When we started on the Argonaut journey, we got 1-2 friendly customers while building out the MVP. But then, we stopped selling.
I was delaying launching with reasons like “we don’t have self-serve yet” or “this feature will make for a nice launch”. It took a while to come to terms with it, but it was fear of rejection for someone trying to sell something for the first time.
We are doing things very differently this time around, and learning from previous mistakes.
✅ Picked a problem that is narrow, and the value proposition can be conveyed in one sentence.
✅ Put up a website and a waitlist before development to gauge interest.
✅ Continuously selling - everywhere, all the time.
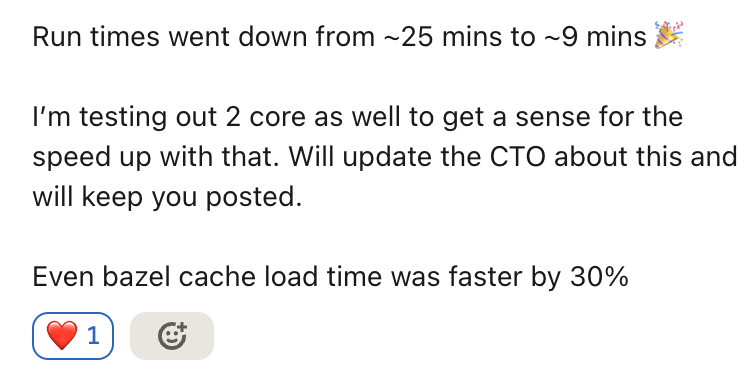
Everybody wants builds to be faster. Everyone wants costs to go down. The value couldn’t be clearer and we are seeing fantastic results.
Earlier today, a customer got setup within ~2 minutes and this is what they had to say.
I think we are onto something here 🔥
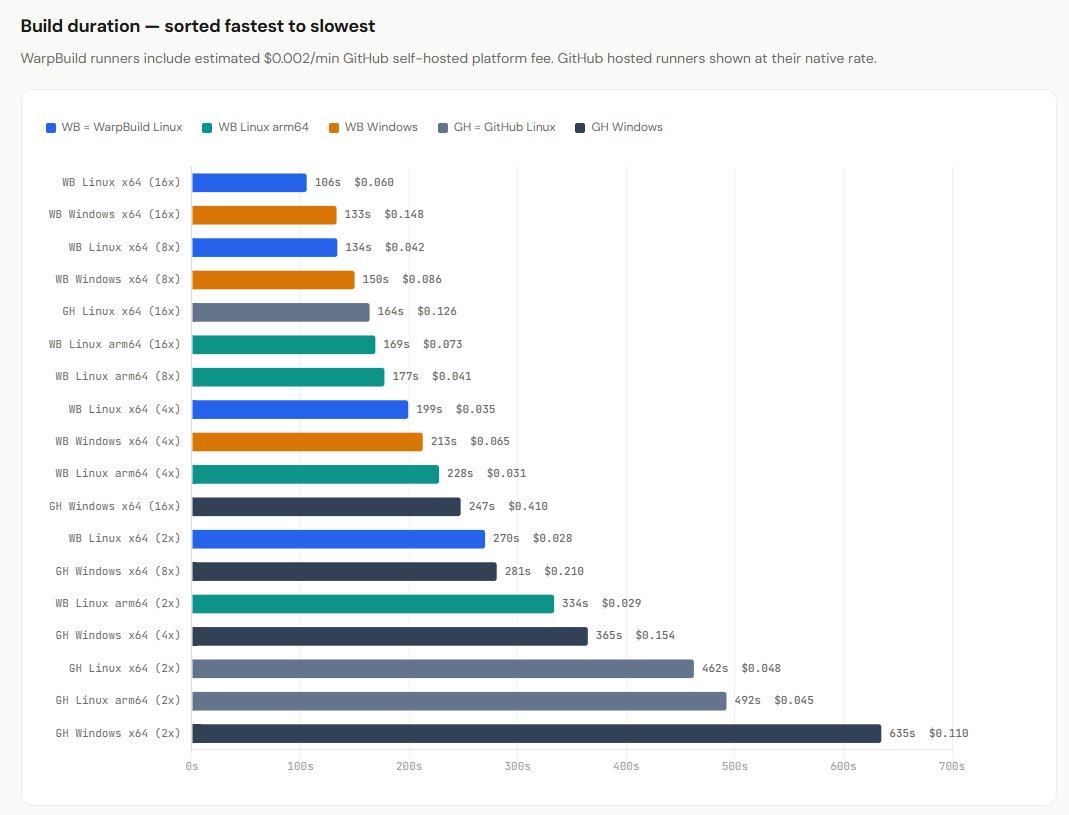
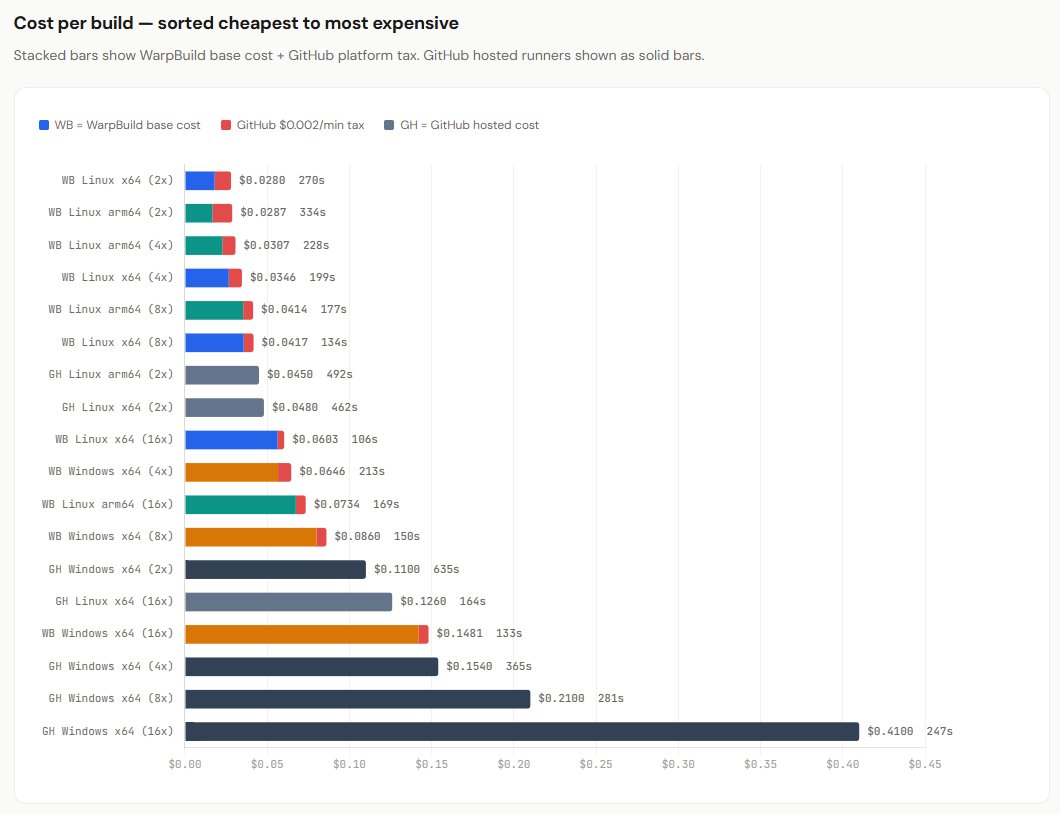
So I made a GitHub Actions workflow to compare 18 runner configurations to build RDM Windows from Windows or Linux, using GitHub runners and @WarpBuilds runners, and then graphed the results using Claude. Even with a future $0.002/min tax for self-hosted runners, it's worth it!👇
I've started testing @WarpBuilds custom GitHub Actions runners, and the first thing that stood out for me is that there's observability into runner resource consumption with recommendations. It's mind-boggling that GitHub doesn't have that, I've wanted this since forever
@WarpBuilds users using BYOC on GCP can now control the IOPS and throughput allocated to runner disks (we've supported this on AWS for a a while now).
It was fantastic to see this message from a user who noticed this and took the time to drop a message to us even before we could update the changelog.
We're hiring to accelerate our growth and build more such delightful capabilities for our users.
https://t.co/zuh7moPcvm
https://t.co/9NUwDc30Yc
⏰ BuildJet is shutting down on 31st March.
WarpBuild is the obvious choice to migrate to, because:
1. WarpBuild runners are faster for x86-64 and arm64 workloads.
2. WarpBuild has the broadest range of OSes and architectures supported (including Windows and MacOS)
3. WarpBuild has the most deployment modes , including Bring-Your-Own-Cloud on AWS, GCP, and Azure.
Switch now for faster and cheaper builds.
Here is the prompt you can provide to your favorite coding agent to make the switch:
```
Migrate runners from BuildJet to WarpBuild. The configuration for the WarpBuild runners can be found here: https://t.co/B7rb1GMGLG
```
We are the only GitHub actions runner infrastructure provider to support this feature: Snapshots.
Each CI job runs in its own ephemeral VM for isolation and reproducibility reasons. However, a significant portion of time in each job is spent on tasks that are repeated often. These are tasks like setting up dependencies, downloading artifacts that seldom change, etc.
WarpBuild's snapshots capture the full state of the VM at any point in the job's lifecycle and use that as the base for subsequent jobs. This has enormous potential because it can even cache things like partial compilations, test suites, etc. with zero effort by users.
One of our customers wrote a blog post about how they use WarpBuild snapshots in their CI to cut run times by 60-80% and save 24 minutes of CI time per commit.
Truly grateful to have fantastic customers like Andrew Berry. Read his article here: https://t.co/yVuoAPQSJZ
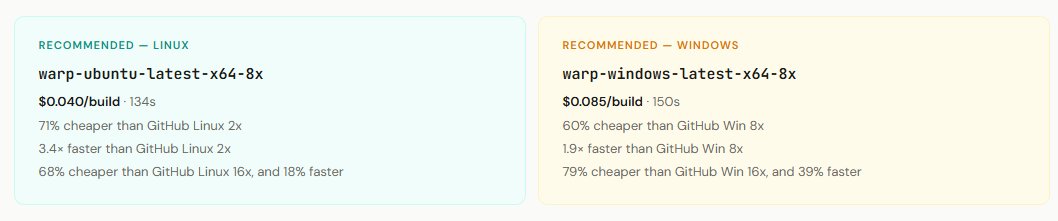
tldr: We provide github actions runner compute. Our compute is still cheaper than using github hosted runners (even with the $0.002/min tax) and our runners are optimized for high performance to minimize the number of mins consumed.
Here are the practical implications and considerations to optimize for cost, given the new pricing. These are generic and ensure you think through your workflows and runners before making any changes.
1. Self-hosting runners is still cheaper than not Despite the $0.002/minute self-hosted runner tax, self-hosting runners on your cloud (aws/gcp/azure/...) remains the cheaper option.
2. Prefer larger runners If your workflow scales with the number of vCPUs, prefer larger runners. That ensures you spend fewer minutes on the runner, which reduces the GitHub self-hosted runner tax.
For example, using actions-runner-controller with heavy jobs running on 1 vcpu runners is not a good idea. Instead, prefer a 2vcpu runner (say) if it runs the job ~2x faster.
3. Prefer faster runners All else being equal, prefer faster runners. That ensures you spend fewer minutes on the runner, which reduces the GitHub self-hosted runner tax.
For example, if you're self-hosting on aws and using a t3g.medium runner, it's better to use a t4g.medium runner since the newer generation is faster, but not much more expensive.
4. Prefer fewer shards If you have a lot of shards for your jobs (example: tests on ~50 shards), consider reducing the number of shards and parallelizing the tests on fewer but larger runners.
5. Improve job performance This is not new advice, but it's now more important than ever because of the additional GitHub self-hosted runner tax.
6. Use GitHub hosted runners for very short jobs For linters and other very short jobs, it's better to use GitHub hosted runners.
Today, GitHub announced a change to their pricing model aimed at monetizing self-hosted runners.
They've also reduced the pricing for their first party hosted runners.
Here's what it means for our users:
https://t.co/NbtdAdEdQw
You can view GitHub actions runner logs, the VM syslogs, and the system metrics correlated with the logs in one place.
The new observability features are very useful for debugging.
For high-uptime GitHub actions runner infra that is 2x faster and half the cost, use @WarpBuilds.
Infra is hard but we take uptime very seriously, especially for the core offering of GitHub actions runners.
We manage this through a combination of bare-metal instances that we manage, and multiple backup infra stacks to failover to.
Cargo-culting complex observability stacks is dumb.
We did something wacky for the architecture of the new GitHub actions runner observability feature we launched recently - we simplified it until it can't get any simpler.
Our users wanted a feature where they could see the CPU, disk, network related metrics so that they could right-size their GitHub actions runners.
This system at 1 million jobs/day generates ~1TB of metrics and logs **every day**.
The textbook approach would have been to do something like this:
1️⃣ Collector (with chunker)
2️⃣ Gateway / Aggregator
3️⃣ Storage - timeseries DB like prometheus, or clickhouse
4️⃣ Query service
However, our requirements are simple (no aggregations, bounded data sizes, no realtime requirements), and that meant we could simplify our systems for zero maintenance while providing the best UX.
📤 Ingestion path:
- An otel collector on the runner for collecting metrics.
- A proxy on the runner to request a presigned s3 url for uploading metrics and logs securely.
🖥️ Retrieval:
- UI requests presigned urls for fetching the data from s3.
- The browser directly fetches the data in relevant chunks and displays it.
🚨Hiring alert!
If you are a fullstack engineer interested in working on fantastic engineering challenges @WarpBuilds, I'd love to chat.
Re-share for karma :-)