Learning Web3 from scratch and sharing it with the community. I help projects scale, manage engaged communities, and serve as a Web3 ambassador. Every day I build, teach, and provide insights to empower people and projects in the decentralized space.
If ChatGPT, Siri, or any voice assistant spoke your native dialect perfectly, how often would you use it?
This is why speech data matters.
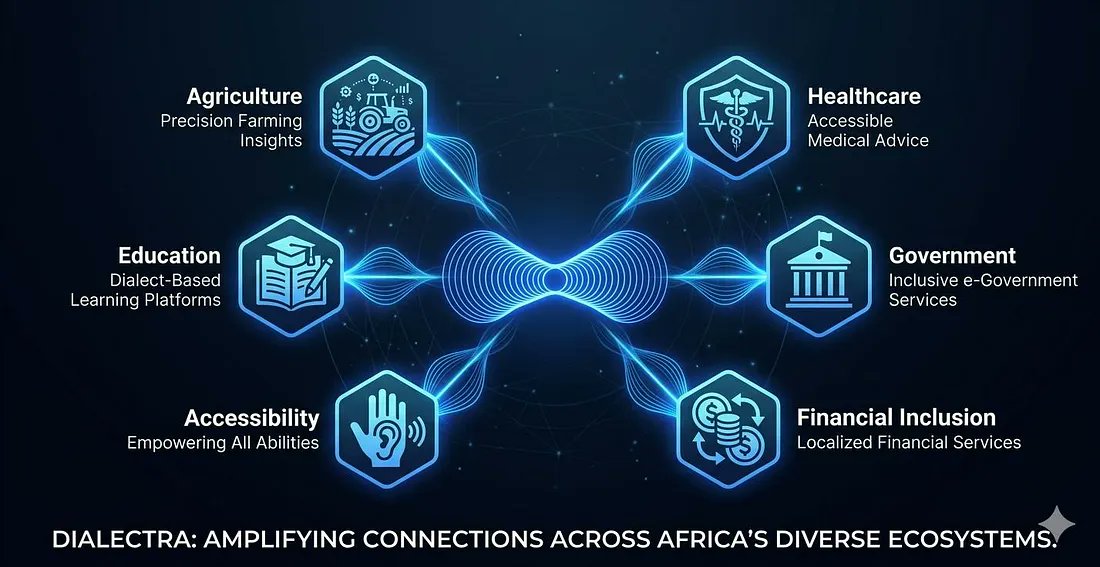
African languages deserve the same AI experience as the world's most represented languages.
That's why @_dialectra is here
@UmarMuazuNgw@_dialectra Data sets is what matters more when it comes to building any kind of AI model. Imagine an AI train with a corrupted data sets. It's response will look awkward and unjustified. The maths is simple: Pure data sets is surely a lead to a better response.
@_dialectra is here to stay
Everyone talks about AI models.
Few people talk about the data infrastructure behind them.
Without quality speech data, AI can't properly understand, transcribe, or generate African languages.
That's why @_dialectra is building the foundation layer:
🎙️ Speech collection
✅ Data validation
🌍 African language representation
The future of African Voice AI starts with the data.
Yesterday i was debugging dropped calls and backend issues on Dialect Connect on @_dialectra
Today I’m signing incorporation documents for the same company we started with almost nothing as a experiments.
Bootstrap founders will understand this feeling.
No big funding announcement, no fancy office, just pressure, sleepless nights, constant problems, and still showing up to build every day despite not being able to stand up or walking due to my recent accident.
Still pushing https://t.co/eCLj0KHPQu forward.
AI runs on data.
Yet thousands of languages remain invisible to modern AI, while the people creating valuable language data rarely benefit from it.
@_Dialectra is changing that by enabling communities to preserve, verify, and contribute language data to the AI economy.