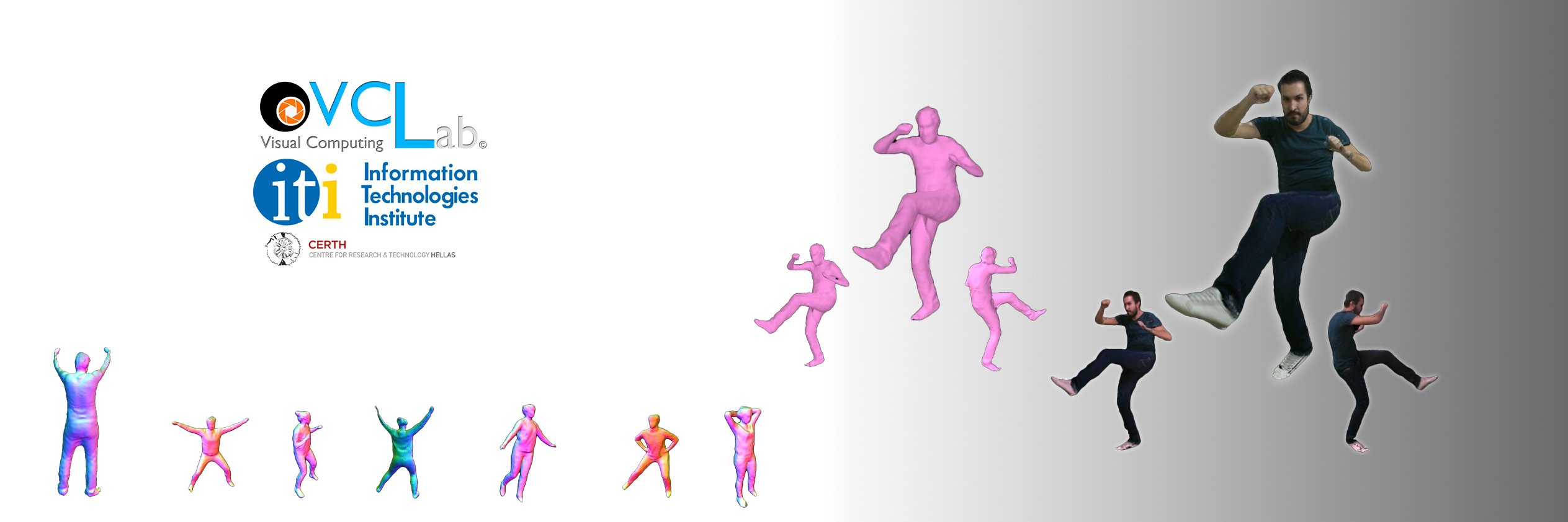We are happy to announce the release of our synthetic metric-grounded dataset for spatially-aware image captioning. Additionally, we provide multiple distribution-shifted splits, enabling further study of the domain in a controlled environment. #VOXReality
https://t.co/Hh94Ev2sNV
Did you ever wonder how conferences will be held in the future? Join the #VOXReality interactive #webinar to experience frist-hand the future of social #VR. Register now: https://t.co/oNtvjTogJq
#VOXReality second round of AR-Theatre use case’s pilot is being held with great success! Backbone #AI services function flawlessly, silently triggering #AR visual effects when specific events are happening on-stage. E.g. an effect is set to trigger when an actor is going down.
Proud to have been part of the #VOXReality VR Conferences immersive experience. Thank you #VRDays for your vision, support and fellowship throughout this endeavour.
As part of #VOXReality, we are excited to invite you in our #webinar on June 19. Each session will last 60 min. and you will experience (no #VR headset required) interaction inside a VR-world conference simulation. We will be glad to hear your feedback: https://t.co/4QFBNATT1N
Excited to share our latest contributions: a) a novel metric designed to evaluate spatial understanding in image captioning, and b) an SVD-based method for diminishing large transformer-based #AI models. Stay tuned for eminent #VOXReality publication releases!
After 30 months of collaboration, innovation, and research, the LAGO project is coming to a close, but its legacy will continue to shape the future of FCT research in law enforcement across Europe.
Watch our new video to see how we tackled the sector’s most pressing challenges.
The SEEDS project aims to revitalize ancient grains to enhance cereal supply chain resilience in the Mediterranean region, particularly in Tunisia, Egypt, Morocco, and Jordan.
https://t.co/HK3IW33n5z
The power of pretraining in non typical use cases: A BLIP VL-VQA model pretrained on a generic object dataset, when finetuned for only 2 epochs on a visual navigation task achieves similar performance with an 18 epochs randomly-initialized training on the same data. #VOXReality
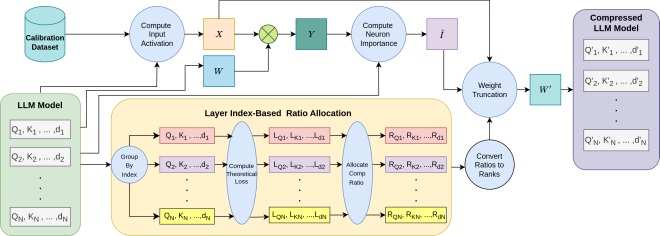
Discover the advantages of Fisher-Weighted SVD for Neural Network Compression. Excited to explore the concept for Vision-Language models. #VOXReality#HorizonEurope [https://t.co/1tqSwqkM3p]
With our #VOXReality Open Call child-project #CrossSense, we continue aiming high towards the broader adoption of #AR devices for the early-treatment of MCI. Watch this 2min interview for more: https://t.co/dxosv26ivZ
🚀 The VCL team is thrilled to be at #ECCV2024! We’re presenting our latest advancements in #FederatedLearning and image classification, pushing the boundaries of privacy-preserving AI. Join us to discover the future of secure and scalable #AI! #ComputerVision#Research#VCL
#VOXReality and #CERTH are excited to welcome #Animorph and the #CrossSense project aboard. Serving proven memory-boosting practices through powerful #AI-driven #AR has the potential to greatly improve million lives of people with mild to moderate cognitive impairment. Stay tuned
Close to the release of our #COCO dataset's extension to the spatial-relashionship domain. Each image is accompanied with a set of spatially descriptive captions, questions and answers, useful in training spatially-aware #AI. Stay tuned with #VOXReality#HorizonEurope#EU project