Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25+ notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140+ languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX + MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena + LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text+audio+MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video+audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R + VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25+ notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140+ languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX + MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena + LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text+audio+MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video+audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R + VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
Attention was the most interesting part.
In Python, it is one clean equation.
In RTL, it becomes a schedule: generate Q/K/V, scan dot products, track max, approximate exp, accumulate, divide, mix V, then project back.
The core design uses Q4.12 fixed-point math and ROM-backed weights.
Most of the model becomes one repeated operation: matrix-vector multiply. So we built a reusable 16-lane streamed MatVec tile and time-multiplexed it across Q/K/V, MLP, and LM head.
Earlier this year Yann LeCun left Meta because Mark Zuckerberg wouldn't bet the company on JEPA. Last week his group dropped the first JEPA that actually trains end-to-end from raw pixels. 15 million parameters. Single GPU. A few hours.
The timing is not a coincidence.
For four years Meta has been the house that JEPA built. LeCun published the original paper from FAIR in 2022. I-JEPA and V-JEPA came out of his lab. The architecture was supposed to be the escape hatch from LLMs, the path to robots that actually learn physics instead of hallucinating about it. Every version shipped fragile. Stop-gradients. Exponential moving averages. Frozen pretrained encoders. Six or seven loss terms that had to be hand-tuned or the model collapsed into garbage representations.
Meta kept funding LLMs. Llama shipped. Llama scaled. Llama got beat by Qwen and DeepSeek. Zuck spent $14 billion to buy ScaleAI and install Alexandr Wang. The FAIR robotics group was dissolved. LeCun's research kept winning papers and losing the product roadmap.
He left, started AMI Labs, and said publicly that LLMs were a dead end.
Now the paper. LeWorldModel. One regularizer replaces the entire pile of heuristics. Project the latent embeddings onto random directions, run a normality test, penalize deviation from Gaussian. The model cannot collapse because collapsed embeddings fail the test by construction. Hyperparameter search went from O(n^6) polynomial to O(log n) logarithmic. Six tunable knobs became one.
The downstream numbers are what should scare the robotics capex class. 200 times fewer tokens per observation than DINO-WM. Planning time drops from 47 seconds to 0.98 seconds per cycle. 48x faster at matching or beating foundation-model performance on Push-T and 3D cube control. The latent space probes cleanly for agent position, block velocity, end-effector pose. It correctly flags physically impossible events as surprising. It learned physics without being told physics existed.
Figure AI is valued at $39 billion. Tesla Optimus is mass-producing. World Labs raised $230 million to sell generative world models. Everyone in humanoid robotics is burning capital on foundation-model pipelines that plan in 47 seconds per cycle.
LeCun's group just showed you can do it with 15 million parameters on a single GPU in a few hours.
This is the Xerox PARC pattern running again. Meta had the next architecture. Meta had the scientist. Meta dissolved the robotics team, passed on the productization, and watched the exit. Three months later the lab that was supposed to be Meta's publishes the result that resets the robotics cost structure.
The paper is worth more than Alexandr Wang.
Vera Rubin is in full production.
We just kicked off the next generation of AI infrastructure with the NVIDIA Rubin platform, bringing together six new chips to deliver one AI supercomputer built for AI at scale.
Here are the top 5 things to know 🧵
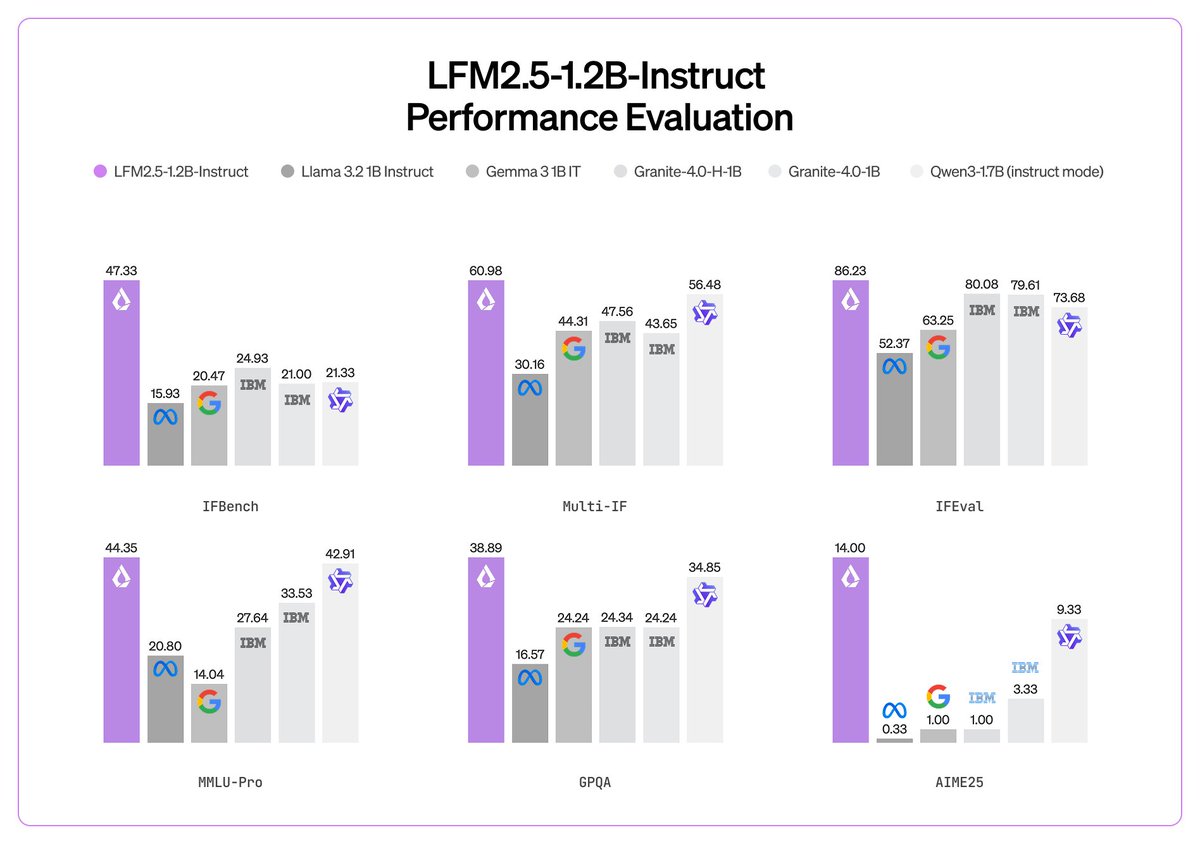
Today, we release LFM2.5, our most capable family of tiny on-device foundation models.
It’s built to power reliable on-device agentic applications: higher quality, lower latency, and broader modality support in the ~1B parameter class.
> LFM2.5 builds on our LFM2 device-optimized hybrid architecture
> Pretraining scaled from 10T → 28T tokens
> Expanded reinforcement learning post-training
> Higher ceilings for instruction following
🧵
🚀 LTX-2 is now open source: text → audio + video.
Today we’re releasing LTX-2, the first open-source foundation model for joint audiovisual generation, together with a full technical report.
🧵👇
🧵a thread on the RAMpocalyse
Most of us are aware that every device uses RAM: it’s random access memory
But what if the consumer market is obliterated by enterprise need?
Here’s what I see , the overlap is weird because the same machines that make enterprise , also make consumer.
My goal has always been to push this space forward
Ever since 2023 I dedicated myself to making models great again
Try @ZeroXClem for the free, see for yourself how much open source has caught up