition”), with hands-on exercises to reinforce each topic.
Advanced chapters tackle hallucination avoidance and building complex prompts for chatbots, legal, financial, and coding use cases. Interactive “Example Playground” sections let you experiment in real time and refer to an answer key for guidance.
¡Llegaste hasta el final!
Si te ha gustado este hilo, por favor retuitea y dale me gusta al primer tweet y sígueme @PropositoyVida
Te recomiendo guardar el hilo, para que puedas consultarlo cuando quieras.
Ayúdame a que más personas lo lean.
¡Muchas gracias por tu apoyo!
Seeing the level of understanding of the physical world of the latest vision models, the question is not if this is intelligence but if our intelligence is actually this.
https://t.co/w5ZREG32nb
Take a close look at RAG (Retrieval Augmented Generation), an established approach used by DataGemma to generate a comprehensive response utilizing Data Commons. 🧐 → https://t.co/Mec1xSHyio