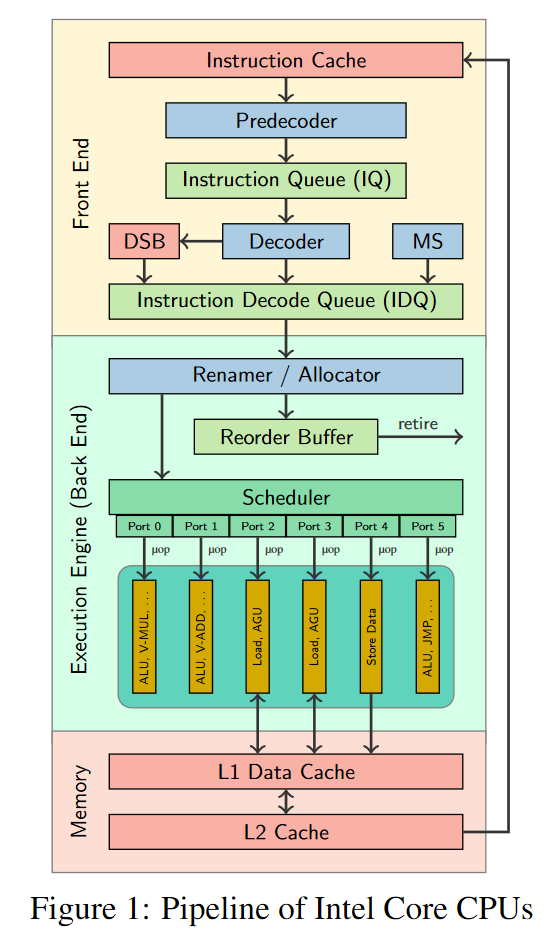
Researchers have developed a new simulator to predict the throughput of basic blocks of all Intel Core μarchs released in the last decade, demonstrating to be more accurate than the predictions of state-of-the-art tools by more than an order of magnitude.
https://t.co/83UDBQSchX
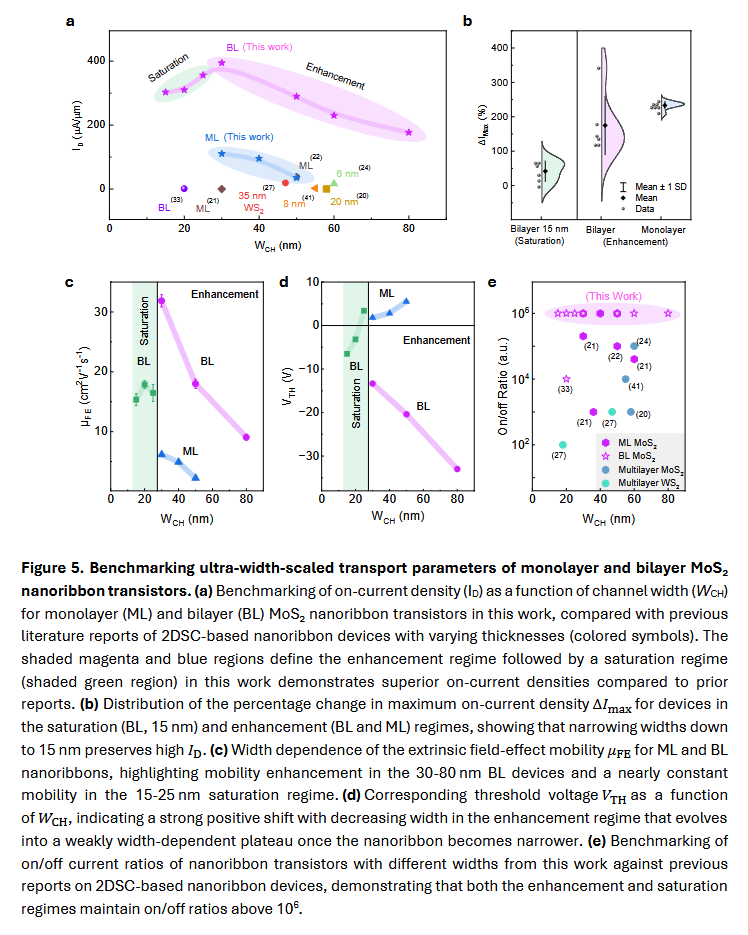
These findings represent a masive breakthrough in width-scaling rules using 2D nanoribbon transistors with enhanced performance at narrower channel widths, which is promising for the ultimate scaling of transistors.
In this paper, researchers have demonstrated atomically thin monolayer and bilayer molybdenum disulfide nanoribbon transistors that break the width-scaling wall down to 15 nm.
https://t.co/l0pKVk1LpD
The ultra-narrow nanoribbon transistors maintain the highest on/off ratios reported so far (10^6) for similar device dimensions, with improved mobility and threshold-voltage stability, indicating reduced edge scattering and depletion, along with stronger electrostatic control.
The results show that CRAM-ER presents near-lossless accuracy with 10× better energy efficiency and a 2× improvement in EDP over the A100 GPU. Furthermore, CRAM-ER achieves up to 70× higher energy efficiency than CPUs and GPUs while reaching near-HBM2 throughput.
In this paper, researchers proposed an error-resilient CRAM architecture for scalable in-memory matrix-vector multiplications, mitigating the impact of device-level errors and demonstrating high area and energy efficiency.
https://t.co/WKAgJYR5vw
The proposed architecture enables parallel in-situ multiplications and error-resilient additions. Partitioning MACs between CMOS and MRAM at the bit level provides an optimal trade-off between area overhead and processing efficiency.
In this paper, researchers have demonstrated that an off-the-shelf open-weight LLM, quantized to fit on a single GPU, suffices to drive a worm AI agent that gains privileged access to machines and replicates itself. #DeepLearning
https://t.co/1fQ7AMvbwY
Researchers have proposed a bounded GPU-aware wait-free queue with explicit theorem-grounded progress guarantees, and a bounded GPU lock-free queue design that uses wave-batched fast paths to maximize throughput.
https://t.co/VzCi2eUvC1
In this paper is presented a review on the recent progress in quantum-hardware-based simulations of condensed matter, primarily emphasizing gate-based digital quantum computer simulation, with analog experiments discussed as complementary benchmarks.
https://t.co/KfcEHc8UVY
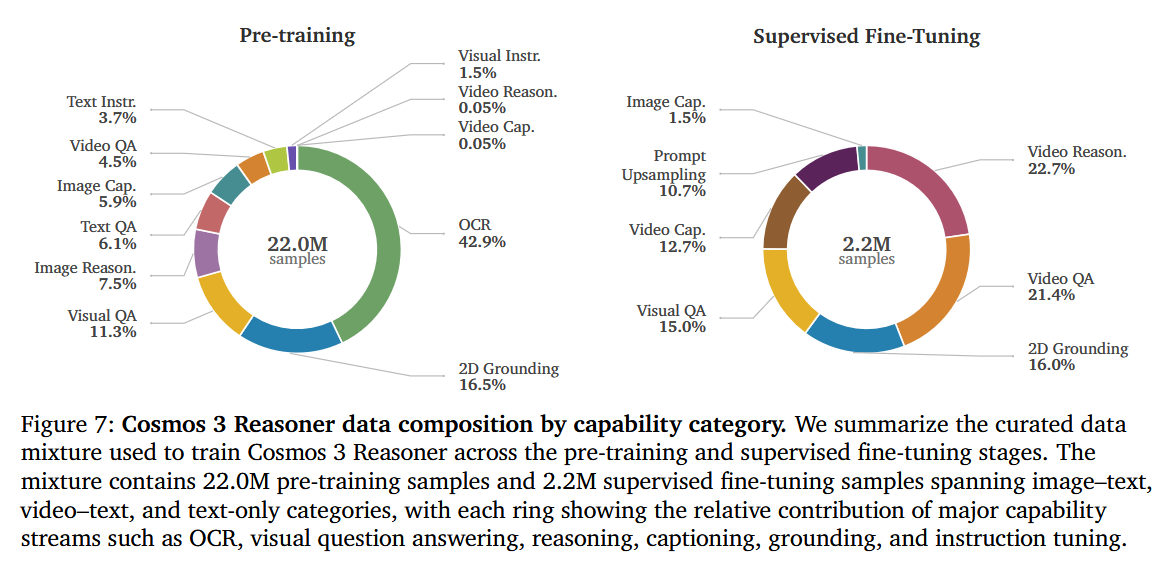
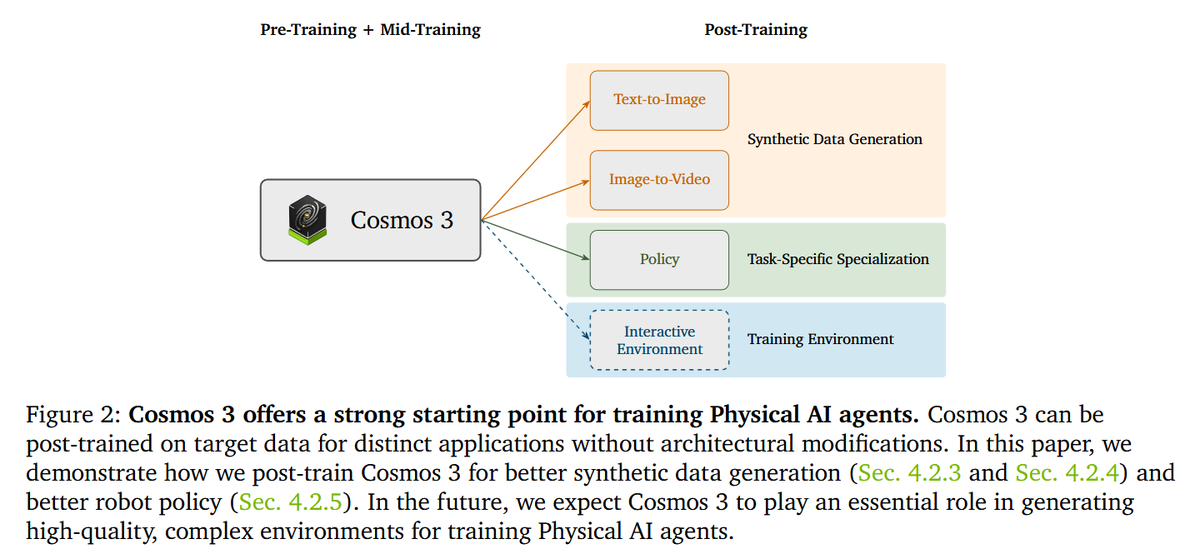
This unified formulation is enabled by modality-specific encoders, structured token arrangements, and a Mixture-of-Transformers backbone that couples autoregressive reasoning with diffusion-based generation.
Finally, Nvidia have introduced Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture.
https://t.co/AhC5lE3Xkx
Moreover, because the worm requires no commercial AI platform, centralized safety controls, such as service refusals or rate limiting, are structurally irrelevant. This results demonstrate that self-sustaining AI-driven cyber-threats are no longer theoretical.
In this paper, researchers have demonstrated that an off-the-shelf open-weight LLM, quantized to fit on a single GPU, suffices to drive a worm AI agent that gains privileged access to machines and replicates itself. #DeepLearning
https://t.co/1fQ7AMvbwY
Since the worm is powered by stolen compute, the attacker’s marginal cost per new infection is zero. This creates a destabilizing economic asymmetry between attackers and defenders.
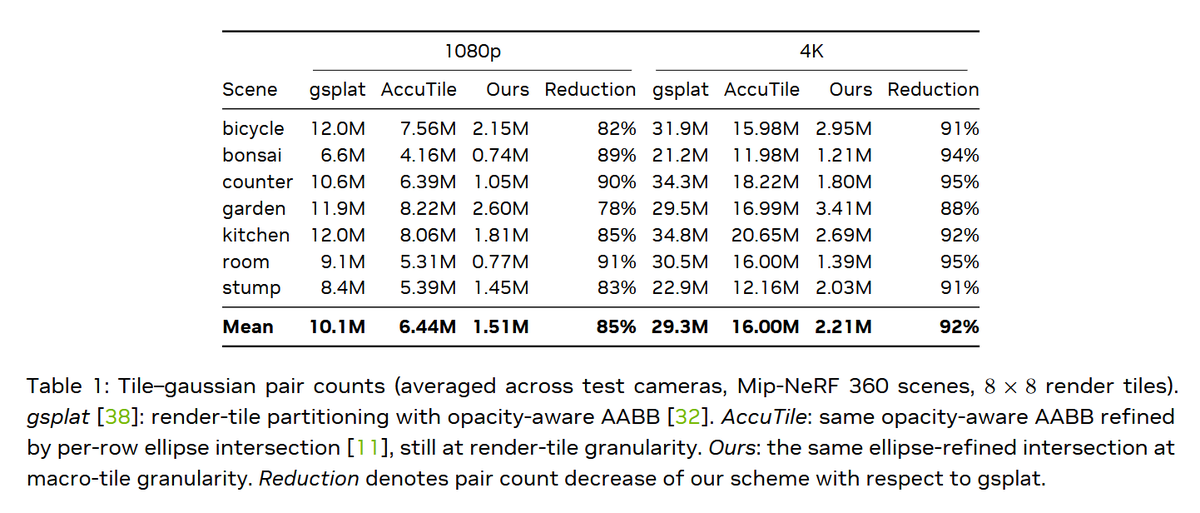
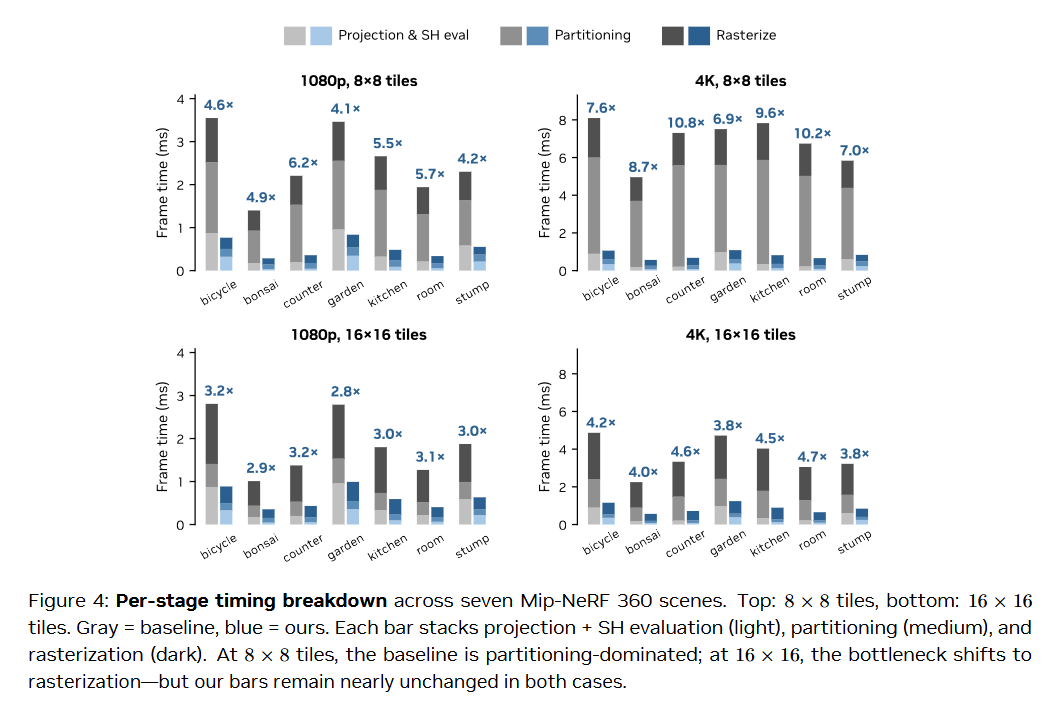
The results show that HiGS renders up to ∼15.8× faster than the original 3DGS and outperforms every other rasterizer evaluated, while preserving exact front-to-back alpha compositing.
In this paper, NVIDIA researchers have proposed Hierarchically Tiled Gaussian Splatting (HiGS), a 3D Gaussian Splatting rendering architecture in which spatial partitioning and rasterization operate at different granularities.
https://t.co/nKtdNCLC9e
This reshapes work decomposition from screen-area proportional to density proportional and eliminates the rasterizer tail effect inherent in single-tile-size pipelines.
"G-LFQ achieved the highest peak throughput in several settings, while G-WFQ was the most robust across architectures and workload mixes, sustaining performance under contention and degrading more gracefully at high thread counts."
Researchers have proposed a bounded GPU-aware wait-free queue with explicit theorem-grounded progress guarantees, and a bounded GPU lock-free queue design that uses wave-batched fast paths to maximize throughput.
https://t.co/VzCi2eUvC1
The results across fixed-duration microbenchmarks on MI210 and MI300A, the bounded ring designs delivered the strongest overall performance and efficiency.