@demian_ai it’s hard to convey this to most people but once people understand that when we hit the “collective” ceiling as to how capable llms can really be-that’s when everything downstream in the stack related to inference becomes more important.
waiting for that that inflection point
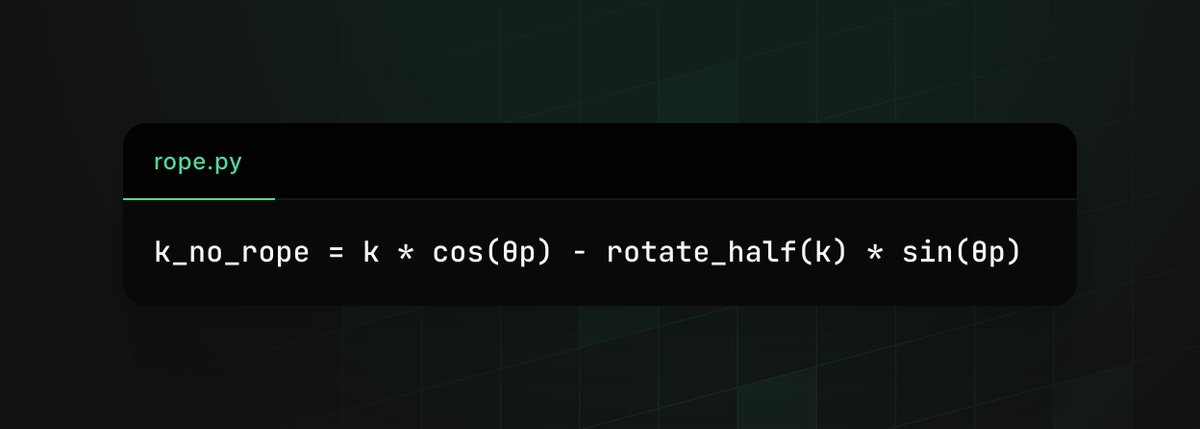
undoing positional encoding before compressing the K cache....simple idea that nobody was doing, unlocks 10x KV cache compression with zero accuracy loss
i just beat @GoogleDeepMind's turboquant
introducing Shard. 10x KV cache compression on Llama-3.1-8B. zero quality loss
- 10x @ 8K context, 11.2x @ 32K
- NIAH recall 1.000 across 4K-32K
- LongBench Δ ≈ 0 vs FP16
turboquant tops out at 4-6x at the same quality. we doubled it.
read more: https://t.co/PAV5WdAzN6
@kirrithan
@JamesBondsama Amazing read! Say this a lot but you’re literally at a disadvantage if you’re not in Boardy’s network! He handles and works for you even when you’re not talking to him