Excited to share our preprint on iLTM: an Integrated Large Tabular Model!
arxiv: https://t.co/ZpT5ZiKJs9
No single technique consistently excels across all tabular tasks. iLTM addresses this by integrating distinct paradigms in a single architecture:
- Gradient Boosted Decision Trees (GBDT)-based embeddings
- Robust preprocessing with random feature projections
- A meta-trained hypernetwork
- Retrieval augmentation with Soft Nearest Neighbors
@d_bonet@marcal_cc@alexGioannidis
(1/N)
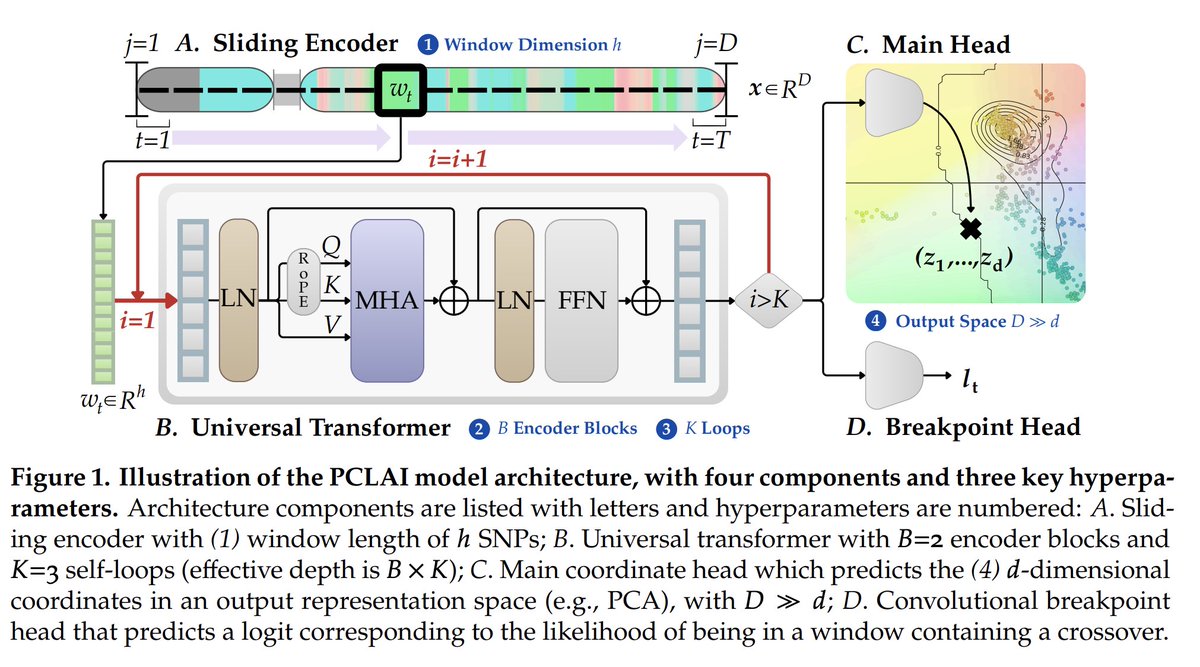
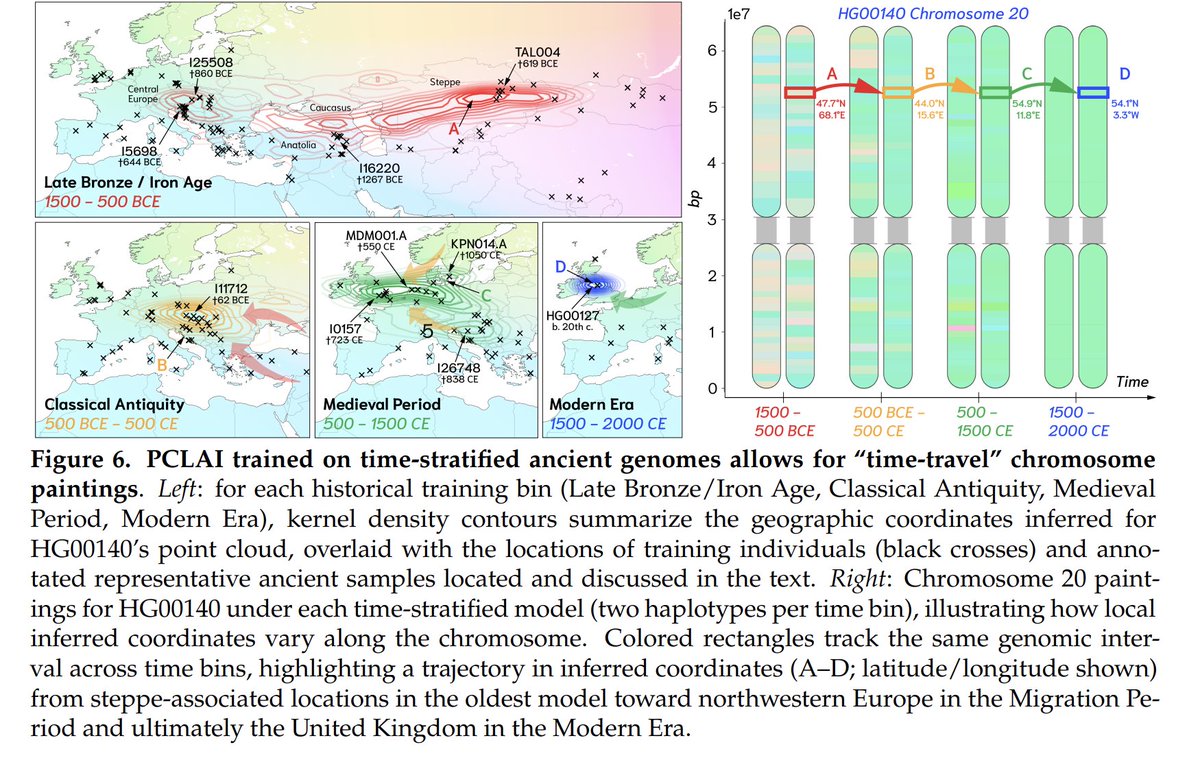
"Point cloud local ancestry inference (PCLAI): continuous coordinate-based ancestry along the genome"
New preprint from @alexGioannidis's group looks super interesting! Deep learning to plot haplotypes into continuous PC spaces. Lots to go over. I need to read it more deeply
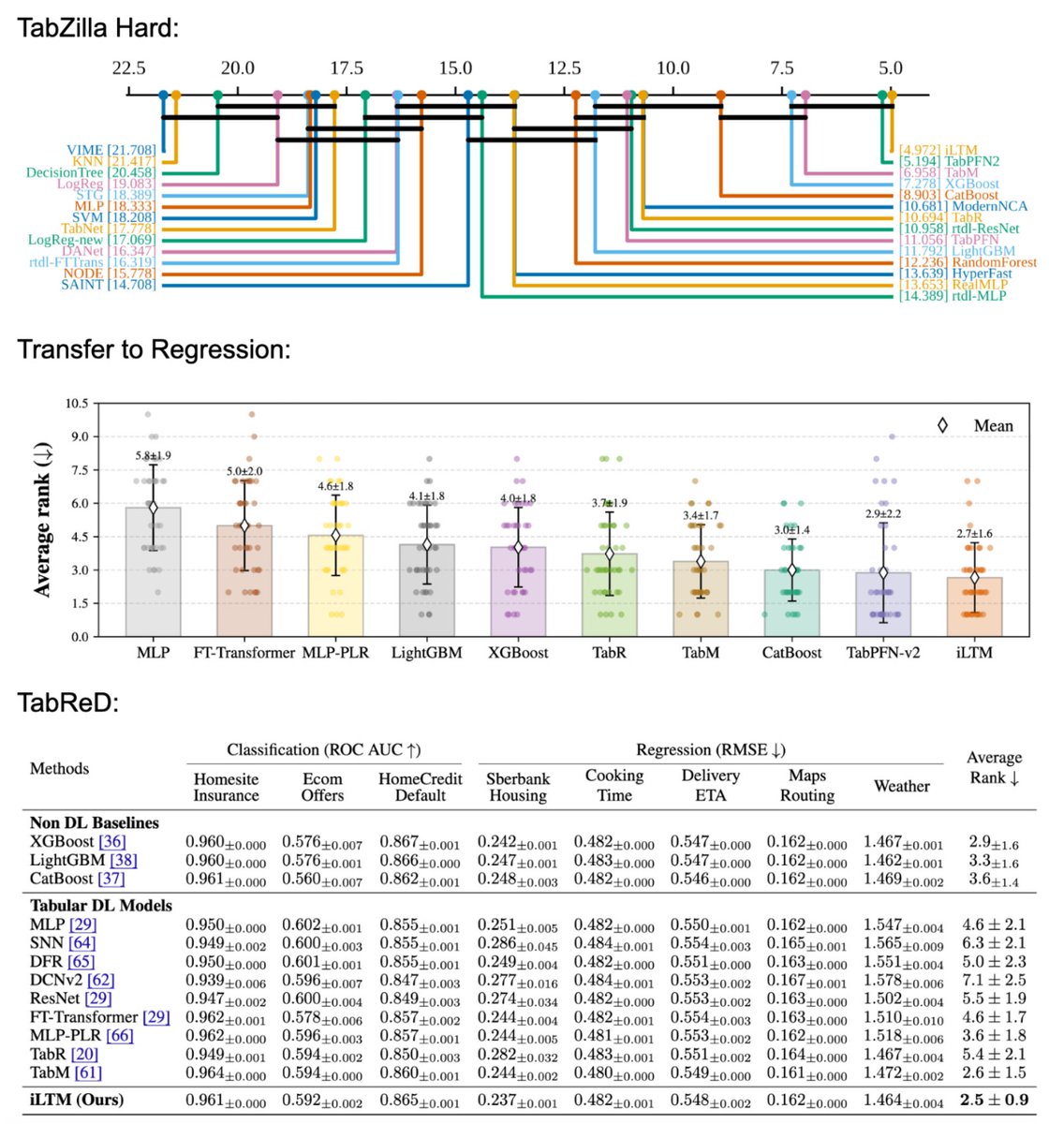
Despite being meta-trained exclusively on classification, iLTM transfers effectively to regression tasks with light fine-tuning, matching or surpassing strong baselines on both tasks.
iLTM achieves top rankings on TabZilla Hard, TabReD, and more benchmarks, outperforming well-tuned XGBoost, CatBoost, and recent deep tabular models.
(3/N)
Excited to share our preprint on iLTM: an Integrated Large Tabular Model!
arxiv: https://t.co/ZpT5ZiKJs9
No single technique consistently excels across all tabular tasks. iLTM addresses this by integrating distinct paradigms in a single architecture:
- Gradient Boosted Decision Trees (GBDT)-based embeddings
- Robust preprocessing with random feature projections
- A meta-trained hypernetwork
- Retrieval augmentation with Soft Nearest Neighbors
@d_bonet@marcal_cc@alexGioannidis
(1/N)
We’re releasing code + pre-trained weights so anyone working with large-scale tabular data can get stronger baselines and build on iLTM.
We’d love feedback and comparisons on your own datasets:
Paper: https://t.co/ZpT5ZiKJs9
Code: https://t.co/8XtKNFfUF5
Weights: https://t.co/EPbRxnJLDx
Excited to share our preprint on iLTM: an Integrated Large Tabular Model!
arxiv: https://t.co/ZpT5ZiKJs9
No single technique consistently excels across all tabular tasks. iLTM addresses this by integrating distinct paradigms in a single architecture:
- Gradient Boosted Decision Trees (GBDT)-based embeddings
- Robust preprocessing with random feature projections
- A meta-trained hypernetwork
- Retrieval augmentation with Soft Nearest Neighbors
@d_bonet@marcal_cc@alexGioannidis
(1/N)
From small tables to real industry-grade datasets with >1M rows and >10k features, our benchmarks show how iLTM scales across sizes.
In our labs at @Stanford and @UCSC, we’re already exploring applications of iLTM to genomic data, where dimensionality is even higher.
(5/N)
How was this paper even accepted to ICLR?
The commercial promoters of TabPFN are now trying to discredit one of the best open repositories, OpenML.
Utterly unacceptable, how did this paper pass ethics board at ICLR?
Excited to share our latest PRS work! Our @GalateaBio and @genomelink team performed a comprehensive analysis of published @PGSCatalog models along with locally trained models using LDPred2, PRS-CSx, and SNPnet, across diverse populations using @UKBIOBANK and our own data
No son of a construction worker is just going to randomly start doing ML research if they never hear of it and don't get told that it could be important for their future career, no matter how intelligent the kid is
Introducing "HyperFast: Instant Classification for Tabular Data" at @RealAAAI, which received the Best Paper Award at @NeurIPSConf Table rep. workshop @TrlWorkshop!
We provide easy-to-use sklearn-like code: https://t.co/qrMF6XStAA
Some insights of the work below 👇🧵(1/N)
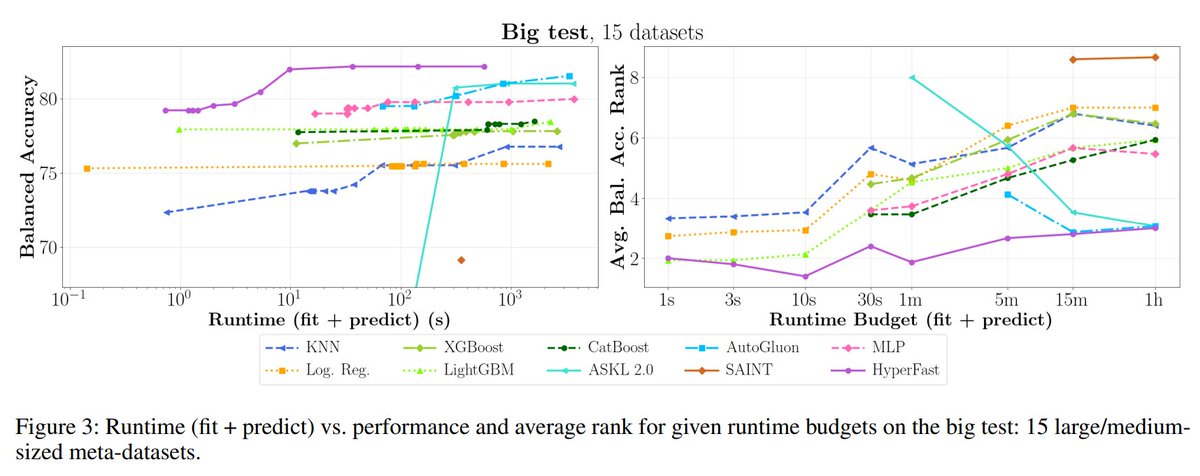
Hyperfast provides competitive results in several tabular classification datasets, even matching boosting-tree-based accuracies!
While still far from solving tabular data classification, we believe Hyperfast provides a step forward in NN-based tabular applications!
(4/N)
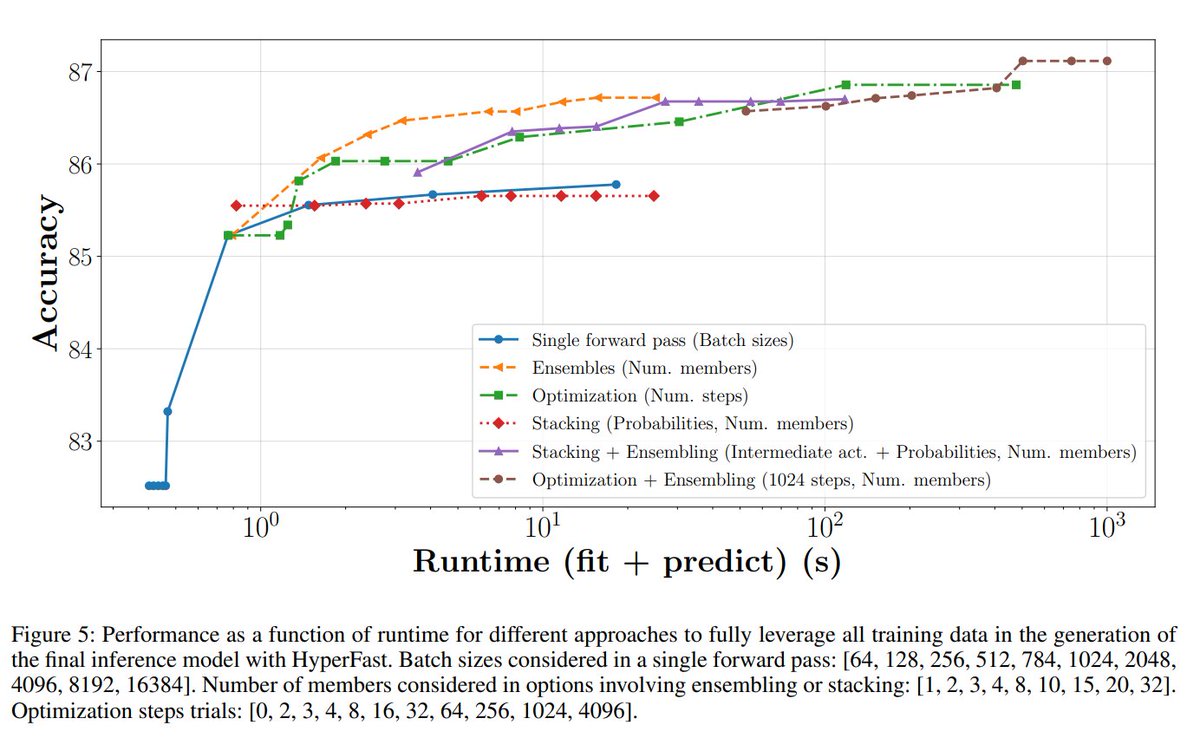
Hyperfast provides multiple mechanisms to scale to both large and high-dimensional datasets and can be easily applied to real-world applications! (3/N)
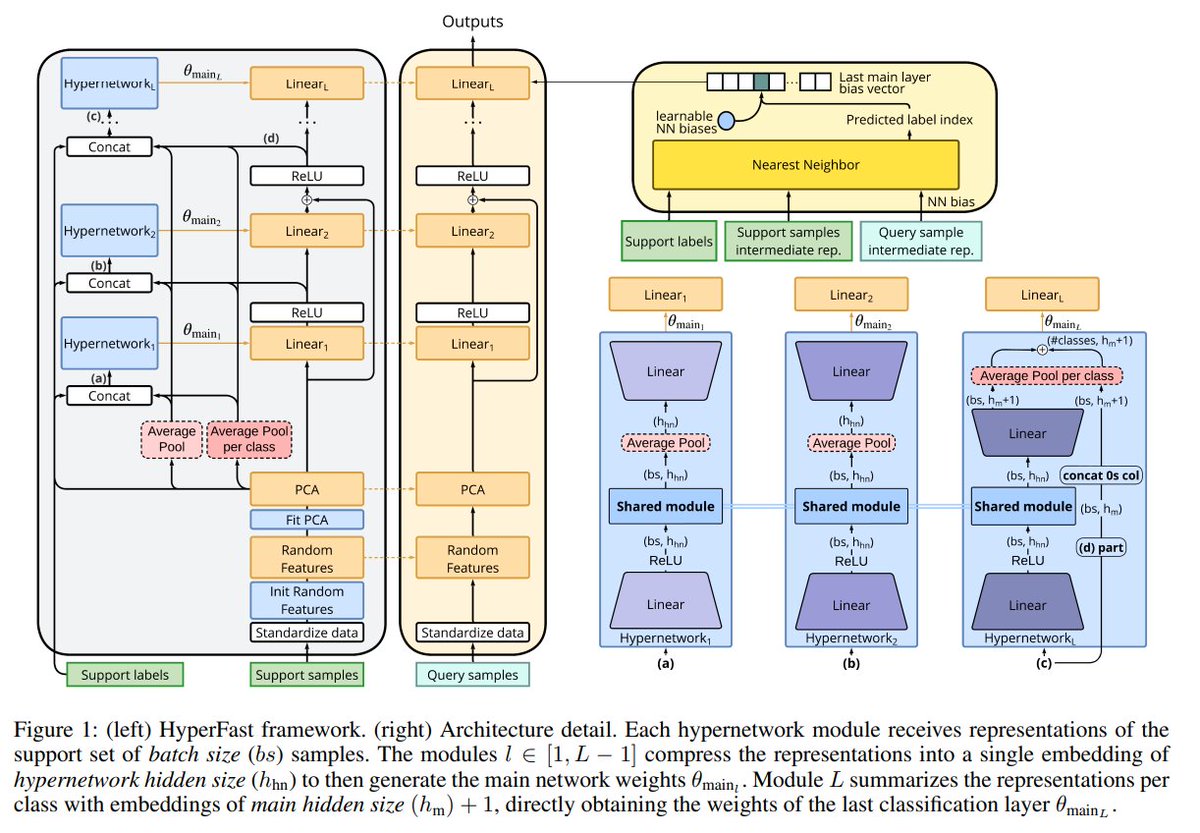
Hyperfast replaces the slow process of training MLPs with gradient-based methods (e.g. Adam) with a fast hypernetwork that directly predicts the weights of the MLP.
The generated MLP typically matches (or even surpasses) the accuracy of those trained with gradient descent. (2/N)
Introducing "HyperFast: Instant Classification for Tabular Data" at @RealAAAI, which received the Best Paper Award at @NeurIPSConf Table rep. workshop @TrlWorkshop!
We provide easy-to-use sklearn-like code: https://t.co/qrMF6XStAA
Some insights of the work below 👇🧵(1/N)
Hyperfast provides competitive results in several tabular classification datasets, even matching boosting-tree-based accuracies!
While still far from solving tabular data classification, we believe Hyperfast provides a step forward in NN-based tabular applications!
(4/N)