Last month, we showed how you can use Cleanlab to find bad data in any sequence-to-sequence (ie. LLM fine-tuning) dataset. This month, we applied this approach to create a higher-quality version of the databricks-dolly-15k dataset - now available here:
https://t.co/onnR2bcei4
Here's another version of the original dataset containing smart metadata produced by Cleanlab, which you can use to curate your own cleaner dataset versions 👇https://t.co/ovbFR61pR2
Fast-track your time series analysis to perfection with Cleanlab Studio AutoML. Precision has never been this swift ⏰ Find out how in our latest blog post!
https://t.co/FpVdOLF8rN
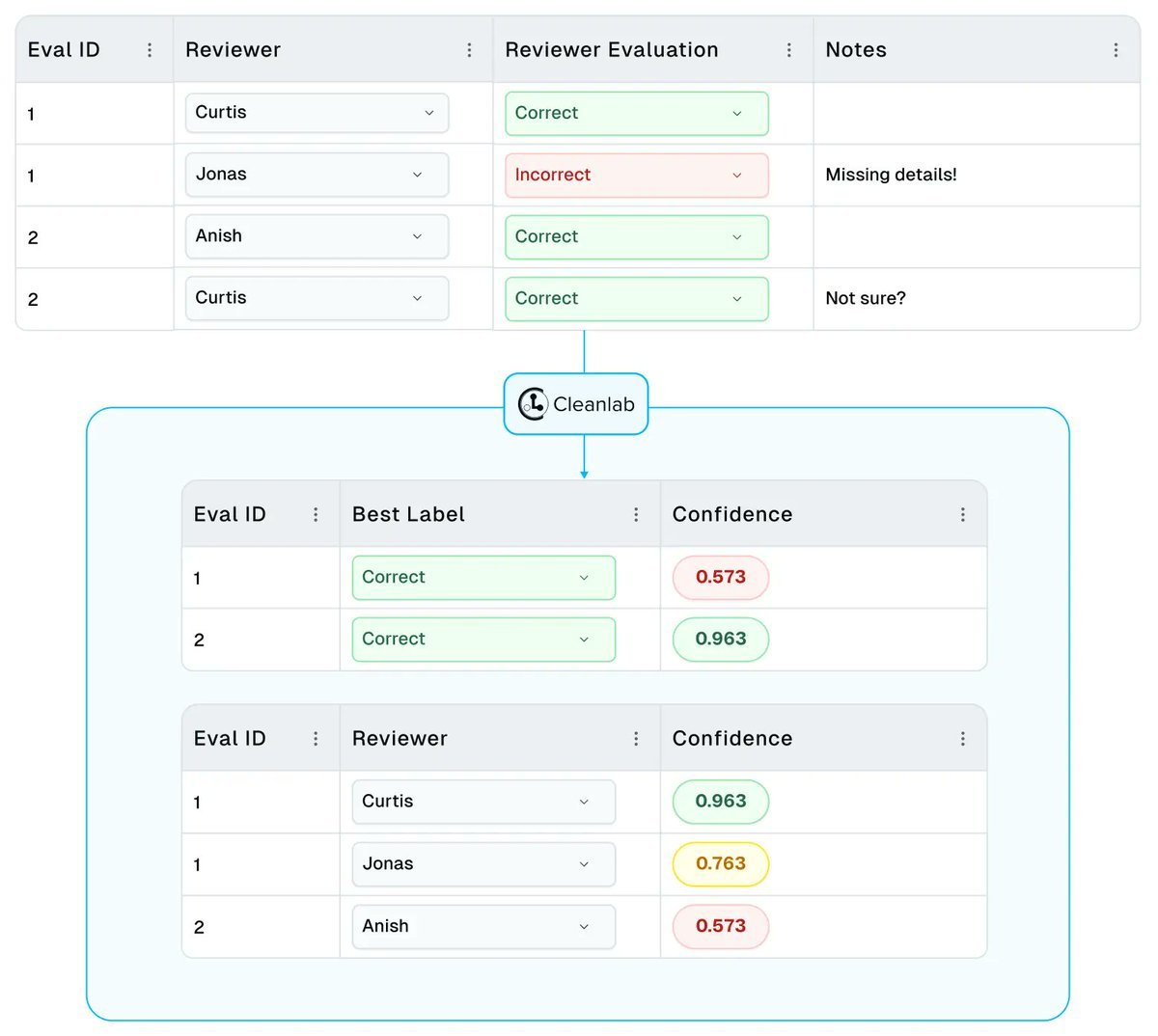
To achieve more accurate LLM Evals with less manual review, you can freely run this method via the open-source cleanlab library. It works with any LLM judge combined with any number of human reviewers per example. We apply this to MT-Bench dataset w GPT-4 LLM-as-judge logprobs
Is your team struggling to evaluate how much better a new LLM/prompt is?
For accurate & efficient LLM Evals: our latest blogpost demonstrates the optimal way to combine multiple human/AI evaluators into confident labels
👉https://t.co/xeHuBaH9dO
Don’t want users to lose trust in your RAG system?
Then add automated hallucination detection.
A new benchmark across 4 RAG datasets reveals which detector best flags incorrect AI responses (amongst RAGAS, G-eval, DeepEval, TLM, LLM self-evaluation)
👇
https://t.co/NMtHNlQC6A
Whenever your LLM outputs untrustworthy answers: these automatically trigger a guardrail, so you can instead return a fallback response or escalate to a human agent.
Adopt this simple framework to make your AI applications significantly more reliable:
https://t.co/OGNNWlcFBO
Worried your AI agents may hallucinate incorrect answers? Now you can use Guardrails with trustworthiness scoring to mitigate this risk. Our newest video shows you how, showcasing a Customer Support application that requires strict policy adherence.
https://t.co/ASlMs3gQtj
Detecting wrong/hallucinated LLM responses is key for reliable AI, but what about otherwise bad responses that don’t meet use-case specific criteria? Update to our TLM: You can now specify custom evaluation criteria to evaluate LLM response quality! More below 👇
Why not just ask the LLM directly to rate its answer? Today’s LLMs cannot reliably output numerical ratings. TLM produces a more reliable LLM score based on your custom evaluation criteria via a faster variant of the G-Eval algorithm. Across diverse benchmarks, TLM custom evaluation criteria are much more effective than methods like G-Eval or LLM self-rating.
Proper response abstention is key to reliable AI in applications that remain nontrivial for LLMs! Read the study we published today to learn how to automate abstention with any LLM and see benchmarks against OpenAI 👇
https://t.co/DgZP9Jk7zV
OpenAI’s new SimpleQA benchmark encourages LLMs to not attempt answers where they might otherwise respond incorrectly. Here’s a recipe to reduce incorrect LLM responses that proved consistently effective across SimpleQA benchmarks with GPT-4o and 4o mini:
1. Filter low-confidence responses to have the LLM abstain instead of answering.
2. Apply response-improvement techniques to boost accuracy.
Both can be achieved automatically (in real-time) via our TLM system.
Across SimpleQA: TLM reliably auto-detects queries where the OpenAI LLM response is untrustworthy such that we can return a fallback answer instead of an incorrect response -- all without harming the rate of correct responses. 🧵
GPT-4o + recently-updated Sonnet 3.5 are among the world's most accurate LLMs, but still produce too many wrong responses. Our latest article demonstrates how you can automatically reduce the rate of incorrect responses of GPT-4o by up to 27% and of Sonnet 3.5 by up to 20% [...]


















![_abellaskies's tweet photo. GPT-4o + recently-updated Sonnet 3.5 are among the world's most accurate LLMs, but still produce too many wrong responses. Our latest article demonstrates how you can automatically reduce the rate of incorrect responses of GPT-4o by up to 27% and of Sonnet 3.5 by up to 20% [...] https://t.co/7tSn3LHlv4](https://pbs.twimg.com/media/GfqVjFTWUAAazVb.jpg)




















