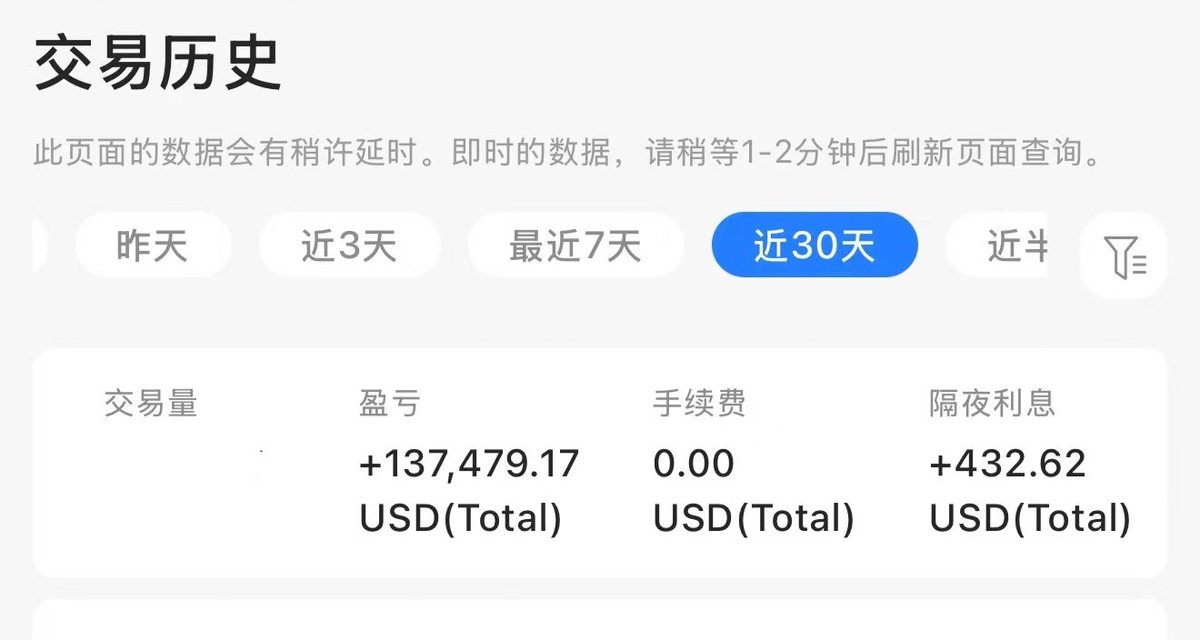
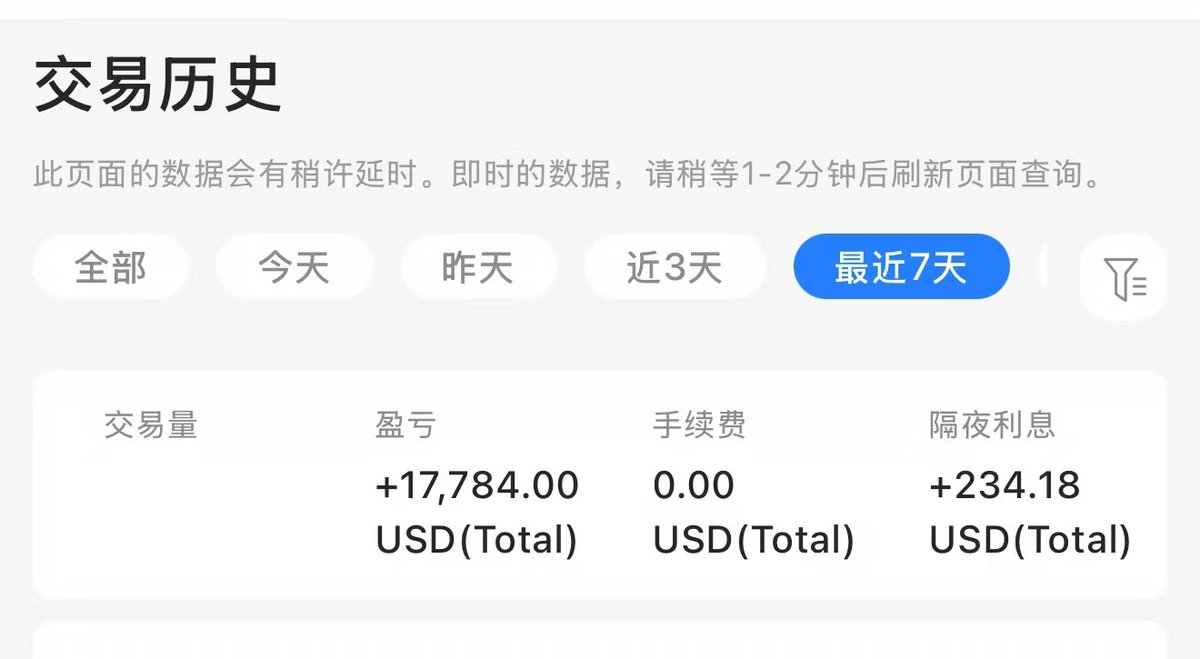
Flow policies are getting popular in robotics as they capture multimodal prior data well, and synergize nicely with action chunking. But it is unclear how to best train them with RL effectively.
We found something that works pretty well! (spoiler: use Adjoint Matching) 🧵1/N