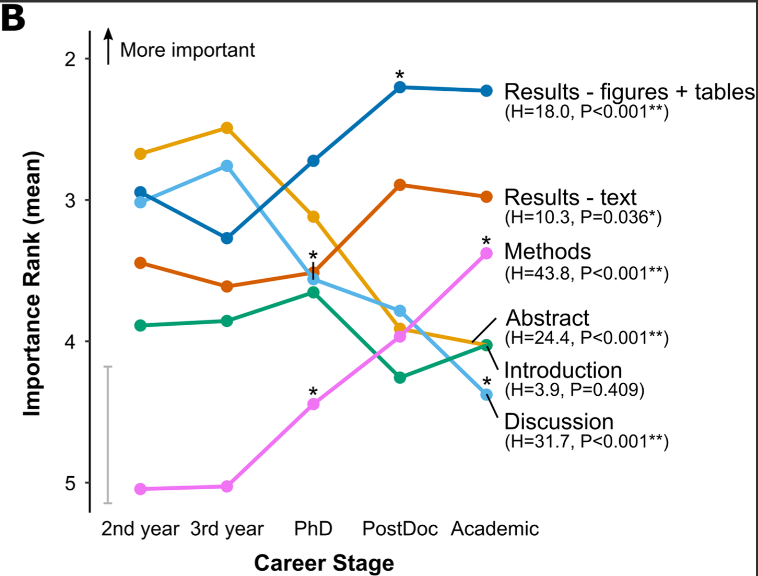
The longer people are in academia, the more they realize that when reading papers it's best to ignore Intro, Discussion etc. and just look at Methods and Results
https://t.co/EzQL7WI71Q
I hit a bug in the Attention formula that’s been overlooked for 8+ years. All Transformer models (GPT, LLaMA, etc) are affected.
Researchers isolated the bug last month – but they missed a simple solution…
Why LLM designers should stop using Softmax 👇
https://t.co/3TqSo13RKN
Have you ever wondered how we can salvage federated learning?
27 March at 11:15am GMT, @realhamed will utilize Trusted Execution Environments on clients for local training, and on servers for secure aggregation, to hide model updates from adversaries.
#EarComp is back at @ubicomp 2022! We’re so excited to announce the Call for Papers for the 3rd edition of the workshop on Earable Computing!🎧🦻Check out the call at: https://t.co/vzMcel0rBO #earable#ubicomp2022
Too many attacks breaking the privacy-by-design principle in federated/collaborative learning? All-in-One. Check out our paper analyzing the private information leakage from neural network gradients using information theory. https://t.co/z65av7ePwd