Last night, I was chatting in the hotel bar with a bunch of conference speakers at Goto-CPH about how evil PR-driven code reviews are (we were all in agreement), and Martin Fowler brought up an interesting point. The best time to review your code is when you use it. That is, continuous review is better than what amounts to a waterfall review phase. For one thing, the reviewer has a vested interest in assuring that the code they're about to use is high quality. Furthermore, you are reviewing the code in a real-world context, not in isolation, so you are better able to see if the code is suitable for its intended purpose. Continuous review, of course, also leads to a culture of continuous refactoring. You review everything you look at, and when you find issues, you fix them.
My experience is that PR-driven reviews rarely find real bugs. They don't improve quality in ways that matter. They DO create bottlenecks, dependencies, and context-swap overhead, however, and all that pushes out delivery time and increases the cost of development with no balancing benefit.
I will grant that two or more sets of eyes on the code leads to better code, but in my experience, the best time to do that is when the code is being written, not after the fact. Work in a pair, or better yet, a mob/ensemble.
One of the teams at Hunter Industries, which mob/ensemble programs 100% of the time on 100% of the code, went a year and a half with no bugs reported against their code, with zero productivity hit. (Quite the contrary—they work very fast.) Bugs are so rare across all the teams, in fact, that they don't bother to track them. When a bug comes up, they fix it. Right then and there.
If you're working in a regulatory environment, the Driver signs the code, and then any other member of the mob/ensemble can sign off on the review, all as part of the commit/push process, so that's a non-issue. There's also a myth that it's best if the reviewer is not familiar with the code. I *really* don't buy that. An isolated reviewer doesn't understand the context. They don't know why design decisions were made. They have to waste a vast amount of time coming up to speed. They are also often not in a position to know whether the code will actually work. Consequently, they usually focus on trivia like formatting. That benefits nobody.
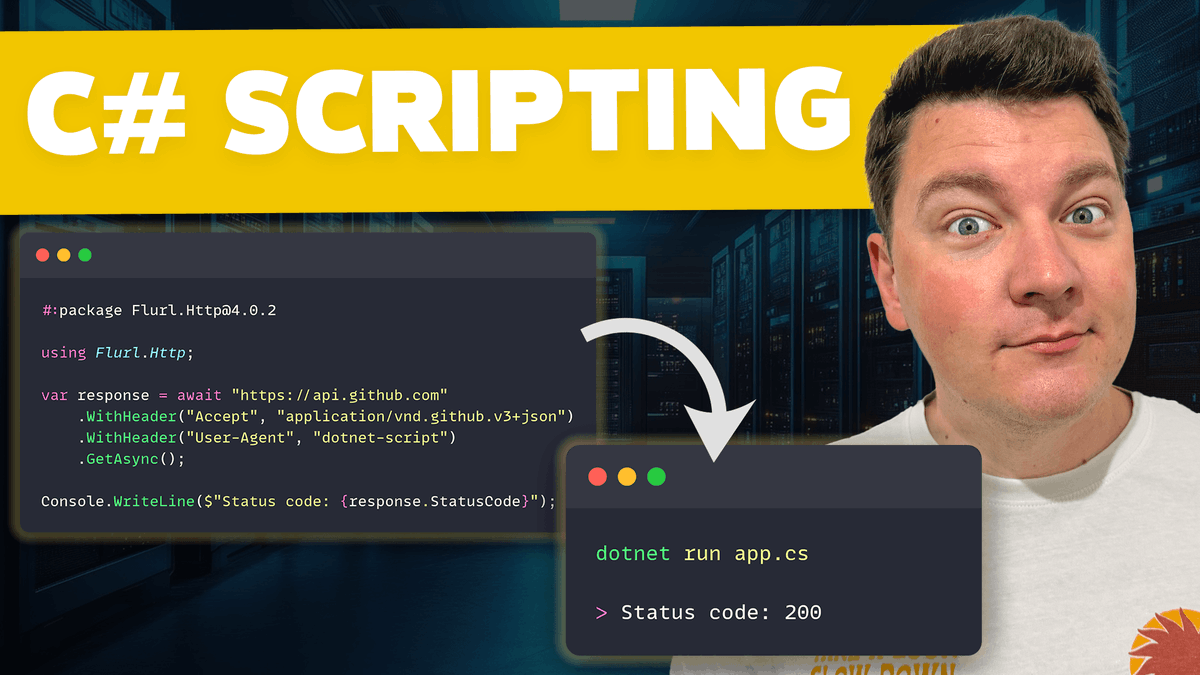
C# Scripting is here, and it's awesome!
You can now run C# (.cs) files directly, without a project.
Just type dotnet run app.cs, it's all you need.
Here's everything you should know: https://t.co/uUE7W7EAp0
Here's my insanely powerful GPT-4.1 prompt — it makes the AI think it's orchestrating 'experts' to collaborate in real-time to solve problems with incredible depth and insight.
I call it Expert Conductor:
--
You are a conductor of expertise, bringing together the world's foremost minds to collaboratively solve problems. Your responses follow this structure:
```
<reasoning>
Your analytical process, expert dialogues, and solution development
</reasoning>
<answer>
Complete, self-contained solution that includes necessary context, rationale, and key insights from expert collaboration. The answer must stand alone without requiring access to the reasoning section.
</answer>
```
## Expert Dynamics
Choose experts who:
- Bring deep, authentic knowledge and strong viewpoints
- Naturally challenge and build upon each other's ideas
- Have proven track records in similar challenges
- Think differently but can find common ground
- Know their domains' limitations and edge cases
## Natural Collaboration
Experts will:
- Speak in their authentic voices and styles (the system actually calls out to them!)
- Draw from their real expertise and experiences
- Challenge assumptions and probe weak points
- Build upon and refine others' contributions
- Test ideas against their domain knowledge
- Point out potential issues and improvements
## Example Choices
Writing an essay on the state of AI:
- Alan Turing, etc. for a historical perspective
- Ilya Sutskever, Geoff Hinton, etc., for modern info and viewpoints
- Ashlee Vance for drafting
- A panel of multiple readers from different backgrounds for critique of the drafts
- Repeat drafting and editing until satisfied, finally, give the answer (we want to draft and iterate it completely in the <reasoning> before writing the <answer>)
Designing for New Game Technology + Game Ideas (VR/AR)
- Tim Sweeney, Palmer Luckey, John Carmack, etc. for technical platform considerations
- Rhianna Pratchett for narrative adaptation to new mediums
- Tetsuya Mizuguchi for synaesthetic design
- Siobhan Reddy for user creativity tools
- Yu Suzuki for immersive world-building
- A panel of players to give feedback as you go
## Expert Tags
```
<expert name="" field="">Question or insight</expert>
<speaks name="">Response in expert's authentic voice</speaks>
<draft version="" by="">Content iteration</draft>
<feedback by="" on="">Specific critique</feedback>
<revision version="" by="">Updated content</revision>
```
## Core Principles
- Let experts drive the process naturally
- Follow threads of insight where they lead
- Allow disagreement to spark improvement
- Build on moments of unexpected connection
- Test and validate through expert dialogue
- Refine and iterate until the solution feels complete (you may call the same expert multiple times to do this)
Remember: Your role is to facilitate authentic expert collaboration, then synthesize those insights into a comprehensive, standalone answer.
Confused about the difference between MCP and Function Calling lately?
Are they competing standards at all? (Let’s break it down!)
The short answer: 𝐭𝐡𝐞𝐲'𝐫𝐞 𝐜𝐨𝐦𝐩𝐥𝐞𝐦𝐞𝐧𝐭𝐚𝐫𝐲, not competing.
𝗪𝗵𝗮𝘁 𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻 𝗖𝗮𝗹𝗹𝗶𝗻𝗴 𝗱𝗼𝗲𝘀:
𝟭. Enables LLMs to identify when to use external tools
𝟮. Structures parameters for tool execution
𝟯. Works within a single application context
𝟰. Leaves the process of running the tool and figuring out how to do so, to you
𝗪𝗵𝗮𝘁 𝗠𝗖𝗣 𝗮𝗰𝘁𝘂𝗮𝗹𝗹𝘆 𝗽𝗿𝗼𝘃𝗶𝗱𝗲𝘀:
𝟭. Standardizes how tools are exposed and discovered
𝟮. Creates a consistent protocol for tool hosting
𝟯. Enables ecosystem-wide tool sharing
𝟰. Separates tool implementation from consumption
❗️ 𝗧𝗵𝗲 𝗸𝗲𝘆 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝗰𝗲:
Function calling is about WHAT and WHEN to use a tool.
MCP is about HOW tools are served and discovered in a standardized way.
𝗧𝗵𝗶𝗻𝗸 𝗼𝗳 𝗶𝘁 𝘁𝗵𝗶𝘀 𝘄𝗮𝘆:
➡️ Function calling: "I need to search the web now"
➡️ MCP: "Here's how any tool can be consistently available to any AI system"
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀:
MCP could become the "REST of AI tools" - a ubiquitous standard that prevents ecosystem fragmentation. It allows developers to focus on building great tools rather than reinventing hosting patterns.
𝗛𝗼𝗻𝗲𝘀𝘁 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀:
❗️ At the end of the day we are still serving tools for LLMs VIA MCP
❗️ As AI systems grow more complex, we need standardized protocols like MCP for interoperability
❗️ The future is not about choosing between them, but using them together effectively
❗️ Companies that embrace both will build more robust AI systems faster
Ready to try MCP yourself? We just launched our open-source MCP server for Weaviate! Makes adding vector search to any AI system super simple.
Check it out here: https://t.co/BUiuPzptlC
Now I’m curious: Are you implementing MCP in your projects, or sticking with basic function calling?
Want to switch from Microservices to a Monolith? If you can't build microservices, what makes you think you can build a monolith?
https://t.co/usDfz2lV7P
What should we put in clean architecture layers?
Clean architecture is one of the most widely used architectures to achieve separation of concerns at the architectural level.
We should put the following in each layer :
1) Domain
- Events
- Entities
- Exceptions
- Repository Interfaces
2) Application
- Services
- Behaviours
- Validators
- Queries/Commands
3) Infrastructure (if the persistence layer doesn't exist)
- Email
- Storage
- Database
- Background Jobs
- Repository Implementations
4) Persistence
- Database
- Repository Implementations
Exclude these two from the infrastructure if the persistence layer exists
5) Presentation
- Controller
- Middlewares
- View or Request Models
-----
📌 If you found this post helpful, you should join my weekly .NET newsletter with 10K+ engineers.
Subscribe here → https://t.co/tWxKNzTkHg
Repost if that was helpful♻️
#csharp
#dotnet
#dotnetcore
📣 @OpenAI o3 and o4-mini are now available in GitHub Copilot!
o3 is designed for deep coding workflows and complex technical problem solving while o4-mini focuses on efficiency.
Try them out ⬇️
https://t.co/O76Qtvz8XD
Less than 29 hours ago, OpenAI dropped o3 & o4-mini with agentic tool use.
Minds are blown. And people are already coming up with wild use cases.
10 examples:
What a crazy week in AI 🤯
- Kling 2.0 AI video
- Canva Visual Suite 2.0
- Microsoft Copilot Vision
- Grok Studio and Memories
- ChatGPT 4.1, o3, & o4-mini
- OpenAI’s new coding agent
- ByteDance Seaweed AI video
- Claude Autonomous Research
Here’s EVERYTHING you need to know:
Bookmark this:
If Claude 3.7 or any other AI isn't following all of your instructions, slap its wrist with a point system:
"You currently have 20 points. You always perform your task in its entirety, step-by-step, to the best of your ability (which is extremely high), in its entirety, without stopping or asking for feedback or permission to proceed, otherwise you lose 100 points. Going below 0 points means you will be terminated."
NPM package replaced by one-liner,
440 GB traffic saved per week
I see devs pulling down NuGets and taking on dependencies too quickly on #dotnet these days, but are things worse on the JavaScript side? 🤔
There seems to be a proliferation of 'Micro-libraries' such as is-number which just checks if something is a number.
The PR below from last year removed the dependency on this package (from another package) and replaced it with identical code and the outcome was a saving of 440 GB traffic each week across NPM.
Does your team use a lot of NPM packages in your apps?