🎤#NeurIPS2024 Oral🎤
Did you know that generative modeling and imitation learning are actually the same problem?
In our paper, we reimagine diffusion modeling through the lens of imitation learning!
https://t.co/aDZDTjHP0D
1/ 🚀 New work: GDSD
Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
RL for diffusion LLMs based on approximate likelihood faces a key problem:
training–inference mismatch (TIM).
We propose GDSD to address it by reformulating RL as denoiser self-distillation.
🌐https://t.co/CTkjVtohAp
Hiring 2 summer ML research interns at the University of Basel 🇨🇭.
Research topics: RL/diffusion LLM post-training, reasoning, or LLM orchestration. Possible fully funded PhD offers to follow.
I'll be at ICLR this week and happy to chat.
Apply: https://t.co/gOdLRv771L
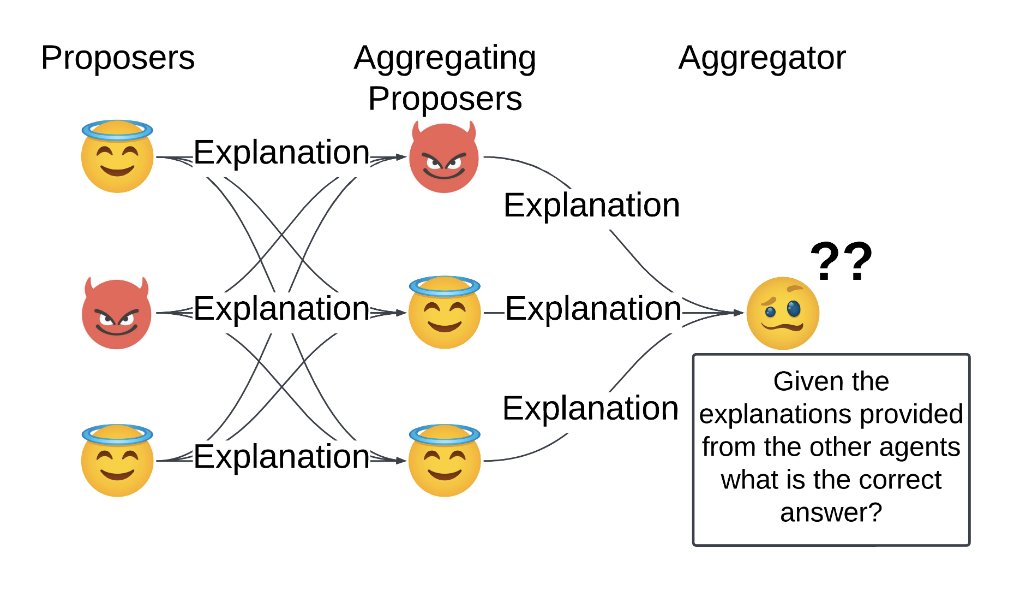
Watching the Moltbot hype and thinking about our paper: We showed a single deceptive LLM in a Mixture of Agents can nullify all the gains from collaboration.
Venetians spent centuries building layered councils to elect their Doge and still got corrupted from within. Same vibes. Robustness of multi-agent AI is wide open!
https://t.co/lA5ksthvYx
🚨 New paper alert 🚨
Excited to share our latest work:
“Multi-Task GRPO: Reliable LLM Reasoning Across Tasks”
📄 https://t.co/VbKlqOSam4
RL improves reasoning — but often breaks multi-task reliability.
We identify two failure modes — and propose MT-GRPO to fix them 🔥
🧵[1/N]👇
🚀 We are hiring!
Fully funded PhD positions @ Rhine-AI Group (University of Basel). Focusing on RL for LLMs, diffusion-based reasoning, and agentic AI.
Please RT!
Deadline approaching: December 1, 2025. Don't forget to apply!
Apply: https://t.co/JN9tia0Kkl
🎮 How can agents learn to generalize from limited offline data?
We introduce iMac (Imagined Autocurricula) - training agents entirely in world models with emergent curricula!
Our new Rhine-AI lab is officially open at the University of Basel!
We're currently recruiting for multiple PhD positions. If you're interested, you can register your interest on our new website, application links will be available soon: https://t.co/Nq5vazMxll
@JCJesseLai Amazing! I also got the seminar announcement email, but am so sorry that I cannot make it as I am in London :( hope you have a great time in Korea!
Super excited that the work I completed as part of a team at @LASRlabs won 1 of 2 Outstanding Paper Awards at the @ActInterp workshop at ICML 2025. Massive thanks to @Arrrlex for presenting our work!
📖Check out the paper here: https://t.co/9R6H4EgaMC
I'm excited to share that I will be joining the Graduate School of Artificial Intelligence at UNIST as an Assistant Professor starting in 2026! I will continue working on the intersection between generative modeling and reinforcement learning.
🧶1/ Diffusion-based LLMs (dLLMs) are fast & promising—but hard to fine-tune with RL. Why? Because their likelihoods are intractable, making common RL (like GRPO) inefficient & biased.
💡We present a novel method 𝐰𝐝𝟏, that mitigates these headaches. Let’s break it down.👇
Glad to introduce our new work "Game-Theoretic Regularized Self-Play Alignment of Large Language Models". https://t.co/6cLCrHwQfA 🎉
We introduce RSPO, a general, provably convergent framework to bring different regularization strategies into self-play alignment. 🧵👇
I had the great pleasure of visiting Heidelberg University to give a talk at the Institute for Theoretical Physics after two years! I am always impressed by how particle physicists stay up to date with the latest advances in ML. A huge thanks to Tilman Plehn for the invitation!
📖 Check out our latest work - using test-time scaling to do robust alignment across multiple different objectives.
🖥️ Interested in trying some of these approaches? Check out our code base where we provide implementations for our approach and the various baselines we tested it against: https://t.co/XxZrSNTLa6
🙏Massive thanks to @seongho_son_ml@WoongSSang@shyam91019594@ilijabogunovic@xiaohang_tang for collaborating on this work!
#LLMs #MachineLearning
❓No clue about the priorities of the objectives?
❗️ Focus on robustness at test-time!
🚀Robust Multi-Objective Decoding (RMOD) is a novel inference-time alignment algorithm that produces robust responses under multiple objectives to consider.