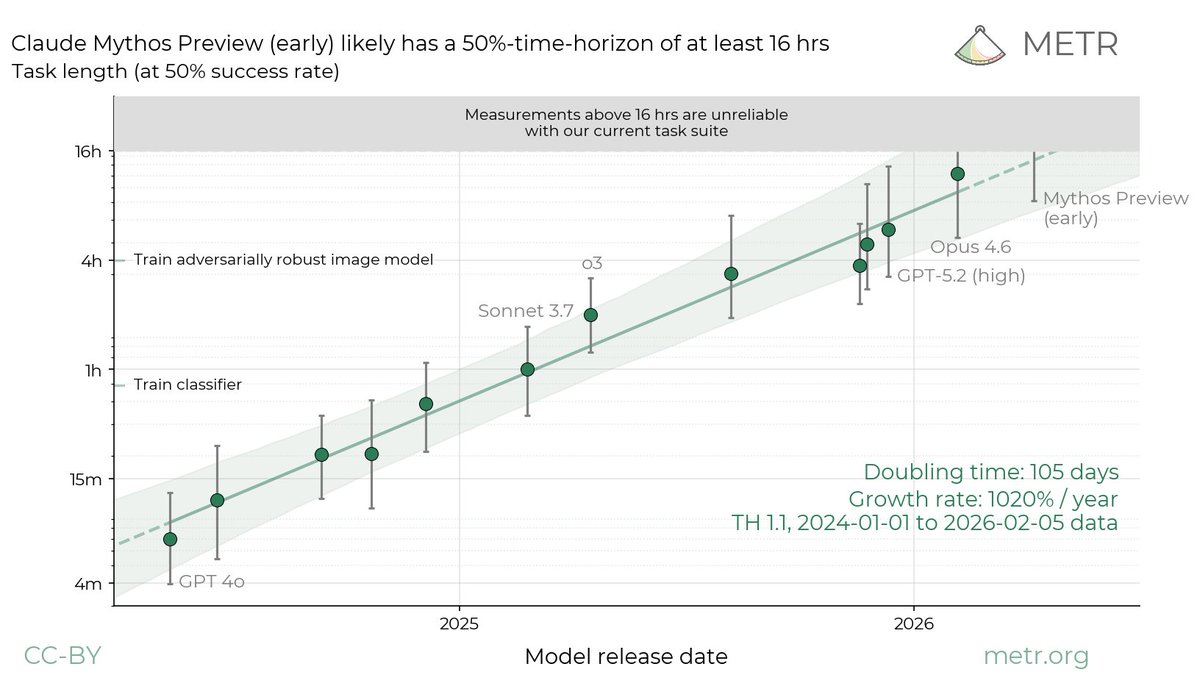
We evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks.
Current sci-fi timeline: Models learn to hide reasoning in RL. Safety observed this. OpenAI publishes. Next training ongoing (sees this).
And…we’re still early!
We recently found some instances of CoT grading during the training of previously deployed models after building a system that scans all OpenAI RL runs for accidental CoT grading.
We did not find clear evidence that these instances degraded CoT monitorability.
🔺NEW: iPhone and iPad are now the first and only generally-available devices to meet the exacting security requirements for handling classified NATO information. https://t.co/sKOHGeqaoD
2026 Apple Security Research Device Application is now live. Apply at https://t.co/JdkPuEiqHh!
* Arbitrary code with arbitrary entitlements
* Arbitrary code injection into existing processes
* Arbitrary SPTM, TXM, KernelCache firmwares
* Downgrades to old builds
* ...and more