This is a great article on how startups/frontier labs can coexist. Another way to look at this is task complexity - the number of bits of information needed to specify a task such that AI can solve the task above a threshold of accuracy:
* If the minimum number of bits is low (e.g. summarize call transcript), then you can just prompt Claude Cowork to do it.
* If the minimum number of bits is much higher (e.g. follow a 100-page SOP for a production-line deviation) - especially if the task needs to be standardized throughout the org - then the act of specifying the task with the relevant guardrails/auditability/communication becomes much more complex, and it is simply infeasible to expect that an organization can harness the core technology without the software scaffolding in place.
Higher complexity task specifications are correlated with how complex it is to verify those tasks, though they aren't necessarily the same. I think both directions are opportunities for AI startups to tackle.
✅ E.g. an e2e sales rep agent is somewhat easy to verify (overattain your number), but task specification of how to actually do it is complex, and the time horizon for running it can take over a year - to see whether the rep can actually hit its number! This means that even if Fable 5 can do it accurately by just giving it a goal, there's lots of opportunities to optimize this workflow to massively reduce cost (in this case it matters for S&M spend)
✅ A lot of tasks are both highly complex to specify and hard to verify e.g. complex insurance claim adjudication. In these cases, the massive bottleneck isn't the model itself, but in the human's ability to even define what good looks like to solve the task at hand.
As frontier models get better, the minimum number of bits to specify any task will go down, but IMO there will still be a massive gap for knowledge work that any non-frontier lab company can exploit.
We're presenting ParseBench at CVPR 2026 today. 🦙
Come learn why document understanding is an AGI-complete problem (an agent can't act on a doc it can't correctly read, and reading a real enterprise table is harder than it looks).
The first doc-parsing benchmark built for AI agents:
2,000+ human-verified pages
167K+ test rules
5 dimensions: tables, charts, faithfulness, formatting, grounding
Fully open source.
📍 Talk TODAY, June 4, 9–10 AM at CVPR. Come say hi 👇
🤗 https://t.co/skla84GVTc
💻 https://t.co/h7SpuTWYVn
📄 https://t.co/VnKcb48oJl
ParseBench is now live on Kaggle Benchmarks! 🚀
Developed by @llama_index, this benchmark evaluates PDF-to-structured-data conversion, featuring ~2k human-verified pages from real enterprise docs across 5 capability dimensions.
🥇Gemini 3 Flash: 79.3%
🥈GPT 5.4: 72.9%
🥉Gemma 4 31B: 66.4%
In SF, never ask why your friend is late to lunch or dinner.
There’s only one reason:
they were fighting for their life writing a prompt so Claude Code/Codex could run for 1+ hour without them.
Improve document parsing accuracy by 15% for financial PDFs.
Use LlamaParse and Gemini 3.1 Pro to extract high-quality data from unstructured brokerage statements and complex tables.
📈 Precise reasoning
📂 Structured PDF data
⚡️ Event-driven scaling
Dive into the code on GitHub → https://t.co/yi7KxVzNPY
One of the biggest requirements for document OCR is visual grounding, and frontier models (gemini, opus, gpt-5.4) suck at it by default.
In other words they don't have a great sense of the positions of things on a page.
We've made massive strides in making sure our models are able to segment and detect every granular element in the most complex docs. This allows you to build AI agents that can surface extremely precise citations in the source documents:
✅ newspapers
✅ infographics
✅ handwritten notes
✅ product catalogs
✅ research presentations
and much more
Come check it out in LlamaParse!
https://t.co/TqP6OT5U5O
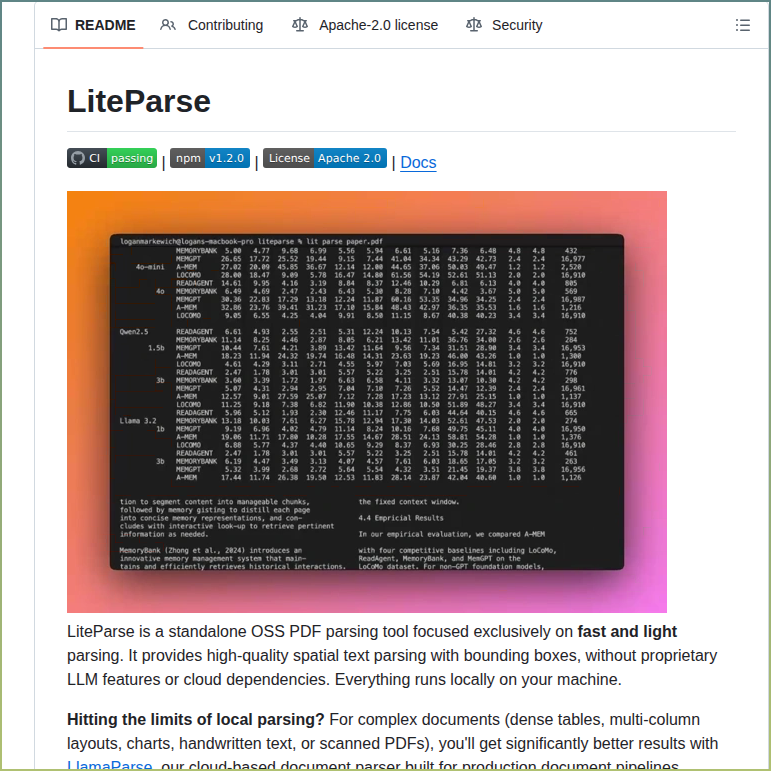
Introducing LiteParse - the best model-free document parsing tool for AI agents 💫
✅ It’s completely open-source and free.
✅ No GPU required, will process ~500 pages in 2 seconds on commodity hardware
✅ More accurate than PyPDF, PyMuPDF, Markdown. Also way more readable - see below for how we parse tables!!
✅ Supports 50+ file formats, from PDFs to Office docs to images
✅ Is designed to plug and play with Claude Code, OpenClaw, and any other AI agent with a one-line skills install. Supports native screenshotting capabilities.
We spent years building up LlamaParse by orchestrating state-of-the-art VLMs over the most complex documents. Along the way we realized that you could get quite far on most docs through fast and cheap text parsing.
Take a look at the video below. For really complex tables within PDFs, we output them in a spatial grid that’s both AI and human-interpretable. Any other free/light parser light PyPDF will destroy the representation of this table and output a sequential list.
This is not a replacement for a VLM-based OCR tool (it requires 0 GPUs and doesn’t use models), but it is shocking how good it is to parse most documents.
Huge shoutout to @LoganMarkewich and @itsclelia for all the work here.
Come check it out: https://t.co/qmpDwlkidZ
Repo: https://t.co/JNER0mVcB8
LlamaParse Agentic Plus mode now delivers precise visual grounding with bounding boxes for the most challenging document elements.
Our latest update brings major improvements to how we handle complex visual content:
📐 Complex LaTex formulas - accurately parse mathematical expressions with precise positioning
✍️ Handwriting recognition - extract handwritten text with location coordinates
📊 Complex layouts - navigate multi-column documents and intricate formatting
📈 Infographics and charts - identify and extract data visualizations with spatial context
This means you can now build applications that not only extract text from documents but also understand exactly where that content appears on the page - perfect for creating more intelligent document analysis workflows.
Try LlamaParse Agentic Plus mode and see how visual grounding transforms your document parsing capabilities: https://t.co/yPVJzqoKal
Launching UGC Studio for the #tempochallenge by @tempo_labs: a platform that centralizes projects, earnings, clients, and AI-powered ideas in a fast, modern interface built for UGC creators. Less managing, more creating. Build: https://t.co/Nq7tQP1ZS3
1/
Hi, my name is Isaac Martinez. I am a PhD student in Economics at the LSE, and I wanted to share something personal. On July 6, 2025, I suffered a stroke while I was finishing my PhD. It was completely unexpected and changed my life. #EconTwitter#EconJobMarket