On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
We have been exploring new algorithmic frontiers and are excited to share our contributions to Self Distillation Policy Optimization (SDPO) for agentic continual learning, check out our blog post here:
https://t.co/5xjL02jtUz
Today and tomorrow we’ll be presenting self-distillation with orals at ICLR in Rio 🇧🇷
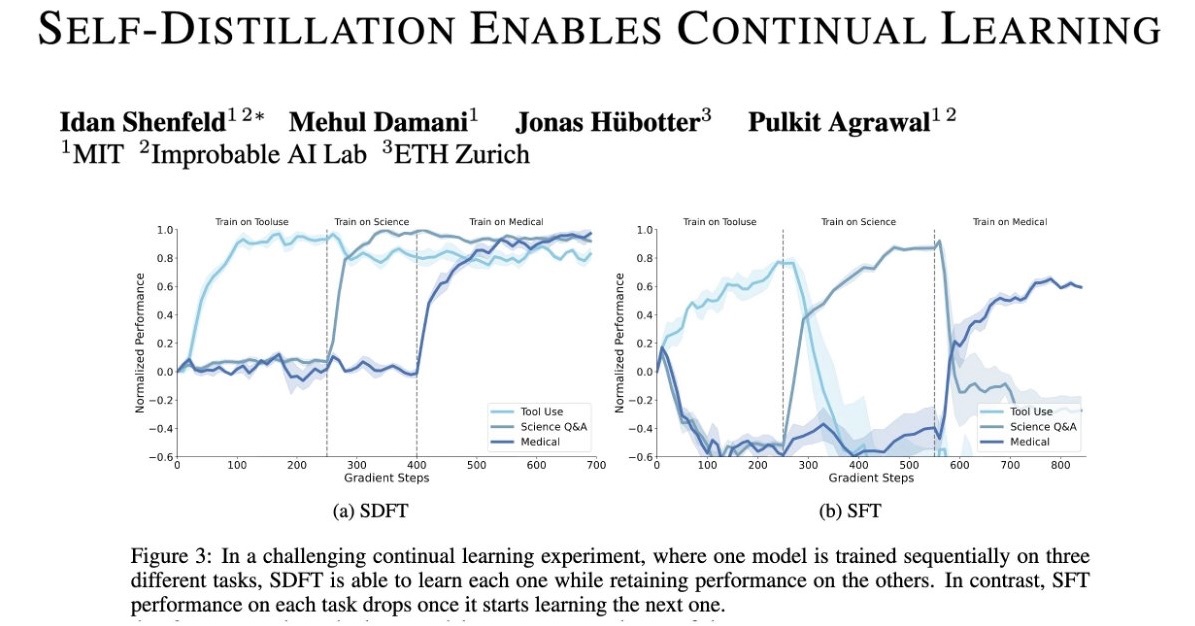
1. “Self-Distillation enables Continual Learning” at lifelong agents workshop (Sun 11:30am)
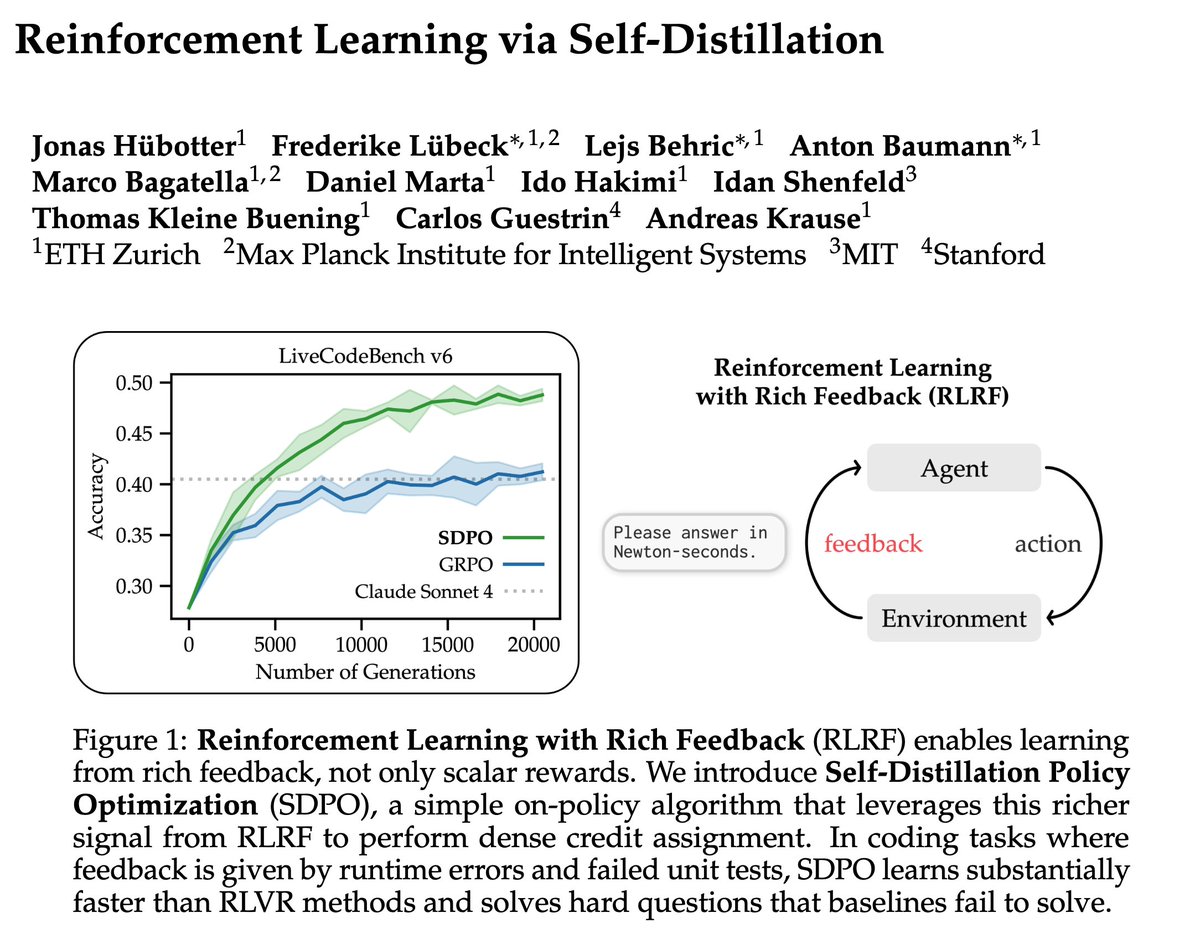
2. “Reinforcement Learning via Self-Distillation” at scaling post-training workshop (Mon 2:40pm)
3. “Test-Time Self-Distillation” at test-time updates workshop (Mon 4:15pm)
Just came across this great discussion of self-distillation on @latentspacepod! Really good run down by Ted Kyi and we’re every bit excited about what’s next as he is!
https://t.co/G5LrWlOT8B
Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)