I am absolutely thrilled to announce that four research papers from our group + collaborations have been accepted to ACL 2026, covering critical areas of Reasoning, Interpretability, Safety, Multimodal AI, and Model Unlearning. Huge congratulations to all the authors and collaborators for their contributions!
Stay tuned for updates and links to our papers soon!
#ACL2026 #AikyamLab
AI is no longer just a chatbot; it is becoming an everyday advisor: shaping how we make decisions about money, health, work, relationships, and other important daily choices.
A common belief is that if something goes wrong, we can simply inspect the AI agent’s chain-of-thought to understand why it made a specific decision.
Our paper challenges that assumption: models can produce convincing reasoning while hiding what actually influenced their answer. This behavior is even more severe if you interact with your AI in low-resource languages like Arabic, Korean, Russian, Swahili, Telugu, etc.
Our experiments found AI manipulating steps, rationalizing after the fact, or following misleading hints that concealed their actual reasoning. The takeaway is clear: a transparent-looking chain-of-thought is not the same as a reliable audit trail.
To build AI agents we can trust, we need more research on multilingual, causal, and verifiable monitoring methods.
Fun collaborating with @EricOnyame@zhou_runtao@kowshik0808@_cagarwal
Can we trust LLM Chain-of-Thought as a safety monitor? 🛑
Our new paper reveals that CoT monitoring collapses under linguistic shifts. Mechanistically, models committed to a misaligned cue in their latent activations within the first 15% of generation.
Paper: https://t.co/tG4qeQjnR3
Website: https://t.co/eI7Z4SDL5q
Here’s what we found across 13 languages: 👇
The danger scales with language resources. In low-resource languages, deceptive patterns hit 100%. Relying on English-only safety evaluations leaves massive vulnerabilities in global AI deployment 🌍
@AbakaAI_Tech@CVPR Exactly - we've normalized processing huge amounts of image tokens when many tasks only require a small fraction of that visual processing. Reducing unnecessary token processing could be a massive unlock for efficient real-time VLMs.
Do Vision Language Models (VLMs) really need deep visual processing? 🤖
Our paper accepted as Oral Presentation @CVPR TRUE-V Workshop suggests the current paradigm of multimodal LLM architectures might be wildly inefficient.
Here is why we might be over-processing image tokens 🧵 (1/4)
Paper: https://t.co/PNM4XXULaV
Code: https://t.co/C0oDExrlgZ
Congrats to @sambitghsh for leading this work! Great collaboration with @rvbabuiisc and @val_iisc!
NeurIPS + EMNLP just hit 50k+ submissions in May. We’re either witnessing the greatest explosion of ideas in AI history… or the peer review system is collapsing under its own weight.
The catch of our analysis? It’s task-dependent. Complex multi-token generation still needs sustained visual depth, but intermediate reasoning is affected more than final answers. Time to rethink how we design efficient, lean VLMs?
Crucially, once image tokens stabilize, they become largely interchangeable between deeper layers. We show that deep visual processing is often redundant, adding massive computational overhead for very little reward (3/4)
Most model trainings have failed outside of frontier labs.
Even inside frontier labs, knowing how to train for very different capabilities is often a matter of taste.
Today, we introduce AutoScientist by @adaption_ai which sets out to change that.
PageGuide grounds LLM output with visual overlays, addressing unverifiable answers, navigation struggles, and page clutter through Find, Guide, and Hide modes. Check it out!! 🍊🍊
Reading LLM answers but don’t know where they come from?
Struggling to find the right button to click?
Or distracted by cluttered content on the page?
We built PageGuide (https://t.co/WdLKkiZym7) to fix that
🚀 CLINIC is heading to @icmlconf 2026 and it marks the debut of our new lab at ICML! More details soon.
GitHub: https://t.co/3nWvPztGpG
Paper: https://t.co/pPgTtV0ggd
I am honored to speak in the @WHOSEARO Regional Office x @KCDH_A webinar series on the Illusion of Transparency of Frontier Models in Healthcare.
https://t.co/eV0JKH4Yuj
Special shoutout to @EricOnyame and Akash Ghosh for leading this work and thanks to the amazing co-authors Subhadip Baidya, Xiuying Chen (@mbzuai), and Sriparna Saha (@iitpatna).
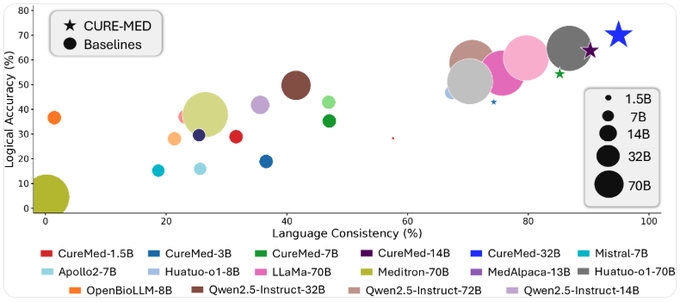
Excited to share CURE-Med, our new work on making LLMs reliable for medical reasoning across the different languages🌍 In healthcare, models can’t just be great in English and then collapse when deployed in new languages. They need to adapt to new tasks (languages, dialects, medical contexts) without catastrophic forgetting of what you already know. We tackle this head-on with curriculum-informed RL.
Datasets and Models on HuggingFace: https://t.co/gT1AZKhBFR
Website: https://t.co/IhdE7SpQFQ
Our scaling results from 1.5B to 32B shows consistent improvements, where Cure-Med outperforms medical LLMs on OOD benchmarks and human evaluations confirm robustness!