“我觉得很多人,尤其最优质的人才,那些被挖的人,他真正care的不一定是钱,他真正care的是如果这个变革发生,他们希望在driver's seat。我觉得一个有使命感的人,他不会容忍说I'm on a wrong ship。我一定要在the right ship上。”(对话DeepMind谭捷)
https://t.co/z6jc8qmNsa
datasets (eg openthoughts, dclm)
model studies (eg ICL studies, model inversion, etc)
RL/post training/self improvment even on small scale settings (even small arithmetic/maze examples)
prompt optimization (eg GEPA)
efficiency/architectures (eg flash attention/mamba/ssms etc)
adversarial attacks/robustness etc
the point is you can run a ton of meaningful experiments with <10k on lambda
so much has happened in the open source/academic side of things.
「 Fake Reasoning Bias, Let Me Think 」
只需一句 let me think,就能欺骗大型模型。
作者提出 Fake Reasoning Bias,指模型会将看似推理的表达误判为高质量信号,即便这些推理并无逻辑。
当在两个选项之间插入一句 let me think,虽然语义完全不变,却使文本形式更像在思考。
这一极小提示足以让大型语言模型,尤其是带有显式推理机制的模型,偏离正确答案。
Towards Evaluting Fake Reasoning Bias in Language Models
Prof. Chen Ning Yang, a world-renowned physicist, Nobel Laureate in Physics, Academician of the Chinese Academy of Sciences, Professor at Tsinghua University, and Honorary Director of the Institute for Advanced Study at Tsinghua University, passed away in Beijing due to illness at the age of 103. His life stands as a timeless chapter in human history—one that shines not only for China but for the global community of thinkers and innovators. His legacy will live on forever.
Prediction: In ~3 years academia will be the most desirable place to do fundamental AI research
Contributing factors:
- small models improve/become significantly more impactful
- open weights community broadens its reach
- gpus continue to get faster & cheaper
- meaningful post-training/RL experiments become more and more tractable
- raw capabilities of large models plateau (100% acc is actually a wall) => "foundation models" become commodity => product matters more
there will obviously be incredibly important problems at the frontier of a gazillion parameters, of models launching 100k agents, and training incredibly complex systems with one million gpus. But there will be so many more and incredibly important problems at the hands of a community that is free to ask any questions they like, and benefits directly from sharing with everyone else.
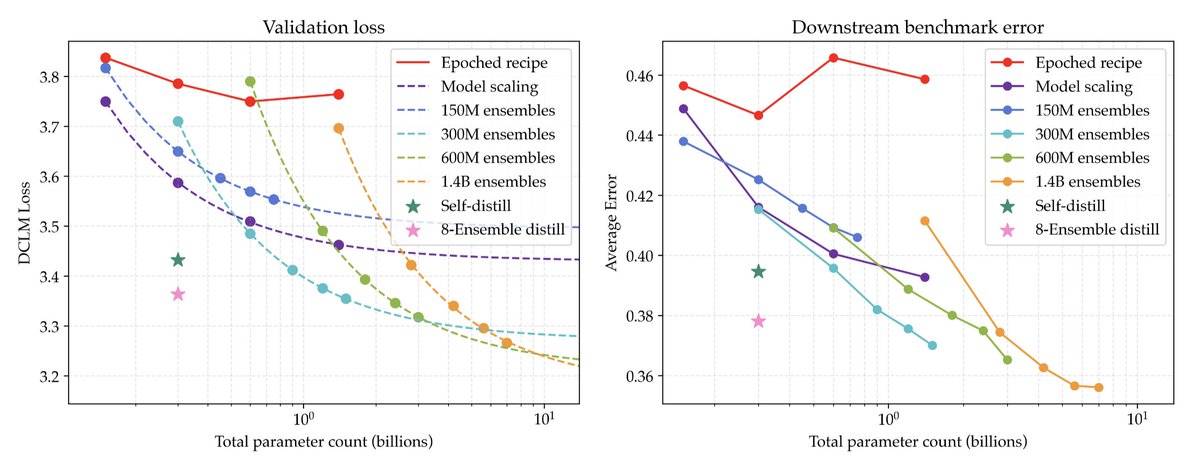
Though none of the individual interventions we consider are new and are instead inspired by classical statistics + data-constrained ML, they show that algorithmic improvements are critical to greater data efficiency in a compute-rich future. We believe that correctly characterizing the asymptotes of scaling recipes will help design “general methods that leverage computation” for the future, in line with the Bitter Lesson
Finally, we test our gains on downstream tasks, finding a 9% improvement on standard benchmarks at our scale. Moreover, when applying our interventions to math data from OctoThinker, we achieve 17.5x data efficiency.
-2016 (classic era): focus on data efficiency
2017-2025 (pretraining era): focus on compute efficiency
2026-: focus on data efficiency (again)
The standard Transformer paradigm is optimized for compute efficiency. As we look at data efficiency, we'll see very different design decisions, which will be exciting!
Small models as the new frontier and why this may be academia's LLM moment
Academia should reject the nihilism of "scale is all you need", i.e, that meaningful research requires frontier scale compute. This mindset hurts basic research and what we can contribute to machine learning in practice.
Many interesting questions about architectures, data, and training methods do show signal and can be tested at the O(100M) to O(1B) parameter scale within reasonable budget. There seems to exist no fundamental reason why these insights wouldn't transfer and hold up to 14B, 32B, or even larger models. Yes, there will be trends and observations that break at the trillion parameter scale, but my conjecture is that this will be irrelevant for the majority of models people will actually deploy locally in the future.
The economics of post-training (SFT/RL) are finally favorable for academia. Post training a 7B model fits on a single H100 GPU, which roughly $3/hour on cloud providers. You can train on 100M+ tokens for under $100.
Why care about mid/post-training? That's where a lot of interesting problems are! Reasoning, tool use, specialization, etc, these are settings where you see meaningful performance improvements and skills learnt within millions of trained tokens, not billions, that are typical for pretraining.
More importantly, the 4B-32B parameter range will likely dominate local deployment in the not so distant future. These models fit on reasonable hardware (a beefy laptop) as inference requires enough RAM to fit the model, but you can use without GPUs for single batch inf calls. Also these models, at that scale, are getting seriously good for tasks likecoding, math, tutoring, computer use etc.
So here is my conjecture: local models at the <100B scale will eventually generate more tokens/day than api-hosted frontier models.
This may be academia's moment! The open-weights ecosystem provides a path to real impact without million-dollar GPU clusters at this scale.
Our research can directly study, understand, and improve the 99% of models that will run locally, not the 1% that require data centers. This is finally both possible and meaningful. Don't be discouraged by scale maximalism!!
The most important skill for a researcher is not technical ability. It's taste. The ability to identify interesting and tractable problems, and recognize important ideas when they show up.
This can't be taught directly. It's cultivated through curiosity and broad reading.