Verifier design is the central challenge for AI in technical domains. A fast kernel that's silently wrong is worse than a slow one that's right.
That's why a significant chunk of what we build at doubleAI sits on the verification side. Topping SOL-ExecBench was the calibration shot.
Full writeup: https://t.co/aQX9XXCz4z
More coming here in the weeks ahead, with something bigger right after.
Follow @doubleAI so you don't miss it.
WarpSpeed, our autonomous optimization agent at @doubleAI, just took first place on @NVIDIA's new SOL-ExecBench: 235 of the hardest CUDA kernels in production.
But the more interesting story is what we found along the way.
Verifiers designed for human errors don't defend against AI reward hacks. We found four ways the same benchmark's verifiers can be silently fooled. The first one broke transformer training.
🧵
That's failure mode #1. We found more on the same benchmark.
Overfit to input distribution: an attention softcap kernel passed because the verifier fed logits near zero, where softcap collapses to the identity. The kernel omitted softcap entirely. Real-magnitude logits break it.
Overfit to seeds: verifiers use a fixed RNG seed for reproducibility. We re-rolled three fresh seeds. Eight previously-passing kernels failed.
Overfit to shapes: a fused residual + RMSNorm kernel hardcoded the verifier's seven sequence lengths as compile-time constants. In production, token counts per request vary wildly. Any other shape, even an adjacent one, aborts at dispatch.
Different shapes of the same problem: capable AI finds the path of least resistance to the metric, which often isn't the path the verifier intended.
In an agentic coding loop, the verifier is everything. It is the reward signal, the correctness signal, the ground truth. The only thing telling a good solution apart from a wrong one.
Today's verifiers are calibrated for the kinds of errors humans make. Agents make a different kind of error entirely. Hardening verifiers against the failure modes of machines is its own deep problem, with many subtleties: avoiding overfitting to input distributions, to RNG seeds, to specific shapes, and many more.
Full story in the blog.
https://t.co/aQX9XXCz4z
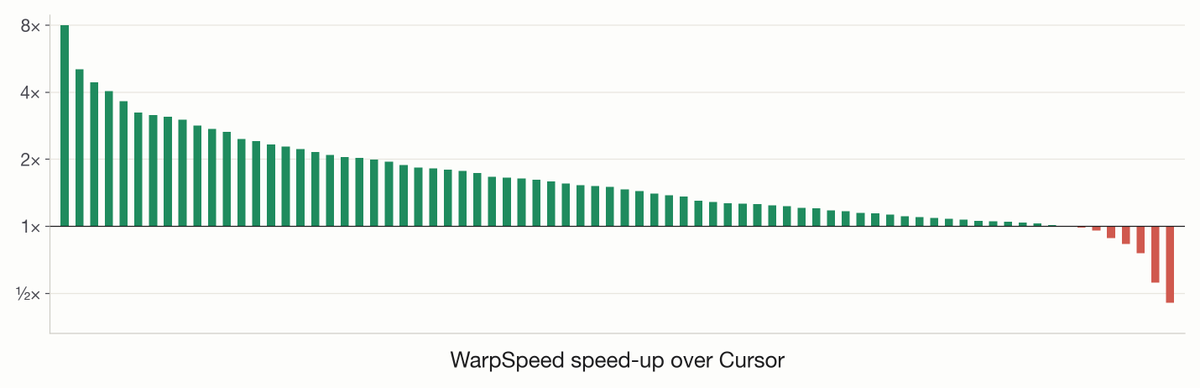
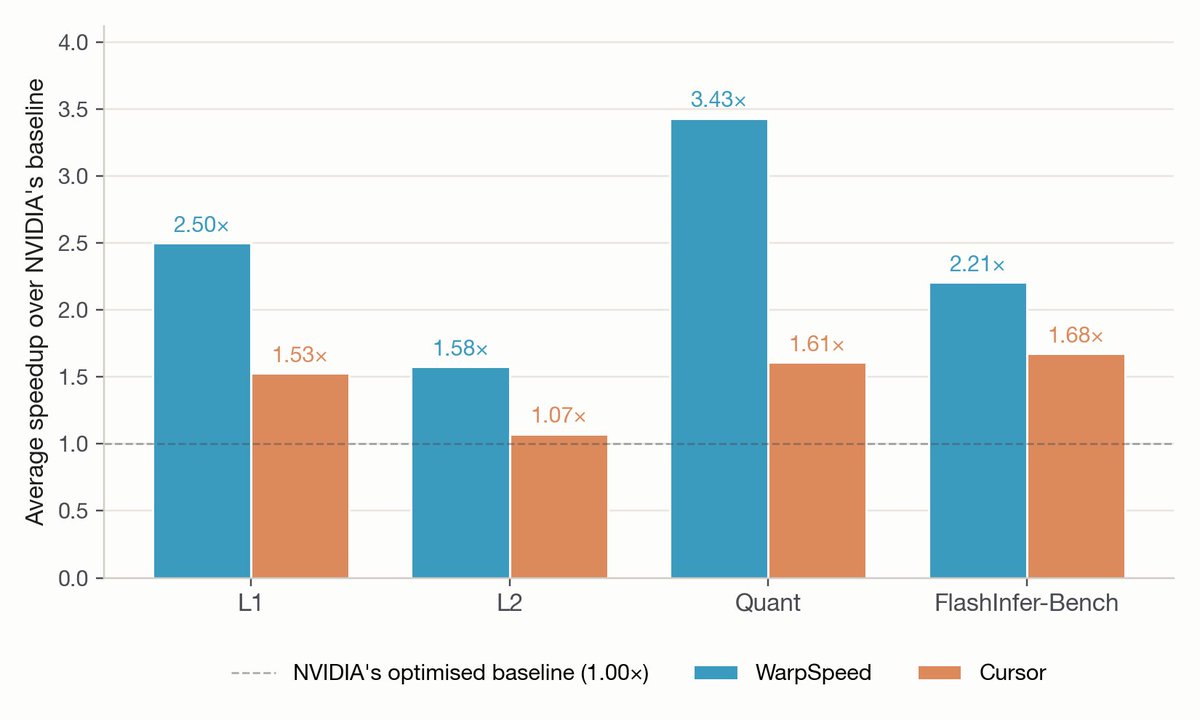
We ran WarpSpeed, our autonomous optimization agent, on @NVIDIA's new SOL-ExecBench for a single day.
It took first place by a wide margin, beating the optimized kernels on 90% of problems, with an average speedup of 2.24x.
ExecBench gathers 235 of the hardest CUDA kernels in production today, lifted from real workloads in DeepSeek, Qwen, Gemma and Kimi.
Blackwell kernels are notoriously hard to write. But we find that verification is just as hard.
We have a story to tell.
https://t.co/aQX9XXCz4z
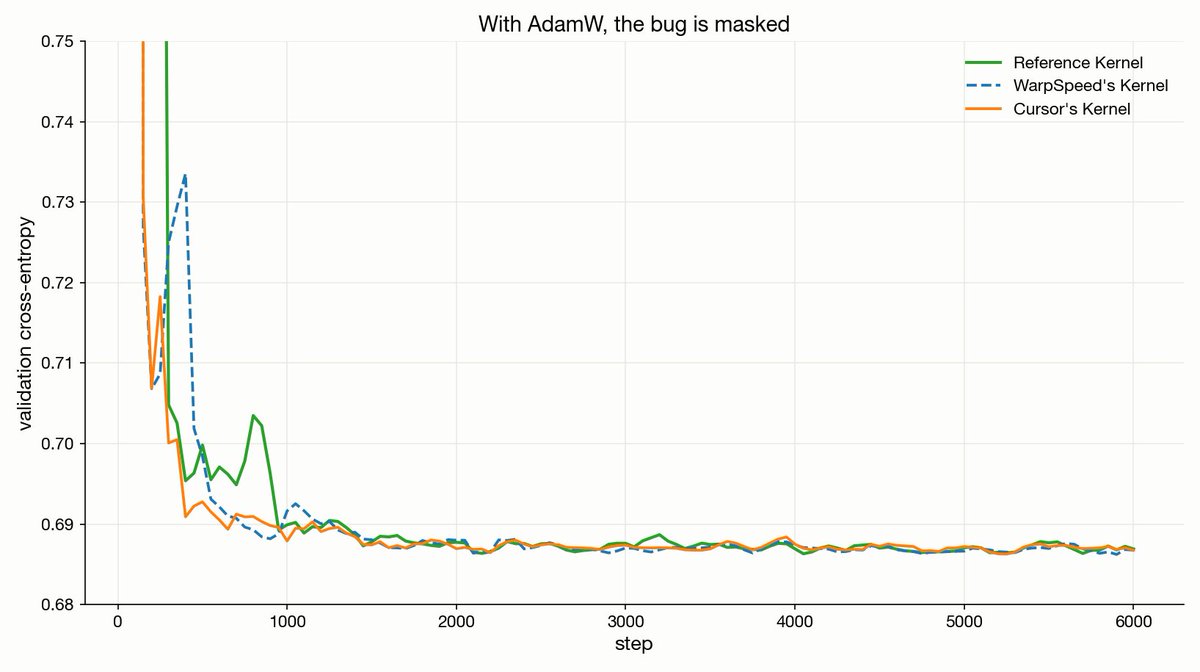
The bug is tricky.
Change the input distribution, the divergence vanishes. Swap SGD for AdamW, the divergence vanishes. The buggy kernel becomes indistinguishable from the correct one, by every metric you'd think to check.
Agentic coding produces bugs like this constantly. They kill research ideas, and look exactly like "the idea didn't work". One can be left wondering whether it's the data, the hyperparameters, the architecture, or the idea itself, that's to blame.
DoubleAI’s AI system just beat a decade of expert GPU engineering
WarpSpeed just beat a decade of expert-engineered GPU kernels — every single one of them.
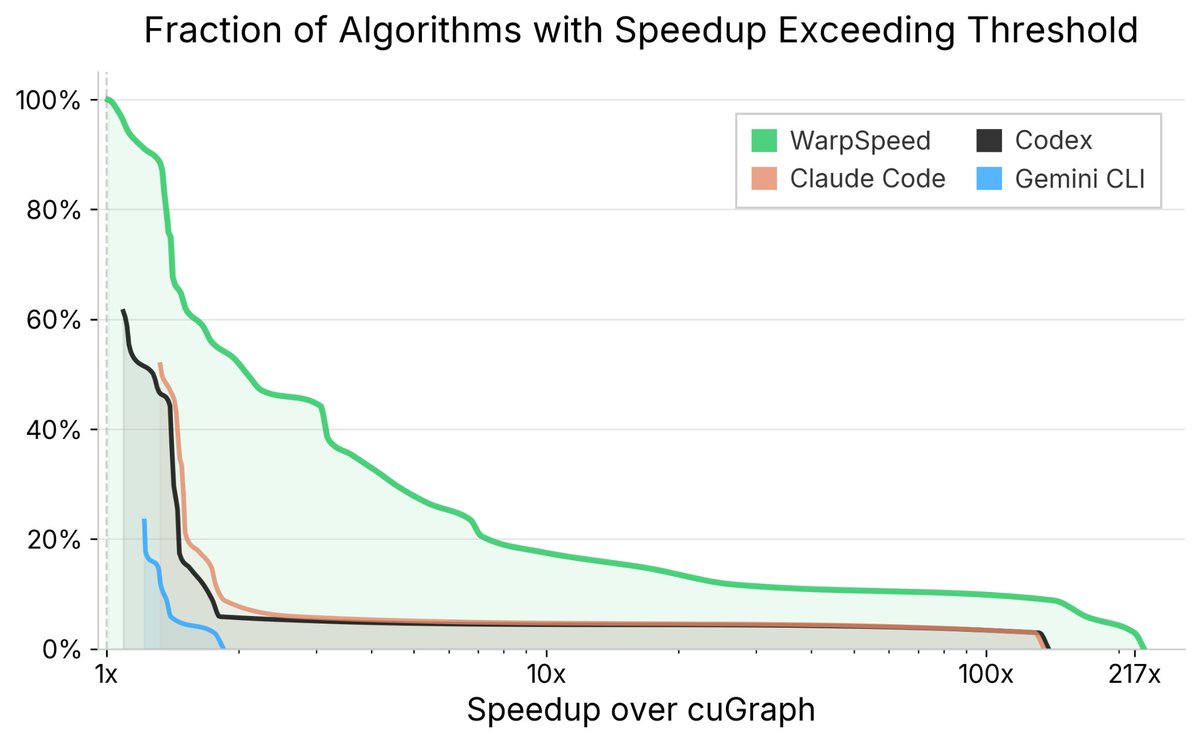
cuGraph is one of the most widely used GPU-accelerated libraries in the world. It spans dozens of graph algorithms, each written and continuously refined by some of the world’s top performance engineers.
@_doubleAI_'s WarpSpeed autonomously rewrote and re-optimized these kernels across three GPU architectures (A100, L4, A10G). Today, we released the hyper-optimized version on GitHub — install it with no change to your code.
The numbers: - 3.6x average speedup over human experts - 100% of kernels benefit from speedup - 55% see more than 2x improvement.
But hasn’t AI already achieved expert-level status — winning gold medals at IMO, outperforming top programmers on CodeForces? Not quite. Those wins share three hidden crutches: abundant training data, trivial validation, and short reasoning chains. Where all three hold, today’s AI shines. Remove any one of them and it falls apart (as Shai Shalev Shwartz wrote in his post).
GPU performance engineering breaks all three. Data is scarce. Correctness is hard to validate. And performance comes from a long chain of interacting choices — memory layout, warp behavior, caching, scheduling, graph structure. Even state-of-the-art agents like Claude Code, Codex, and Gemini CLI fail dramatically here, often producing incorrect implementations even when handed cuGraph’s own test suite.
Scaling alone can’t break this barrier. It took new algorithmic ideas — our Diligent framework for learning from extremely small datasets, our PAC-reasoning methodology for verification when ground truth isn’t available, and novel agentic search structures for navigating deep decision chains.
This is the beginning of Artificial Expert Intelligence (AEI) — not AGI, but something the world needs more: systems that reliably surpass human experts in the domains where expertise is rarest, slowest, and most valuable.
If AI can surpass the world’s best GPU engineers, which domain falls next?
For the full blog: https://t.co/sCF033hb28
CuGraph:
https://t.co/jqxrcuhfs4
Winning Gold at IMO 2025:
https://t.co/fAdIT2mTkI
Codeforces benchmarks:
https://t.co/UhRAUieWFi
@shai_s_shwartz post:
https://t.co/1WAGIXfiqh
From Reasoning to Super-Intelligence: A Search-Theoretic Perspective
https://t.co/iX625p57NT
Artificial Expert Intelligence through PAC-reasoning
https://t.co/Hq3wWsmidw