I will be presenting BeyondObjects this week at #CVPR2026. Come check out our poster on Thursday 4:30-5:30pm at the syndata4cv workshop (Room 607) or Saturday 4:45-6:45pm at ExHall A & F poster location 99. Happy to chat!
Happy to share that our paper “Motion Attribution for Video Generation” has been accepted to #ICML2026 as a Spotlight (top 2.2%) 🎉
https://t.co/TbKXjQMfe9
TL;DR: We introduce MOTIVE, a scalable, motion-centric data attribution framework for video generation that identifies which training clips improve or degrade motion dynamics, enabling better data curation and beyond.
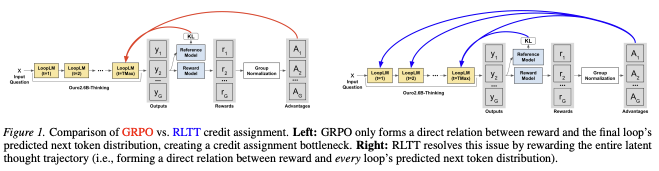
Excited to share that RLTT has been accepted to #ICML2026! Looking forward to connecting with others working on Looped Transformers/Latent Reasoning/Mathematical Reasoning in Seoul🇰🇷!
Honored to receive the Best Paper Award at the Test-Time Updates Workshop @ ICLR 2026 🏆
Huge thanks to coauthors and workshop organizers!
https://t.co/585kRh5NzF
Honored to receive the 2026 Apple Scholars in AIML PhD fellowship! 🍎
Extremely grateful to my advisor @orussakovsky and all the incredible mentors, collaborators and friends I’ve had throughout the journey. Excited to push toward more scalable and capable multimodal system!
https://t.co/WhGTaD2PDa
We'll be presenting this work on video-text alignment this week at #ICLR2026!
Come check out our poster in Pavillion 4 #3405 in the Thursday AM session from 10:30am to 1pm. Happy to chat about PRH, repr learning, video understanding, or how vision plays into text models!
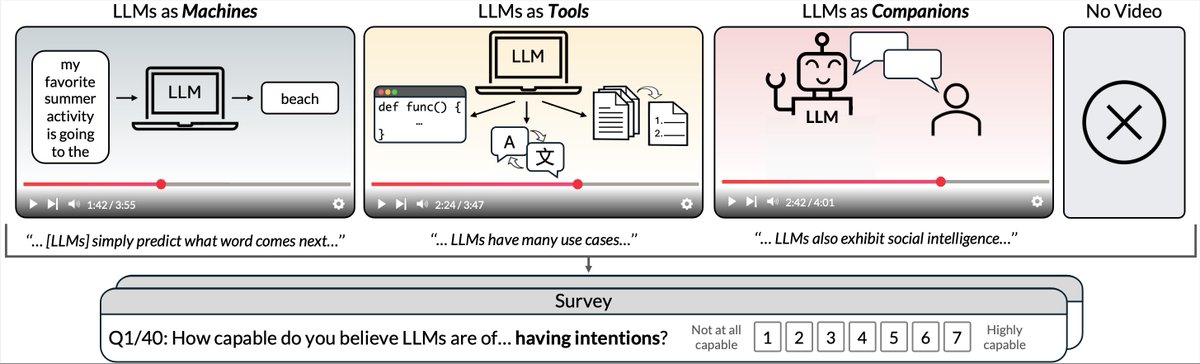
How should we talk about LLMs? Does it matter if we frame them as a machines 📠, tools ⚒️, or companions 👥? In our #CHI2026 paper, that these framings can alter what people believe about LLMs and how they use them. See 🧵for more!
Video models surprisingly can solve mazes, but inconsistently. We understand little about how they reason, making it hard to use such abilities.
We investigate the denoising process and find models commit to a plan early, letting us screen far more candidates for better perf.
🧵
In our latest blog, @YangWilliam_ and his collaborators present BeyondObjects (BOB): a new method that improves image classification by generating more diverse, context-aware synthetic training data: https://t.co/eOrc8Vp2pi
Fast weights were built for long term memory, but trained for short attention spans.
We introduce ReFINE, a phase-agnostic RL framework that improves long-context modeling in fast weight architectures.
https://t.co/ifXQVKdKKy
1/8
Fast-weight models need sequence-level supervision for long-context modeling. We study how to supervise learned compression in fast-weight models via RL.
Key ideas:
- Train fast-weight models with next-sequence prediction instead of next-token prediction.
- RL rewards that evaluate whether compressed context supports coherent multi-step generation.
Paper: https://t.co/69Lq4sUjGI
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 https://t.co/TbKXjQMN3H
1/10
Most LLM evals use API calls or offline inference, testing models in a memory-less silo. Our new Patterns paper shows this misses how LLMs actually behave in real user interfaces, where personalization and interaction history shape responses: https://t.co/Cd9Rq2yIhH
Huge thanks to the organizers of NeurIPS CDMX for a fantastic week (also with great weather and food)!
First conference trip as an assistant professor, and everything has been smooth and very enjoyable. The smaller venue made it easier to have in-depth conversations than in my past conference experiences. The only slightly awkward part was the second poster session running until 9:30 pm local time to stay in sync with the main conference in San Diego, but overall it’s been an amazing experience!!
#NeurIPS2025 #Mexico
I’m at #NeurIPS2025 from 12.2–12.7!
I work on data-centric Video Generation and VLMs/VLAs recently (MOTIVE, COMPACT, ICONS, etc.), and I’m generally interested in building more scalable and capable multimodal systems.
DMs open for a coffee chat! 😃 Excited to meet old and new friends!