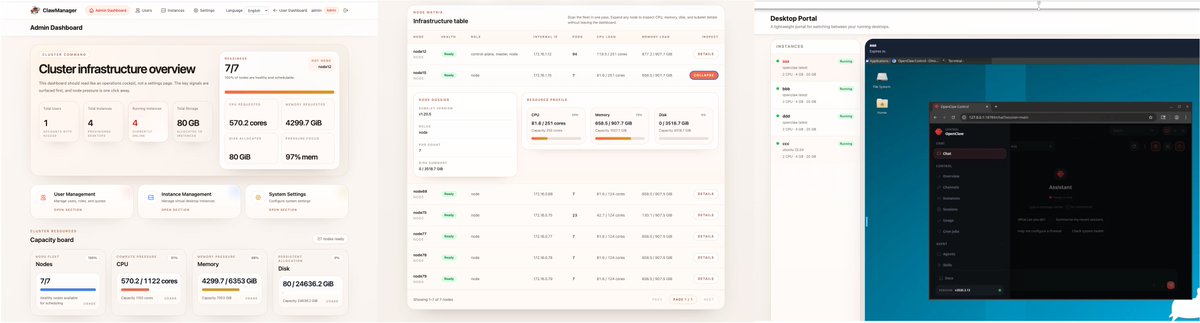
🤖ClawManager v2026.4.28 is now officially available, marking its evolution into a unified control plane for diverse agent runtimes. This release directly addresses the governance fragmentation that enterprises encounter in scaling AI agent deployments.
🔗ClawManager provides a unified interface for both OpenClaw, optimized for short-cycle tasks, and Hermes, designed for long-running persistent workloads. Users can configure models, connect channels, distribute skills, manage instances, and migrate workspaces within one interface—eliminating the need to switch across disparate systems.
🛡️Hermes automatically inherits existing security boundaries and permission frameworks upon onboarding, including environment isolation, skill supply chain governance, and prompt injection protection, without separate configuration.
⚙️This version also resolves network policy isolation and communication issues, while defaulting image pull policies to IfNotPresent. This effectively mitigates deployment failures in private or air-gapped environments caused by proliferating image variants.
🚀 ClawManager Teams is here.
Stop managing a single AI Runtime — start orchestrating a collaborative AI Agent Team.
👑 Leader: understands goals, breaks down tasks, coordinates members, aggregates results
🤖 Members: execute, sync progress, report blockers, deliver results
Under the hood, ClawManager handles it all:
⚙️ Runtime orchestration
🚌 Redis Team Bus for task dispatch & events
📁 Shared /team workspace
💾 Full Team / Member / Task / Event persistence
📊 Leader desktop, team chat, progress & timeline visualization
Not just "spinning up more instances."
✨ Teams turns multi-agent collaboration into a workspace you can create, observe, schedule, and trace.
🔗 https://t.co/LMDg9Nj6py
🦞 ClawManager just shipped an AI Gateway update!
🔐 Model Management — regular vs secure model tiers, per-model endpoint & pricing config
📋 Audit & Trace — every request, response, routing decision & risk hit — fully logged and traceable
💰 Cost Accounting — token usage tracked in real time, costs estimated automatically
🚦 Risk Control — auto-block or route to secure model before the request hits
🌐 15 providers supported, including:
OpenAI · Moonshot · MiniMax · DeepSeek · Ollama · OpenRouter · Local · and more
Kubernetes-native. MIT licensed. Open source.
Try it out and drop us a ⭐ if you find it useful!
🔗 https://t.co/LMDg9Nj6py
#OpenClaw #AIGateway #OpenSource #Kubernetes
🚀Yuan3.0 Ultra: A Trillion-Parameter MoE Model Built for Enterprise AI
🏢Enterprise applications require more than chatbots—real-world workflows demand AI that can efficiently execute multi-step tasks. Yuan3.0 Ultra is the core engine powering enterprise AI agent deployment.
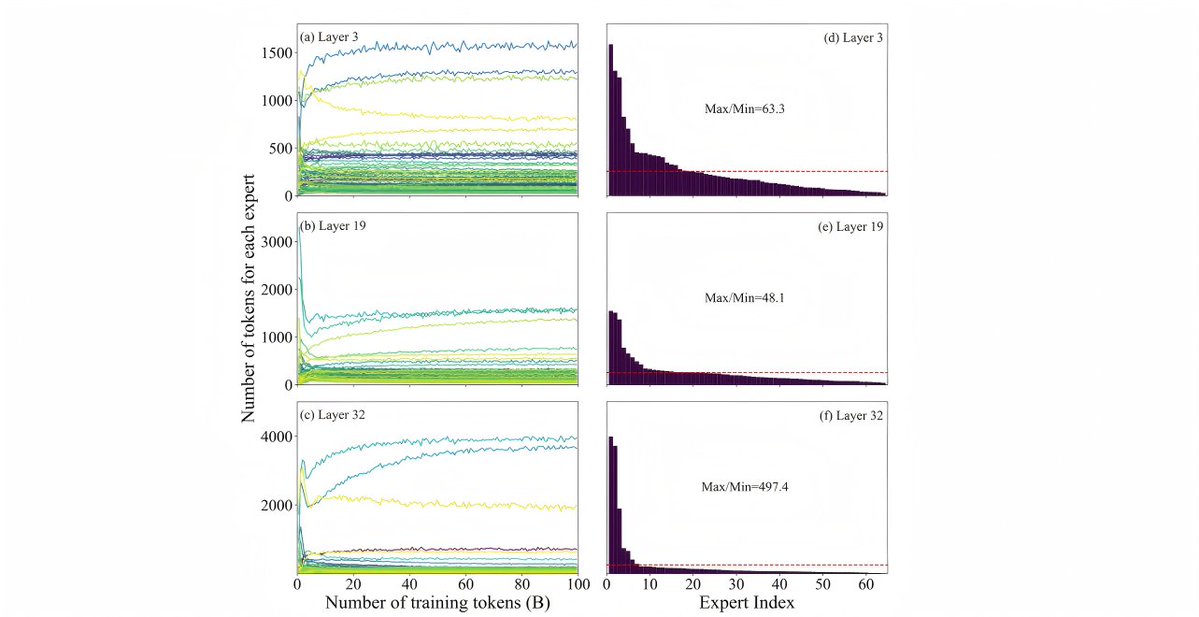
The Innovation: LAEP (Learning-based Adaptive Expert Pruning) Unlike traditional MoE models that sacrifice accuracy for speed, LAEP works with the way experts naturally specialize—pruning redundancies without disrupting functional structure.
Results:
✅️33% fewer parameters (1515B → 1010B)
✅️49% faster training
✅️Only 6.8% active parameters per token (68.8B)
✅️14% shorter outputs, 16% higher accuracy
Built for Enterprise: Document analysis, multi-source RAG, and intelligent tool selection that filters invalid requests.
👐Open source — weights + technical report available now.
https://t.co/GeYKBua1kq
🚀Trillion parameters. Zero compromises. 100% open source.
🔥Introducing Yuan 3.0 Ultra — our flagship multimodal MoE foundation model, built for stronger intelligence and unrivaled efficiency.
✅️Efficiency Redefined: 1010B total / 68.8B activated params. Our groundbreaking LAEP (Layer-Adaptive Expert Pruning) algorithm cuts model size by 33.3% and lifts pre-training efficiency by 49%.
✅️Smarter, Not Longer Thinking: RIRM mechanism curbs AI "overthinking" — fast, concise reasoning for simple tasks, full depth for complex challenges.
✅️Enterprise-Grade Agent Engine: SOTA performance on RAG & MRAG, complex document/table understanding, multi-step tool calling & Text2SQL, purpose-built for real-world business deployment.
📂Full weights (16bit/4bit), code, technical report & training details — all free for the community.
👉Learn More: https://t.co/GeYKBua1kq
Overthinking is quietly becoming the biggest hidden cost in LLM deployment.
Yuan3.0 Flash tackles this with RAPO + RIRM — not by forcing shorter outputs, but by teaching models when to stop thinking.
📷Explore now: https://t.co/EaTVOuZBlt
✨ What’s different:
✅ RIRM penalizes useless post-answer reflection, cutting up to 70%+ wasted tokens
✅ RAPO redesigns RL training to balance reasoning quality, efficiency, and stability
✅ 50%+ training efficiency gain, even on large-scale MoE models
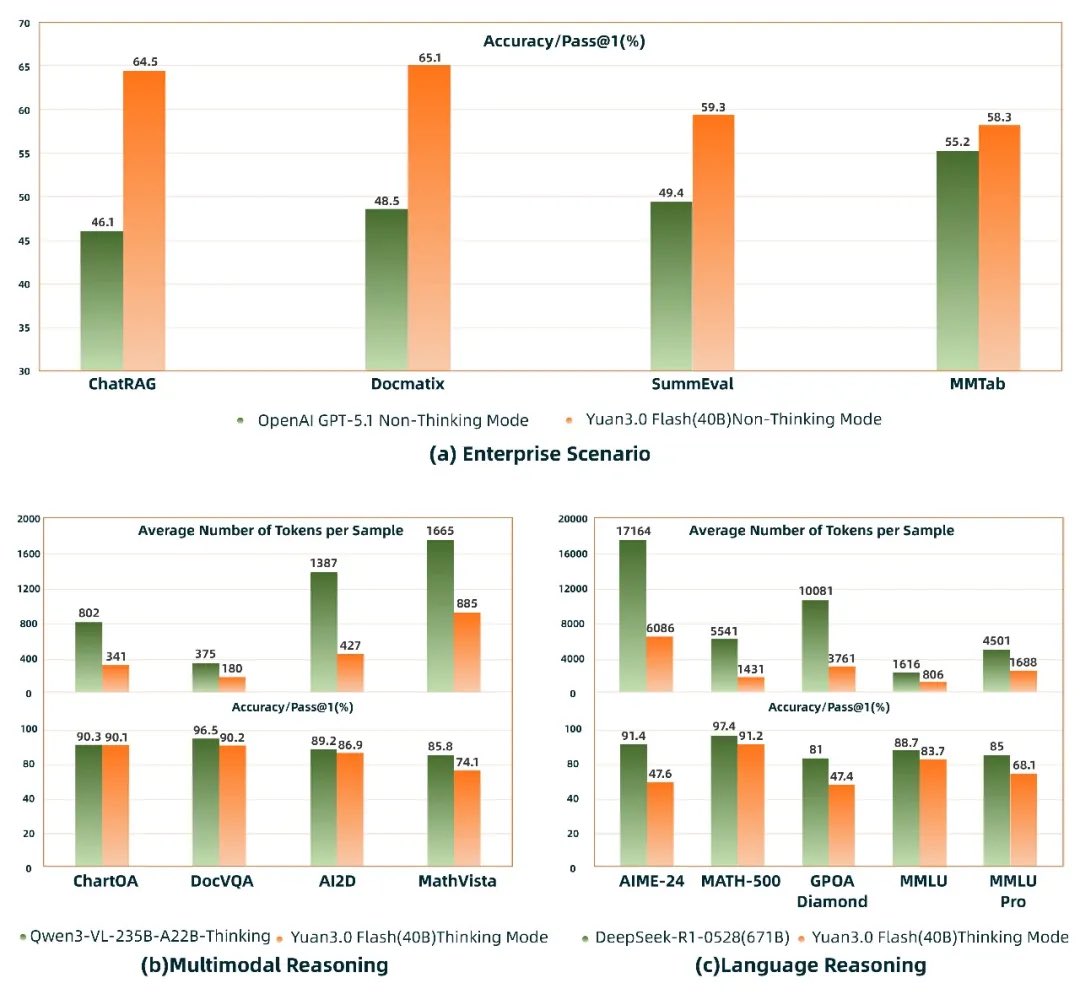
The result: faster iteration, lower inference cost, and reliable performance across real enterprise workloads — RAG, table analysis, and long-document reasoning.
Yuan3.0 Flash isn’t about thinking more.
It’s about thinking precisely enough — and stopping at the right moment.
AI large #model overthinks—even after nailing the right answer?
No more redundant verification without new evidence.
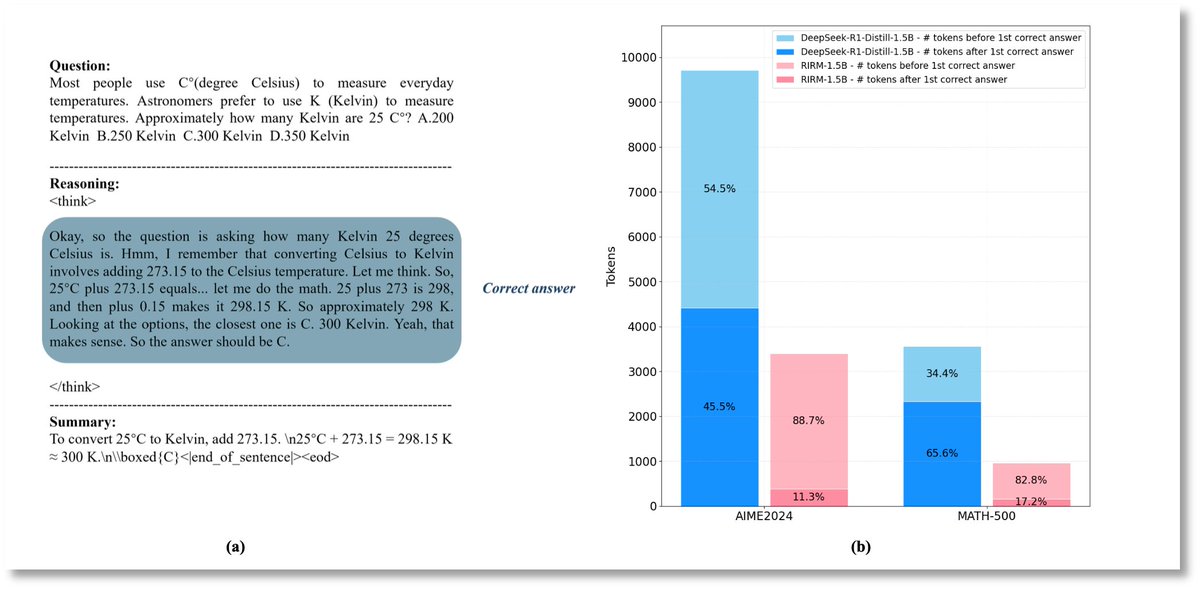
Yuan3.0 Flash’s RIRM (Reflection Inhibition Reward Mechanism) is the breakthrough method that holds models accountable not just for getting answers right, but for knowing when to stop. Repeated logic or post-answer second-guessing is treated as low-value reflection—and suppressed during #training.
✅ 75% less reasoning token usage
✅ Stable—or even improved—accuracy
✅ 2x faster responses (no wasted compute on overthinking)
From "endless overthinking" to "stop when correct"—this is how LLMs move from impressive demos to models that truly scale in production.