👋 In Chicago + Purdue area today till Friday, feel free to ping if you are around -- giving 2 keynotes at: (1) Midwest Machine Learning Symposium (MMLS 2026) & (2) Tenth International Workshop on Symbolic-Neural Learning (SNL 2026) on the diverse topics below 👇 & looking forward to engaging discussions + meeting folks from all the strong universities in the midwest & beyond! 🙂
Excited to share ✨HiViG✨, a test-time intervention framework for long-horizon GUI tasks via history state tracking and visually grounded error analysis.
1️⃣ History state tracking: HiViG summarizes past interactions into a compact macro-action history, enabling better history-aware planning of policies over long horizons.
2️⃣ Visually grounded error analysis: Instead of overly relying on the policy's textual intents, HiViG verifies raw execution coordinates against the current GUI env screenshot. If an action proposed by the policy is flawed (e.g., visual hallucination, termination misjudgment), it provides corrective guidance before execution.
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
🚨 Excited to share SpatialUncertain — a controlled framework for evaluating whether VLMs know when not to answer spatial questions (and why).
➡️ Spatial reasoning is not just about finding the right answer—it is about knowing whether the available evidence supports an answer at all.
Visual observations can be incomplete or even misleading.
📦 Objects may be hidden by occlusion.
📐 Perspective may create misleading visual cues.
Yet today's VLMs are usually evaluated as if every question has a reliable answer. We introduce SpatialUncertain, a controlled framework for evaluating:
🔍 Can VLMs recognize when visual evidence is insufficient or unreliable?
🧭 Can they identify what additional viewpoints are needed before answering?
Thread🧵👇
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning + forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels + runtimes from evolutionary search, costing 400M reasoning tokens + 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens + 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
I'll be at #CVPR2026, feel free to ping if you want to meet up! Will be giving 4 different keynotes at these exciting @CVPR workshops and looking forward to engaging discussions on diverse topics 🙂
(also happy to discuss hiring at all levels: PhD, postdoc, faculty)
ps. also meet several of our awesome students/postdocs who will be attending
LLM agents & memory systems operate in continuously updated environments (Git repos, evolving docs). They must process long contexts, recover earlier information, and reason over many updates that create interference between old and new information. How well do they handle this?
We introduce MINTEval:
✅ Frequent context changes & interference (avg. 86 updates)
✅ 5 challenging question types, including long-range lookback & reasoning over multiple targets distributed across context
✅ 4 realistic domains: state tracking, multi-turn dialogue, Wikipedia revisions, GitHub commits
✅ Avg. 138.8k tokens per instance (up to 1.8M)
✅ Human verification on generated QAs = 95.6%
📊 Across 7 representative systems, MINTEval remains difficult, showing an avg. acc of 27.9%, and the best system reaches only 33.4%.
🔎 Our analysis shows:
• Memory construction failures cause a 41.7% drop
• Memory agents are highly sensitive to design choices
• Memory systems have a strong bias toward insertion operations (76.8%) over deletion/update
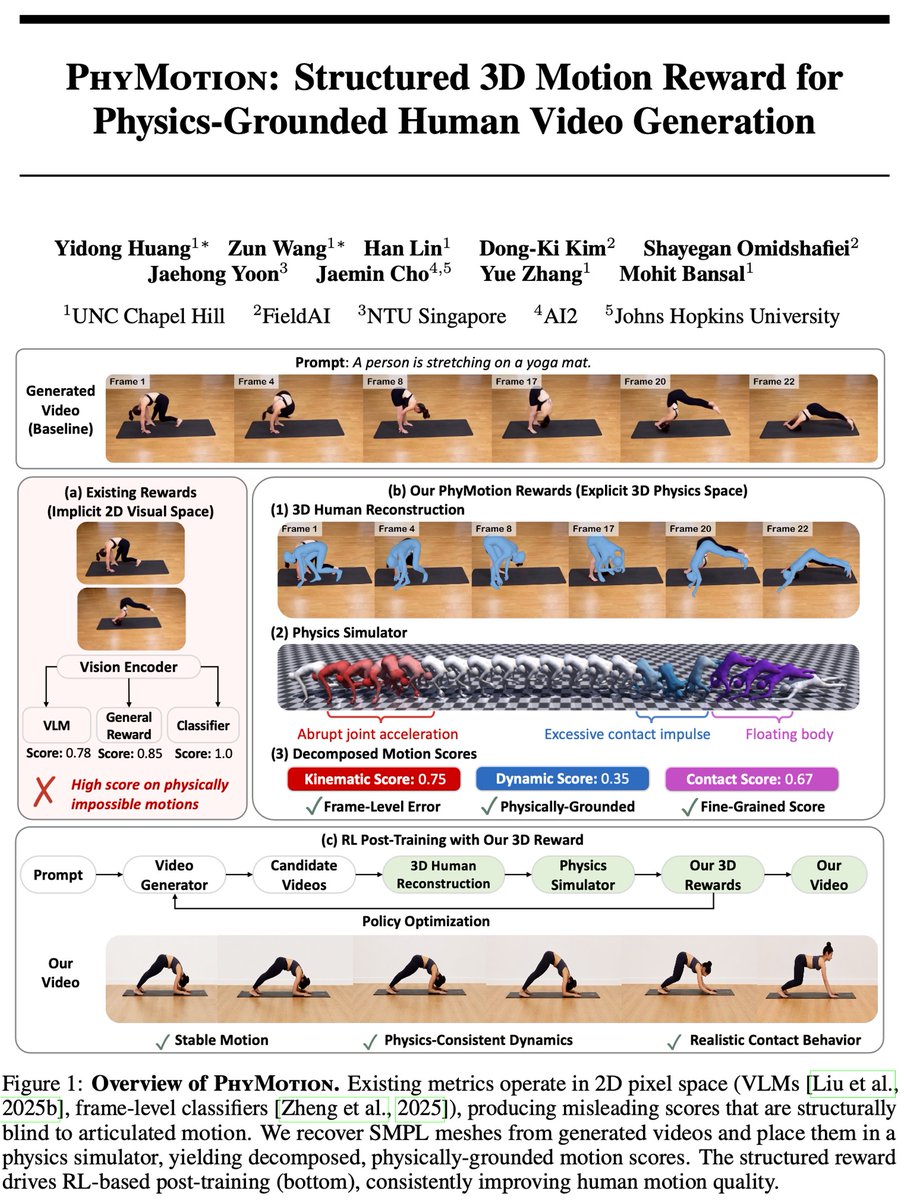
🚨 Excited to introduce PhyMotion🤸: Structured 3D Motion Reward for Physics-Grounded Human Video Generation!
❌ Existing 2D video rewards misleadingly assign high scores to videos with floating feet, self-penetrating limbs, and physics-violating motions.
✅ PhyMotion lifts generated videos into 3D, grounds them in a physics simulator, and scores motion along kinematic / contact / dynamic feasibility.
➡️ RL post-training with PhyMotion improves 1.3B model to match 14B models performance in human prefence.
🧵(1/n)👇
🚨Excited to announce Agent-BRACE!
LLM agents in long-horizon POMDPs either blow up their context with raw history or summarize it, discarding uncertainty by collapsing belief into a point estimate. Agent-BRACE decouples the agent into belief state + policy models, jointly trained via RL.
Key takeaways:
1️⃣ 🎯The belief state model produces a structured approximation of the belief distribution as a set of atomic natural-language claims with ordinal verbalized certainty labels ranging from certain to unknown. The policy conditions on this compact belief rather than the full history.
2️⃣ 📈 Outperforms strong RL baselines on long-horizon partially observable embodied language environments while maintaining a near-constant context window independent of episode length.
3️⃣ 🔄 The learned belief becomes increasingly calibrated as evidence accumulates, and epistemic belief decreases over time: the proportion of claims that the agent has the strongest level of belief in grows from 21% → 52% over an episode.
👇🧵
🚨 Excited to share EgoMemReason, a benchmark for multi-level memory-driven reasoning (entity, event, and behavior memory) over week-long egocentric videos (average 25.9 hours of temporal backtracking)!
📉 Current long video approaches can retrieve isolated event, but struggle with long-horizon memory that requires retrieve and understand across multiple events and long time: tracking evolving entities across days, linking temporally distant events, and abstracting recurring behavior patterns from long observations.
🎥 EgoMemReason evaluates these challenges through 500 human-verified questions spanning entity, event, and behavior memory, requiring aggregation over an average of 5.1 evidence segments and 25.9 hours of temporal backtracking.
⭐️ Across 17 models/frameworks, even the best model achieves only 39.6% accuracy, revealing that long-horizon multimodal memory remains far from solved.
🎉 Excited to share that our work on intrinsic dimensionality of reasoning has been accepted to #ICML2026 as a ✨spotlight✨ (top 2.2%)!
We analyze the effectiveness of teaching a model how to reason via the lens of intrinsic dimensionality (the minimum effective capacity a model needs to solve the task) and find that effective reasoning chains are inherently compressive!
Across Gemma-3 1B and 4B, lower intrinsic dimensionality strongly predicts not only in-distribution accuracy (GSM8K), but also robustness on OOD benchmarks (GSM-Hard, GSM-Symbolic, GSM-IC) -- outperforming reasoning length, token perplexity, and KL divergence.
Stay tuned for more results and exciting updates in the camera-ready! 🚀
@mohitban47 Thank you for the kind words! Working in your lab as an undergrad has deeply shaped how I think about research, and I am grateful for everything I have learned under your guidance.
@EliasEskin Thank you Elias! I am very grateful for all the guidance you have given me on my research journey and for the opportunity to work together on such exciting problems.
Honored to receive the @NSF Graduate Research Fellowship! 🎉 A huge thank you to my mentors @mohitban47 and @EliasEskin for guiding me on my research journey, and to the brilliant MURGe Lab graduate students and postdocs who have supported me along the way during my time in @unccs.
My prior work has studied enhancing multi-agent reasoning through more advanced tool recruitment (DART) and also increasing model faithfulness (REMuL). I’ve been fortunate to apply these multi-agent ideas into impactful applications across education and healthcare. I hope to continue working on improving multimodal understanding and collaborative AI agent systems in the future!
Today, NSF announced it has made offers & will award 2,500 Graduate Research Fellowships for the 2026-2027 academic year to outstanding graduate students across the U.S. pursuing research-based degrees in science, technology, engineering and mathematics. https://t.co/IYju3vBuuC
I won’t be attending #ICLR2026, but @LucasPCaccia and @EliasEskin will be presenting our work, Gistify!
We study whether coding agents can truly understand a repository by extracting its gist: generating a single, self-contained, executable file that reproduces the behavior of a target command (e.g., a test or entrypoint). It is lightweight, broadly applicable evaluation of codebase-level reasoning!
I’d also love to connect online. Feel free to reach out!
📅 3:15 PM-5:45 PM Thu, Apr 23, 2026
📍 Pavilion 3, Poster 1020
Had a great time visiting the University of Virginia last week for their CS Distinguished Speaker Series -- talked about skill discovery + improvement as well as some newer work in mixture-of-agents' skill profiling + matching + disagreement resolution, in context of building trustworthy (calibrated, controllable, collaborative) multimodal AI agents (incl. education and healthcare applications)!
Thanks again for the kind invitation and exciting discussions Yangfeng, Haiying, Aidong, Tom, Yen-Ling, Jundong, Rohan, et al. (and for the nice photos) 🙏
PS. Also found many similarities between UVA and UNC campuses w.r.t. the beautiful hilly terrain and drives, the big central quad/lawn, the traditional brick architecture (and the amazing farmers markets in both places) 🙂
🚨 Excited to announce MERRIN: a human-annotated, expert-vetted benchmark for Multimodal Evidence Retrieval and Reasoning in Noisy Web Environments! 🌐🔍
The web is noisy, conflicting, and multimodal. Even strong search agents fail when questions require reasoning across text, images, video & audio — MERRIN is built to diagnose exactly where they break down, via multi-hop reasoning on open-web search without explicit references to specific modality sources.
Honored to receive the @NSF Graduate Research Fellowship (GRFP) 🎉. I’m deeply grateful to have conducted research @unccs in the MURGe-Lab under the guidance of @mohitban47 and @EliasEskin, and for the support of the many PhD students and Postdocs who shaped my experience at UNC and helped me grow through my projects.
My previous work leveraged a scientific understanding / interpretability perspective to compress LLMs via quantization (Task-Circuit Quantization) and also to predict their correctness (General Correctness Models). More recently, I used RL in long horizon tasks to study ToM (AI Double Agents). These works have inspired me to focus on developing a better scientific understanding of- and improved memory for- foundation models in the future!
Congrats Hanqi and very well-deserved for your exciting works on Task-Circuit Quantization, General Correctness Models, and AI Double Agents ToM! The pleasure was ours and looking forward to continued exciting works from you 🙂
#ProudAdvisor